
最近维护了几个 Go 后台系统,涉及到几种长连接 websocket 读写并发模型,简单回顾和归纳一下:
- 单读协程 + 加锁直写:每连接 1 个 goroutine,写通过锁串行化。
- 读写双协程 + channel:每连接 2 个 goroutine,写收敛到单协程,天然带背压。
- 事件驱动(gnet / reactor):没有 “每连接协程”,少量 event-loop 用 epoll 管全部连接。
1. 概述
三种模型的差异关键点:每个连接到底要占多少个 goroutine,写并发安全由谁来保证。
| 序号 | 模型 | 每连接 goroutine | 读 | 写 | 背压 |
|---|---|---|---|---|---|
| 1 | 单读 + 加锁 | 1(读) | 阻塞 Read | 加锁直写 | 无 |
| 2 | 双协程 + channel | 2(读 + 写) | 阻塞 Read | 单写协程消费 channel | 有 |
| 3 | 事件驱动 gnet | ≈ 0(共享 event-loop) | epoll 回调 | 异步入队 | 有 |
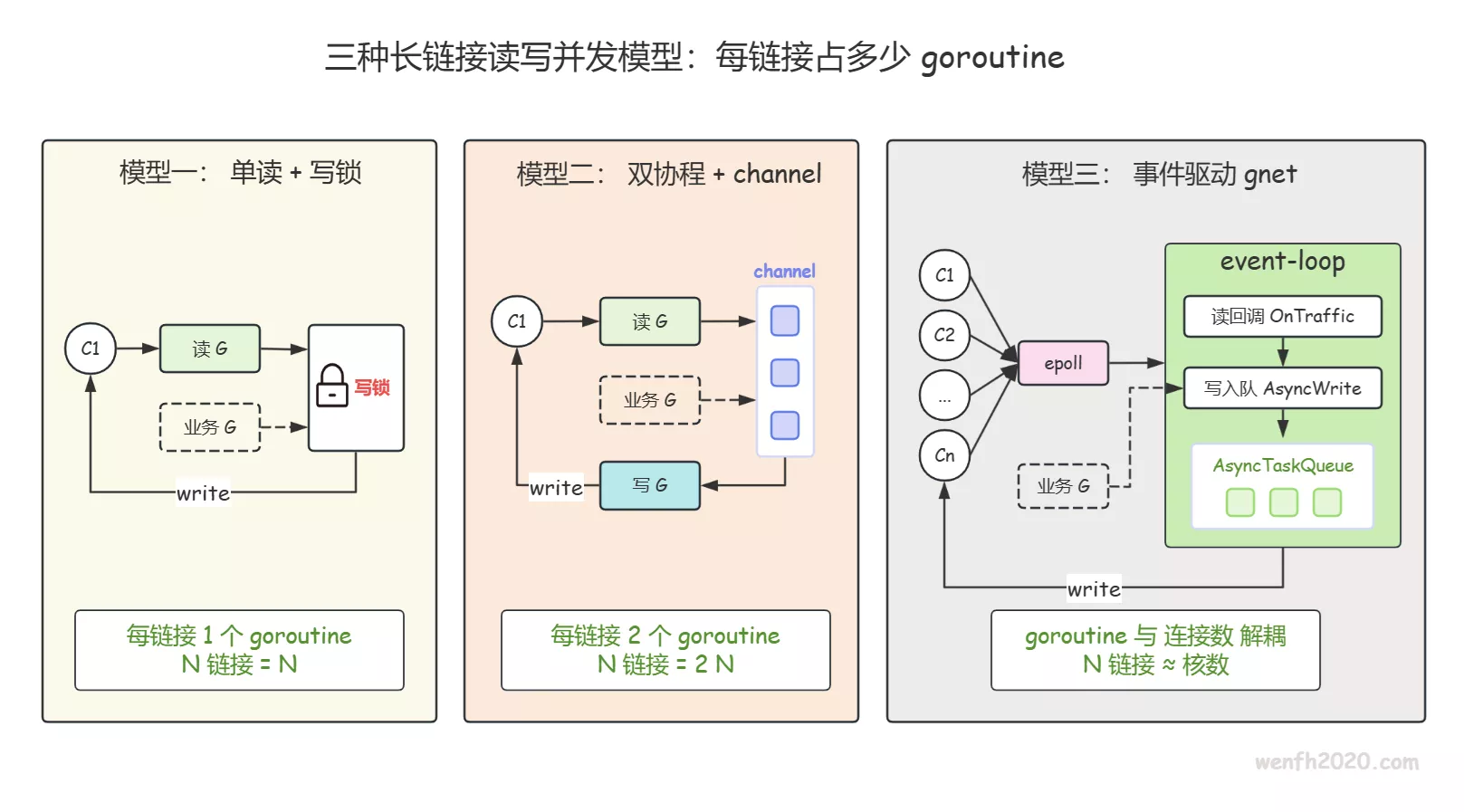
为什么会演化出这几种?根子在于 Read 是阻塞调用——你必须有 “人” 守着它。守着它的可以是:
- 一个专属 goroutine(模型一、二);
- 也可以是 epoll,由内核告诉你 “哪个 fd 可读了”,再回调处理(模型三)。
2. 模型
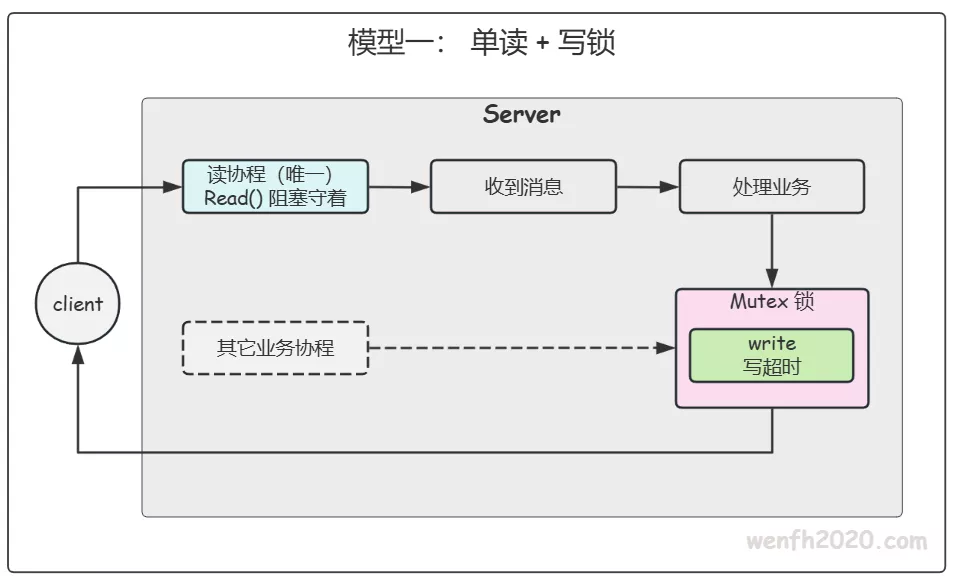
2.1. 单读协程 + 加锁直写
每个连接只起 1 个 goroutine 守着读循环。写没有专属协程——任何业务 goroutine(推送、心跳回包)拿到连接就直接写,靠每连接一把 sync.Mutex 锁保证同一连接同一时刻只有一个 writer。
- 优点:
- 实现最简单;每连接只占 1 个 goroutine,省内存、省调度。
- 写延迟最低(没有中转)。
- 缺点:
- 写阻塞会被锁放大 —— 临界区里包着可能阻塞的 Write,一旦某个客户端”假死”导致内核发送缓冲区写满,持锁协程就卡住,其它要给同一连接写的协程全堵在
Lock()上。所以这种模型里,写超时(SetWriteDeadline)是必须的,否则一个慢客户端能拖死发往它的整条写链路。
- 写阻塞会被锁放大 —— 临界区里包着可能阻塞的 Write,一旦某个客户端”假死”导致内核发送缓冲区写满,持锁协程就卡住,其它要给同一连接写的协程全堵在
详细 demo 请参考:model1_lock/main.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
type Conn struct {
ws *websocket.Conn
mu sync.Mutex // 每连接一把写锁
}
// 任意 goroutine 都能调用,靠锁保证同一连接不并发写
func (c *Conn) Write(data []byte) error {
c.mu.Lock()
defer c.mu.Unlock()
c.ws.SetWriteDeadline(time.Now().Add(5 * time.Second))
return c.ws.WriteMessage(websocket.TextMessage, data)
}
// 单读协程读 goroutine
func (c *Conn) readLoop() {
for {
_, msg, err := c.ws.ReadMessage()
if err != nil {
return
}
c.handleMessage(msg)
}
}
func (c *Conn) handleMessage(msg []byte) {
if string(msg) == "ping" {
c.Write([]byte("pong"))
}
}
func (c *Conn) serve() {
go c.readLoop()
// 与 readLoop 的 pong 并发写
for i := 0; i < 3; i++ {
go func(id int) {
c.Write([]byte(fmt.Sprintf("push from %d", id)))
}(i)
}
}
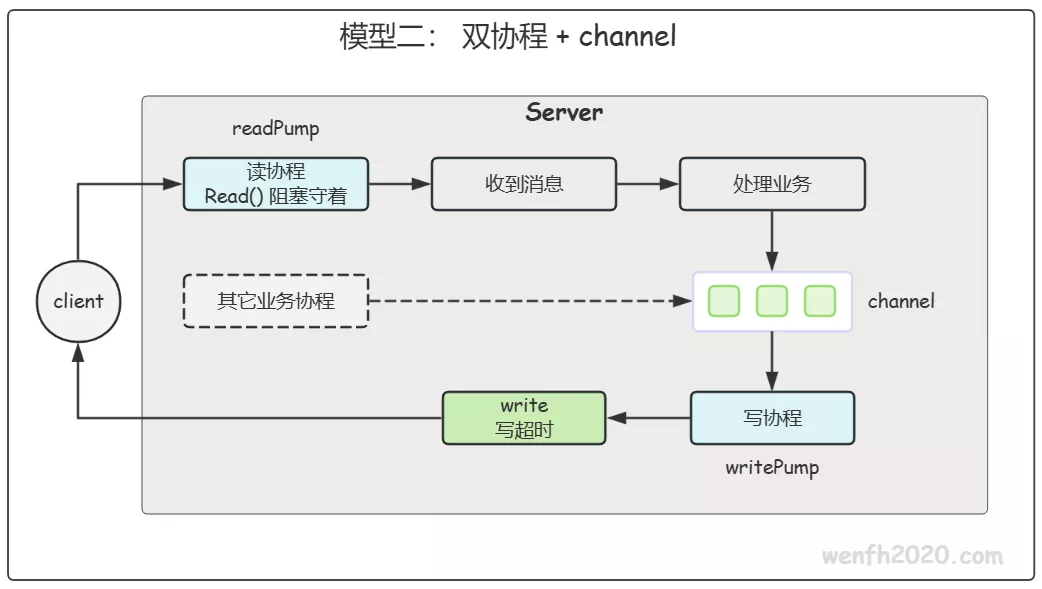
2.2. 读写双协程 + channel
每个连接起 2 个 goroutine —— readPump 只读、writePump 只写。所有要发的消息先进一个带缓冲的 channel,由唯一的 writePump 取出来写。
写收敛到一个协程,自然就 “无锁” 了;channel 带缓冲,也就自然有了 背压。
- 优点:
- 写无锁。
- 业务协程投递即返回,写阻塞只卡 writePump 自己,不卡业务。
- 慢客户端被隔离在自己的队列里,撑满就被踢,不经锁放大。
- 缺点:
- 每连接 2 个 goroutine,海量连接时内存和调度开销翻倍。
- 消息多一跳 channel 的延迟。
详细 demo 请参考:model2_channel/main.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
type Conn struct {
ws *websocket.Conn
send chan []byte // 带缓冲发送队列,所有要发的消息先进这里
done chan struct{} // 关闭信号:广播"这条连接要收摊了"
closeOnce sync.Once // 保证 done 只关一次
}
// 关闭只关 done、永不关 send:任何 goroutine 的 Push 都不会
// "向已关闭 channel 发送"而 panic。sync.Once 保证幂等。
func (c *Conn) close() {
c.closeOnce.Do(func() { close(c.done) })
}
// 非阻塞投递;满了 = 客户端太慢 -> 踢掉(背压),返回是否投递成功
func (c *Conn) Push(data []byte) bool {
select {
case c.send <- data: // 有缓冲位,投递成功
return true
case <-c.done: // 已关闭,别再投
return false
default: // 队列满 = 慢客户端,踢掉,不拖累别人
c.close()
return false
}
}
// 读协程:只读,把要回的内容丢进队列,不直接写
func (c *Conn) readPump() {
defer c.close() // 读出错/对端关闭 -> 通知 writePump 退出
for {
_, msg, err := c.ws.ReadMessage()
if err != nil {
return
}
c.handleMessage(msg)
}
}
// 处理一条业务消息:解析 + 决定回什么。读协程只「投递」、从不直接写 ws,
// 回包统一走 Push 进 send 队列,由唯一的 writePump 串行落地,保持单 writer 无锁。
func (c *Conn) handleMessage(msg []byte) {
if string(msg) == "ping" {
c.Push([]byte("pong"))
}
}
// 写协程:本连接唯一 writer,无需锁;顺带统一管心跳和写超时
func (c *Conn) writePump() {
tick := time.NewTicker(30 * time.Second)
defer func() {
tick.Stop()
c.ws.Close()
}()
for {
select {
case data := <-c.send:
c.ws.SetWriteDeadline(time.Now().Add(5 * time.Second))
if c.ws.WriteMessage(websocket.TextMessage, data) != nil {
return
}
case <-tick.C:
if c.ws.WriteMessage(websocket.PingMessage, nil) != nil {
return
}
case <-c.done:
c.drain() // 退出前把队列残余尽量发完,不丢已投递的数据
return
}
}
}
// 连接关闭后,非阻塞地把 send 队列残余消息发完再退出。
// send 永不被 close,故用 select-default 取到就写、取空即返回。
func (c *Conn) drain() {
for {
select {
case data := <-c.send:
c.ws.SetWriteDeadline(time.Now().Add(5 * time.Second))
if c.ws.WriteMessage(websocket.TextMessage, data) != nil {
return
}
default:
return
}
}
}
模型一和模型二,是同一道题的两种解法:都要保证 “同一连接不并发写”,一个用 锁,一个用 单写协程。代价分别是 “锁竞争 + 阻塞放大” 和 “单写协程多一个协程 + 一跳延迟”。
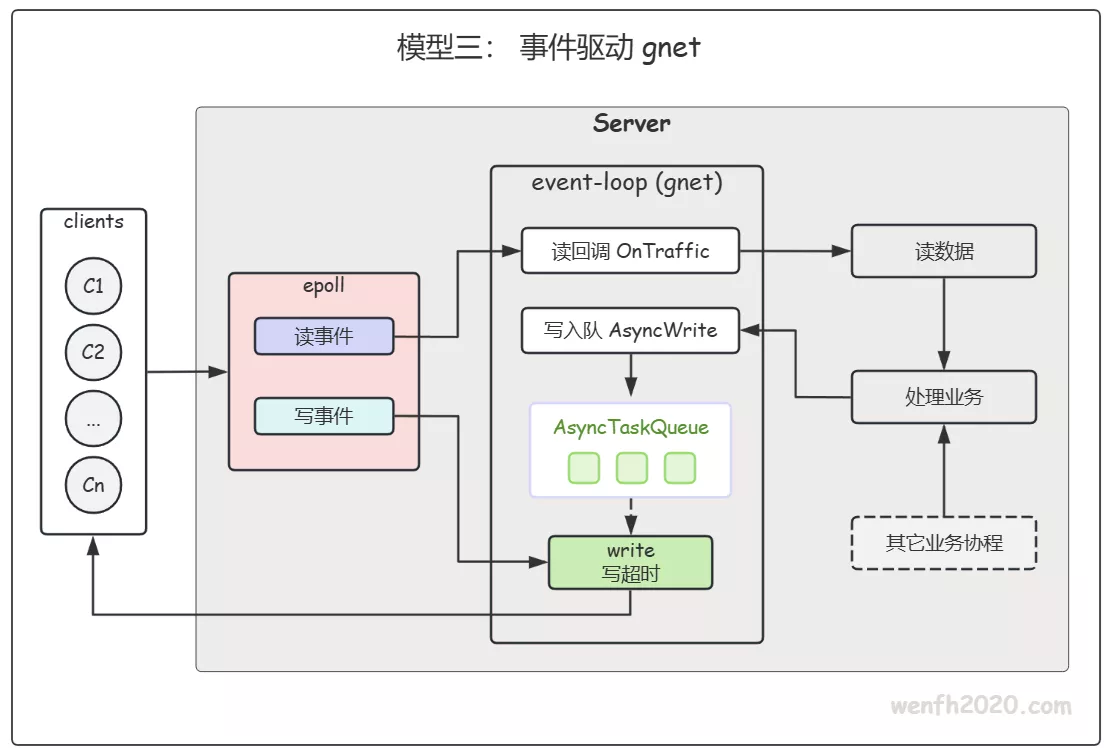
2.3. 事件驱动(gnet / reactor)
前两种模型都绕不开一件事:Read 阻塞,所以每连接至少要钉一个 goroutine 守着它。连接一多,goroutine 数量就跟着连接数线性涨——百万连接 × 2 = 两百万 goroutine,调度、内存、GC 栈扫描都会吃不消。
reactor 模型(gnet)换了个思路:不再让 goroutine 去 “等” 可读,而是把所有 fd 挂到 epoll 上,由内核告诉你 “哪个连接可读了”,再回调处理。这样守连接的不再是 “每连接一个协程”,而是少量 event-loop 协程(一般 ≈ CPU 核数)。这正是 epoll 的用武之地。
- 优点:
- goroutine 数量和连接数解耦,百万连接也只有 ≈ 核数个 event-loop,内存和调度开销极低。
- 框架内部还有 ring buffer、内存池等优化,GC 压力小。
- 缺点:
- 编程模型最复杂——回调式、要手动粘包拆包、要自己维护协议状态机。
Next/Peek的切片回调返回后会被复用,传给新协程前必须 copy。- OnTraffic 里最好不要做阻塞操作(查库、调外部接口),否则会卡住该 event-loop 上的所有连接。
gnet 框架对 epoll 异步事件驱动的封装:
| 回调 | 触发时机 | 典型职责 |
|---|---|---|
| OnBoot | 服务启动一次 | 保存 engine、打日志 |
| OnOpen | 新连接建立 | 建连接上下文、注册进连接管理器 |
| OnTraffic | socket 可读(epoll) | 拆包、处理、回包 |
| OnClose | 连接断开 | 注销、清理缓存、收尾 |
| OnTick | 定时器周期触发 | 心跳超时检查、统计上报等 |
- 读,是 epoll 就绪后由 event-loop 协程回调
OnTraffic。 - 写,是业务调用
c.AsyncWrite把数据异步丢进 gnet 内部写队列,框架内部保证并发安全、无需加锁。 - 关键点:每条连接的状态挂在 gnet.Conn 自己的 context 上,用 c.SetContext / c.Context() 存取。因为同一连接的所有回调都跑在同一个 event-loop 协程里、彼此串行,所以读写这个 context 天然不需要加锁(当然你的逻辑如果要进行协程并发,那就是另外一种场景了)。
详细 demo 请参考:model3_gnet/main.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
// 每连接的上下文,挂在 gnet.Conn 上
type ConnContext struct {
ConnId string
ClientID string
Addr string
StartTime time.Time
IsConnOpen bool
}
type Server struct {
gnet.BuiltinEventEngine
eng gnet.Engine
}
// 新连接:建上下文 + 注册进连接管理器
func (s *Server) OnOpen(c gnet.Conn) (out []byte, action gnet.Action) {
ctx := &ConnContext{
ConnId: genUUID(),
Addr: c.RemoteAddr().String(),
StartTime: time.Now(),
IsConnOpen: true,
}
c.SetContext(ctx) // 状态挂到连接上
clientMgr.Add(ctx.ConnId, c) // 注册,后面推送靠它找到 c
return nil, gnet.None
}
// 可读:拆包 -> 处理 -> 回包,全程不阻塞
func (s *Server) OnTraffic(c gnet.Conn) gnet.Action {
ctx, ok := c.Context().(*ConnContext)
if !ok || !ctx.IsConnOpen {
return gnet.Close
}
packet, err := readFullPacket(c) // 自己粘包拆包,凑不齐一个整包就返回
if err != nil {
return gnet.Close
}
if packet == nil {
return gnet.None // 半个包,等下次 OnTraffic
}
rsp := s.process(ctx, packet) // 业务处理(注意:别在这里阻塞!)
c.AsyncWrite(rsp, nil) // 异步回包,框架保证并发安全
return gnet.None
}
// 断开:注销 + 清理,状态从 context 里捞
func (s *Server) OnClose(c gnet.Conn, err error) gnet.Action {
ctx, ok := c.Context().(*ConnContext)
if ok && ctx != nil {
ctx.IsConnOpen = false
clientMgr.Remove(ctx.ConnId) // 先注销,别让推送再找到它
c.SetContext(nil)
}
return gnet.Close
}
为什么模型三要 “手动拆包”,模型一、二却不用?差别在于工作的抽象层次不同:
- 模型一、二用的是 gorilla/websocket 的 ReadMessage(),返回的直接是一条完整消息 ——WebSocket 协议自带帧头(含长度),库已经在内部替你读帧头、收满、拼好,你感知不到 “包” 的存在。
- 模型三的 gnet 是通用 TCP reactor,工作在裸字节流这一层。OnTraffic 触发时,只是内核说 “这个 fd 有数据可读了”,交给你的是 socket 缓冲区里此刻恰好到达的字节:可能是半个包、正好一个包,也可能是粘在一起的一个半、两个包。因为 TCP 只保证字节顺序,不保证 “一次读 = 一个应用消息”。
所以 OnTraffic 里必须自己:读长度字段 → 判断够不够一个整包 → 不够就攒着等下次 → 够了才切出来处理(demo 代码里的 readFullPacket 就是干这事)。
不是 “事件驱动” 本身要求手动拆包,而是模型三下沉到了 TCP 字节流层,丢掉了 WebSocket 库自带的帧边界 ——抽象层次降低换来性能(少一层封装、ring buffer、内存池),代价就是得自己把 “字节流 → 消息” 这段重新做一遍。
反面案例:
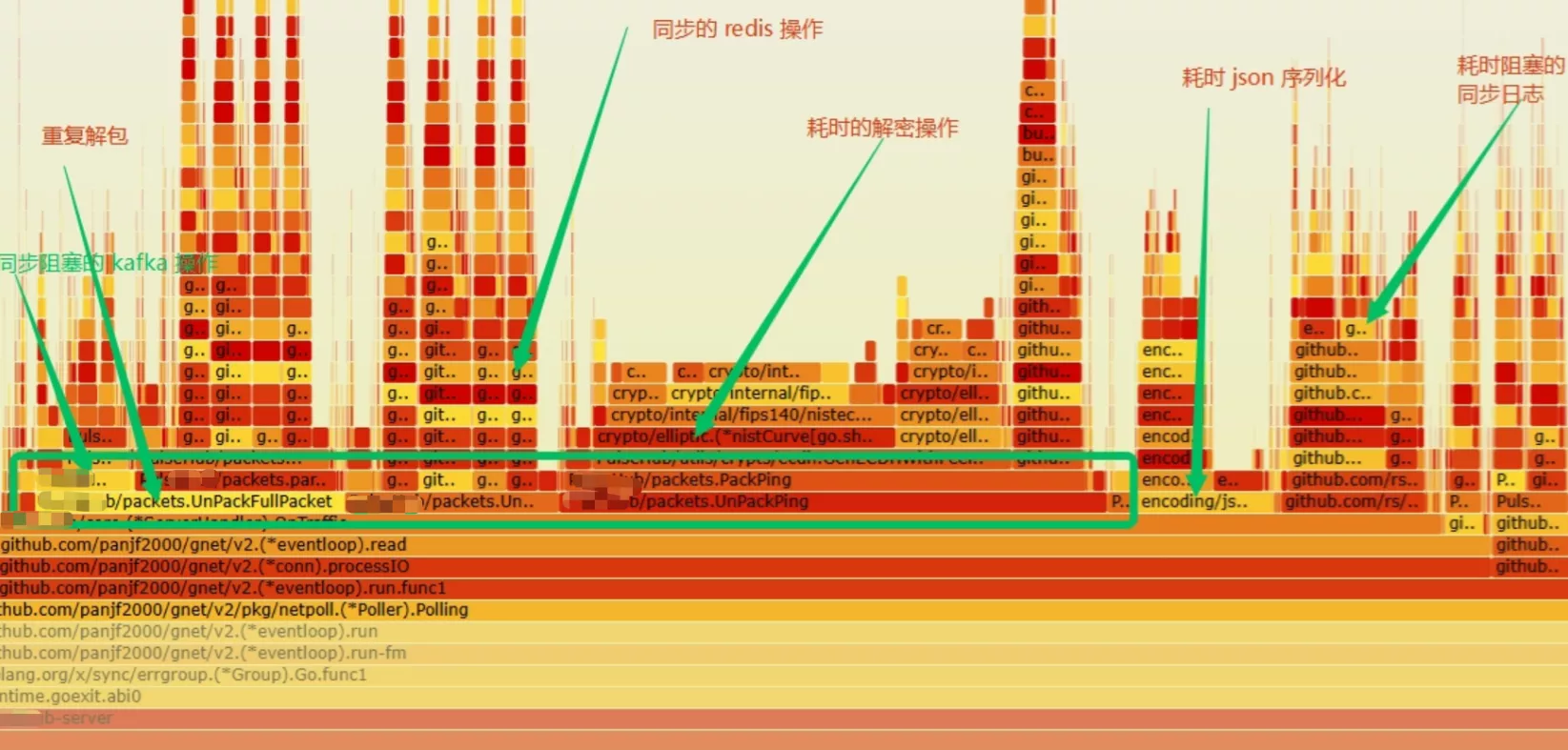
OnTraffic 里不要阻塞,否则会卡住该 event-loop 上的所有连接。
下面这个火焰图形象展示了在复杂的业务逻辑下,服务端虽然使用了高效的 gnet 框架,服务端却阻塞严重。
3. 对比与选型
通过模型对比进行选型:
- 先看连接量级:几千到几万,连接数撑不爆 goroutine,模型一足够,写超时记得加。
- 再看要不要背压:推送量大、要隔离慢客户端、要稳定的尾延迟,上模型二。
- 量级到了 goroutine 本身成为瓶颈(十万、百万长连接),才值得为模型三付出 “回调式编程 + 手动拆包” 的复杂度。
| 维度 | 单读 + 加锁 | 双协程 + channel | 事件驱动 gnet |
|---|---|---|---|
| 每连接 goroutine | 1 | 2 | ≈ 0(共享 event-loop) |
| 读 | 阻塞 Read | 阻塞 Read | epoll 回调 |
| 写 | 加锁直写 | 单写协程消费 channel | 异步入队 |
| 写并发安全 | 每连接锁 | 单写协程天然串行 | 框架保证 |
| 背压 / 慢客户端隔离 | 无 / 差 | 有 / 好 | 有 / 好 |
| 内存开销 | 低 | 中 | 极低 |
| 适用规模 | 中小 | 中大 | 超大(C100K+) |
| 编程复杂度 | 低 | 中 | 高 |
4. 小结
- 长连接读写并发模型的本质区别是:每连接占多少 goroutine,写并发安全由谁保证。
- 三种解法依次是:锁、单写协程、框架内部队列;从模型一到模型三,每连接 goroutine 数递减(1 → 2 → ≈ 0),背压能力和编程复杂度递增。
- Read 阻塞是绕不开的约束:要么用一个 goroutine 钉着它,要么交给 epoll 回调。后者就是 reactor,也是 gnet 去掉 “每连接协程” 的根本原因。
- 没有最好的模型,只有匹配规模的模型。先按连接量级选,再按背压需求选,量级到瓶颈才上事件驱动。