
走读 Linux(5.0.1)源码,理解 TCP 网络数据接收和读取工作流程(NAPI)。
要搞清楚数据的接收和读取流程,需要梳理这几个角色之间的关系:网卡(本文:e1000),主存,CPU,网卡驱动,内核,应用程序。
1. 简述
简述数据接收处理流程。
- 网卡(NIC)接收数据。
- 网卡通过 DMA 方式将接收到的数据写入主存。
- 网卡通过硬中断通知 CPU 处理主存上的数据。
- 网卡驱动(NIC driver)启用软中断,消费主存上的数据。
- 内核(TCP/IP)协议层处理数据,将数据缓存到对应的 socket 上。
- 应用程序读取对应 socket 上已接收的数据。
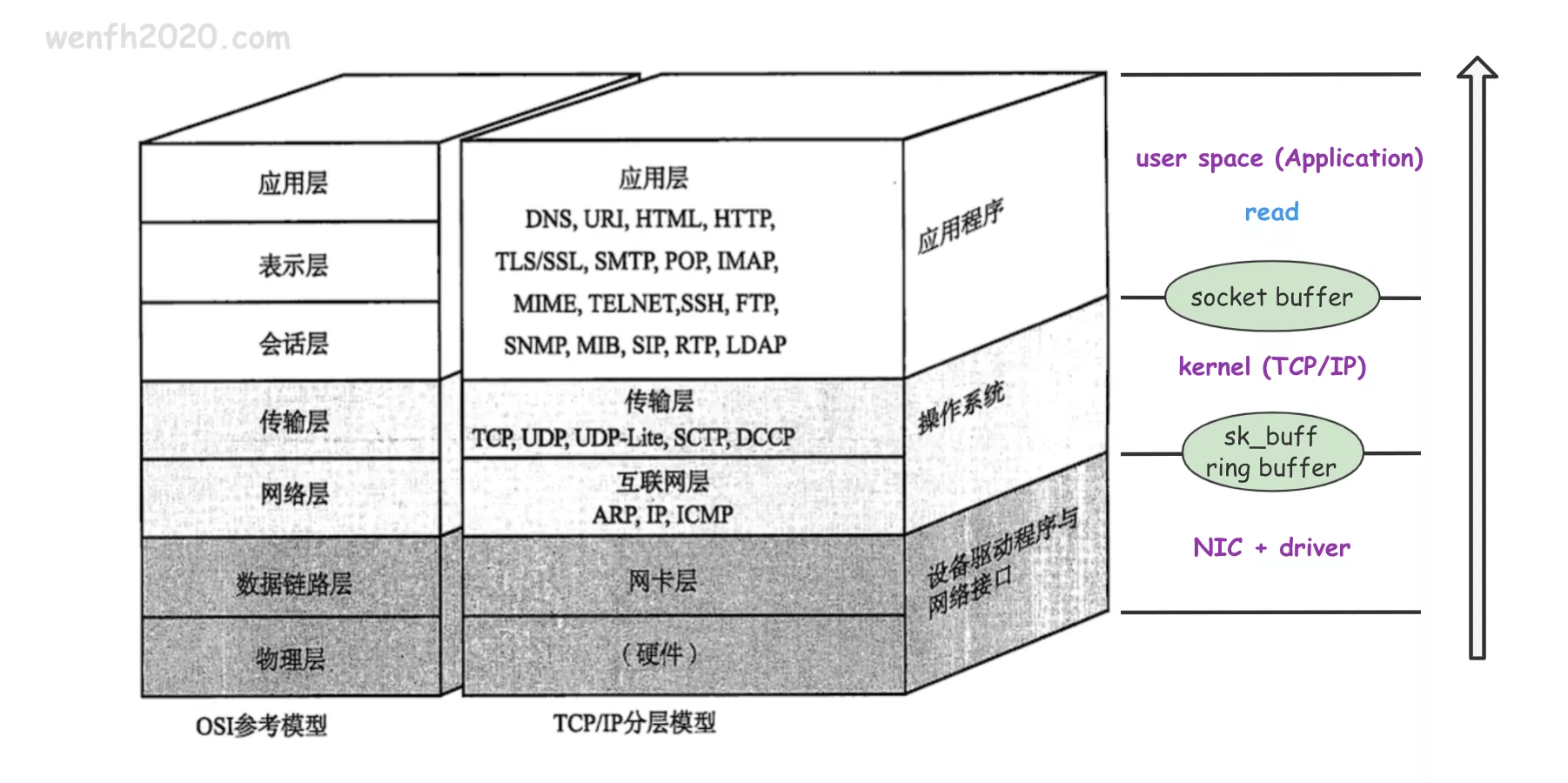
图片来源:《图解 TCP_IP》
2. 总流程
- 网卡驱动注册到内核,方便内核与网卡进行交互。
- 内核启动网卡,为网卡工作分配资源(ring buffer)和注册硬中断处理 e1000_intr。
- 网卡(NIC)接收数据。
- 网卡通过 DMA 方式将接收到的数据写入主存(步骤 2 内核通过网卡驱动将 DMA 内存地址信息写入网卡寄存器,使得网卡获得 DMA 内存信息)。
- 网卡触发硬中断,通知 CPU 已接收数据。
- CPU 收到网卡的硬中断,调用对应的处理函数 e1000_intr。
- 网卡驱动函数先禁止网卡中断,避免频繁硬中断,降低内核的工作效率。
- 网卡驱动将 napi_struct.poll_list 挂在 softnet_data.poll_list 上,方便后面软中断调用 napi_struct.poll 获取网卡数据。
- 然后启用 NET_RX_SOFTIRQ -> net_rx_action 内核软中断。
- 内核软中断线程消费网卡 DMA 方式写入主存的数据。
- 内核软中断遍历 softnet_data.poll_list,调用对应的 napi_struct.poll -> e1000_clean 读取网卡 DMA 方式写入主存的数据。
- e1000_clean 遍历 ring buffer 通过 dma_sync_single_for_cpu 接口读取 DMA 方式写入主存的数据,并将数据拷贝到 e1000_copybreak 创建的 skb 包。
- 网卡驱动读取到 skb 包后,需要将该包传到网络层处理。在这过程中,需要通过 GRO (Generic receive offload) 接口:napi_gro_receive 进行处理,将小包合并成大包,然后通过 __netif_receive_skb 将 skb 包交给 TCP/IP 协议逐层处理,最后将 skb 包追加到 socket.sock.sk_receive_queue 队列,等待应用处理;如果 read / epoll_wait 阻塞等待读取数据,那么唤醒进程/线程。
- skb 包需要传到网络层,如果内核开启了 RPS (Receive Package Steering) 功能,为了利用多核资源,(enqueue_to_backlog)需要将数据包负载均衡到各个 CPU,那么这个 skb 包将会通过哈希算法,挂在某个 cpu 的接收队列上(softnet_data.input_pkt_queue),然后等待软中断调用 softnet_data 的 napi 接口 process_backlog(softnet_data.backlog.poll)将接收队列上的数据包通过 __netif_receive_skb 交给网络层处理。
- 网卡驱动读取了网卡写入的数据,并将数据包交给协议栈处理后,需要通知网卡已读(ring buffer)数据的位置,将位置信息写入网卡 RDT 寄存器(writel(i, hw->hw_addr + rx_ring->rdt)),方便网卡继续往 ring buffer 填充数据。
- 网卡驱动重新设置允许网卡触发硬中断(e1000_irq_enable),重新执行步骤 3。
- 用户程序(或被唤醒)调用 read 接口读取 socket.sock.sk_receive_queue 上的数据并拷贝到用户空间。
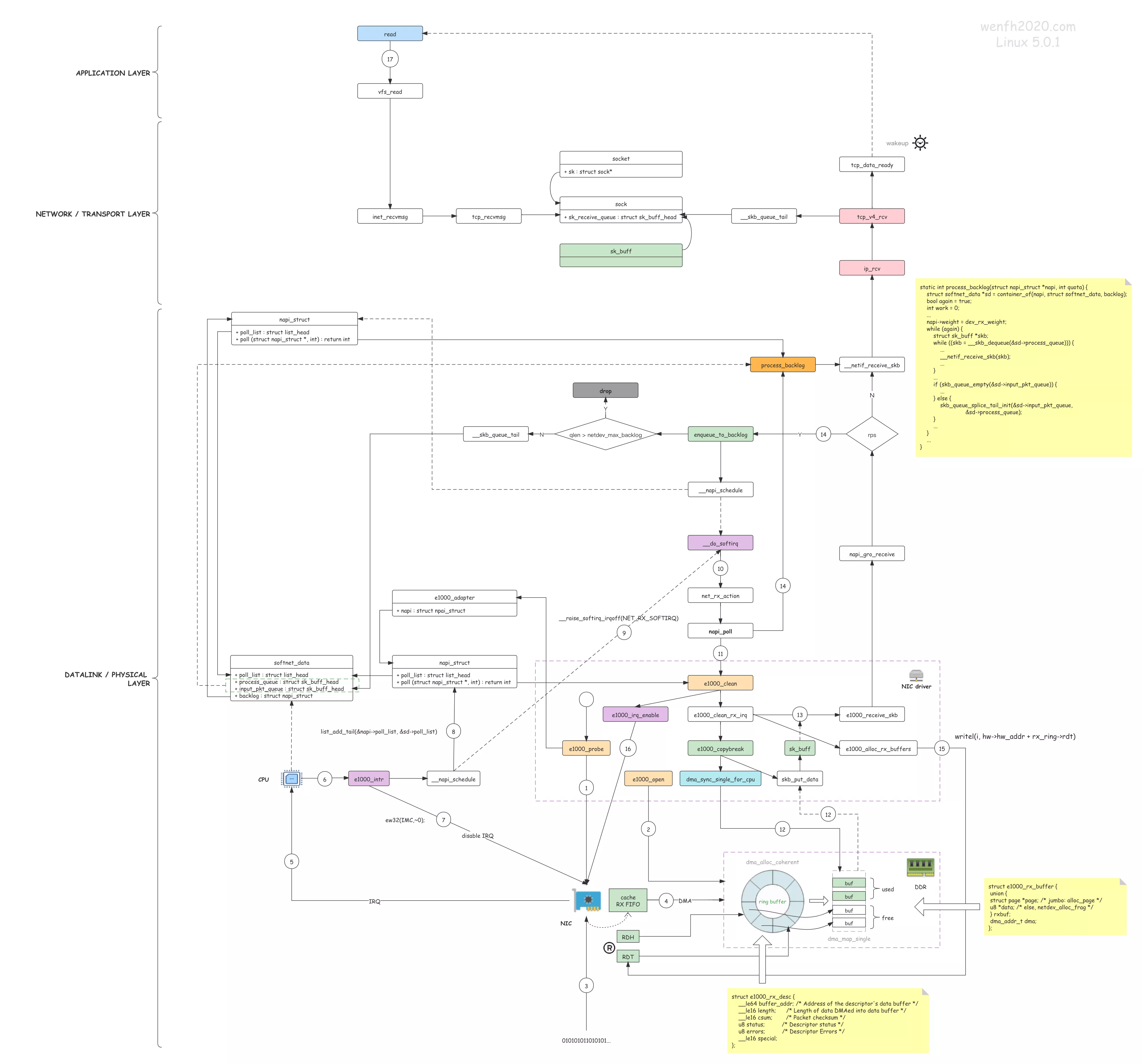
图片来源:linux 网络数据接收流程
3. 要点
网卡 PCI 驱动,NAPI 中断缓解技术,软硬中断,DMA 内存直接访问技术。
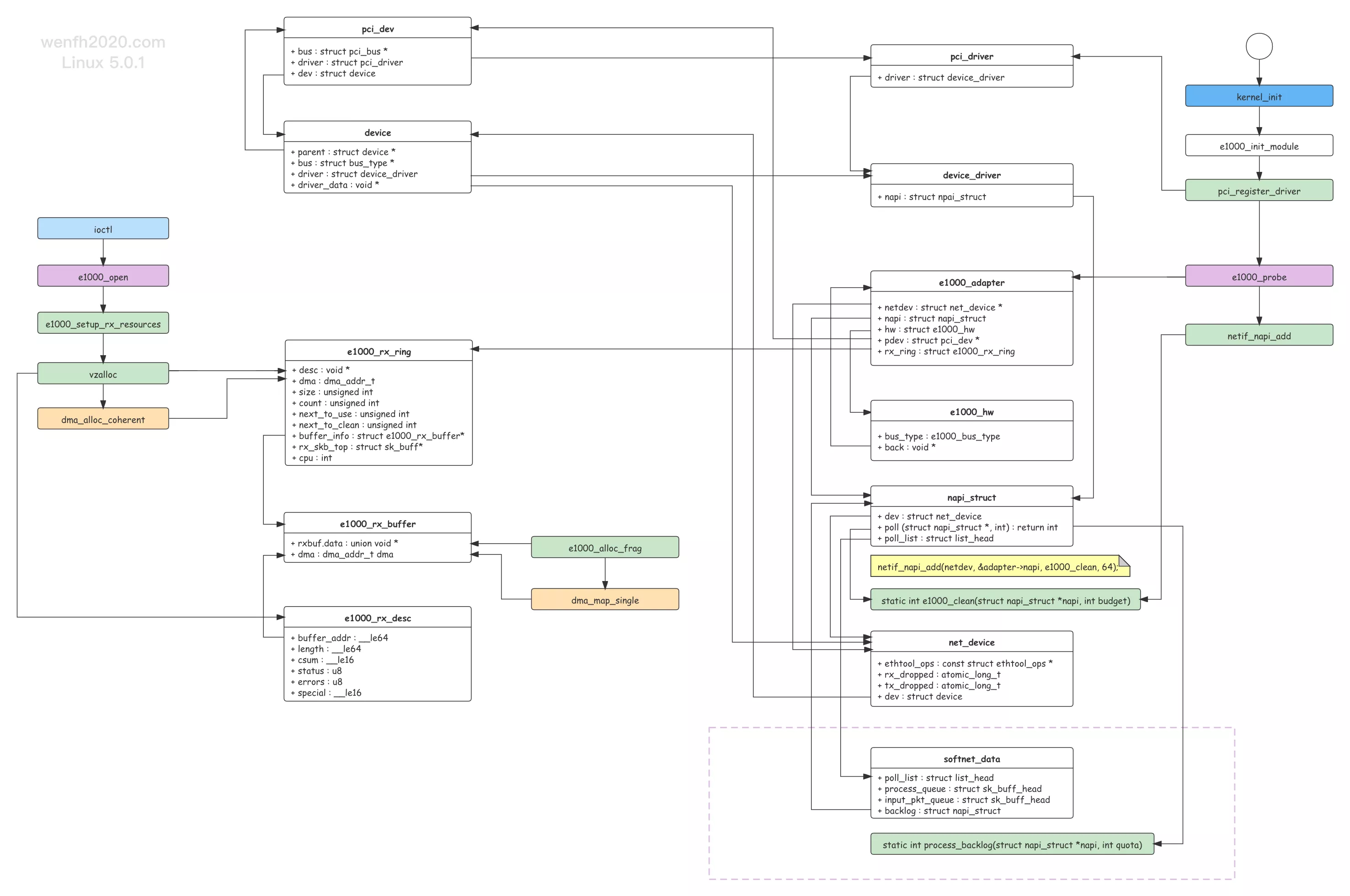
- 源码结构关系。
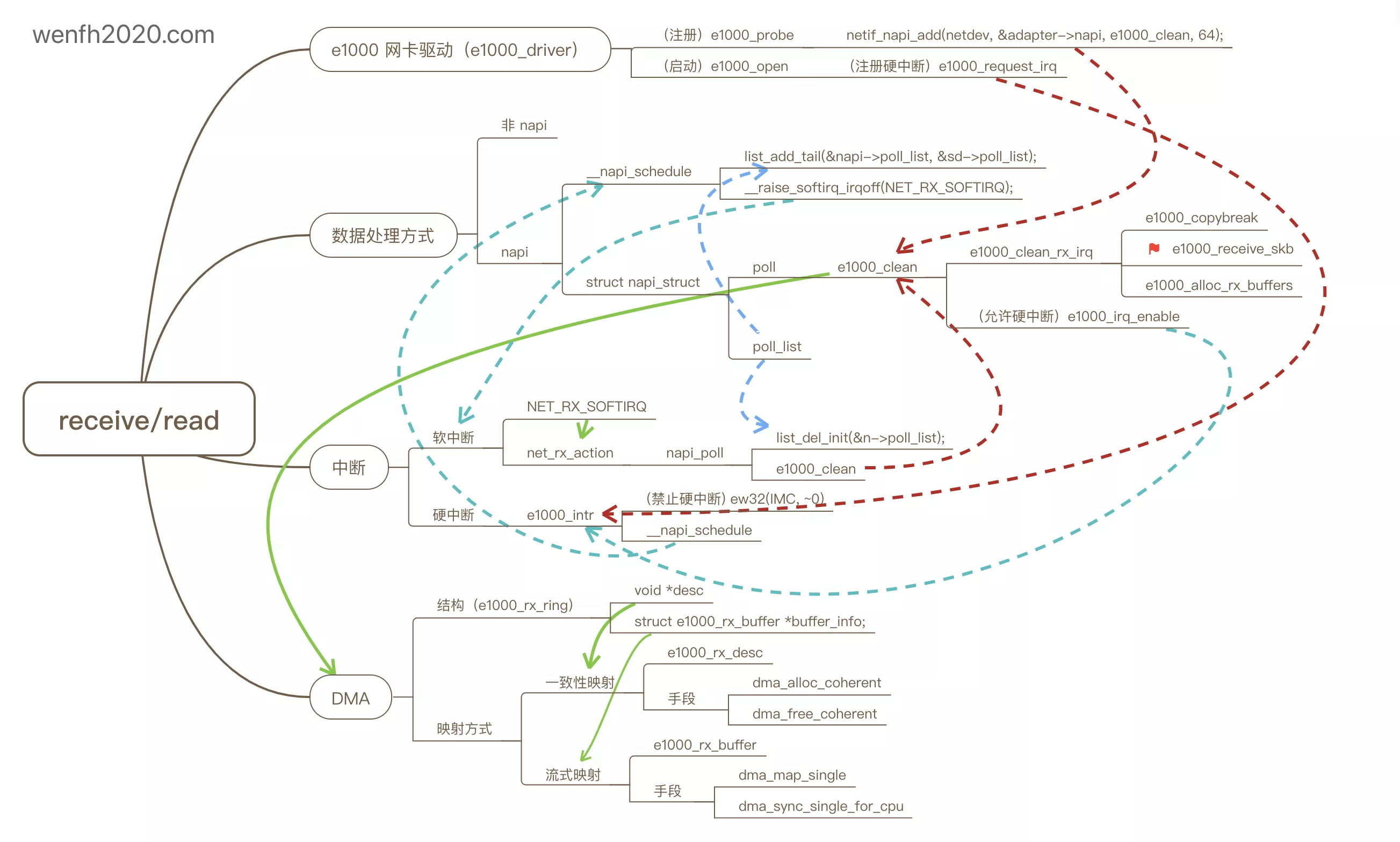
- 要点关系。
3.1. 网卡驱动
网卡是硬件,内核通过网卡驱动与网卡交互。
网卡 e1000 的 intel 驱动(e1000_driver)在 linux 目录:drivers/net/ethernet/intel/e1000
驱动注册(e1000_probe)到内核,启动网卡(e1000_open),为网卡分配系统资源,方便内核与网卡进行交互。
PCI 是 Peripheral Component Interconnect (外设部件互连标准) 的缩写,它是目前个人电脑中使用最为广泛的接口,几乎所有的主板产品上都带有这种插槽。
3.2. NAPI
NAPI (New API) 中断缓解技术,它是 Linux 上采用的一种提高网络处理效率的技术。一般情况下,网卡接收到数据,通过硬中断通知 CPU 进行处理,但是当网卡有大量数据涌入时,频繁中断使得网卡和 CPU 工作效率低下,所以系统采用了硬中断 + 软中断轮询(poll)技术,提升数据接收处理效率(详细流程请参考上面的总流程)。
举个 🌰:餐厅人少时,客户点菜,服务员可以一对一提供服务,客户点一个菜,服务员记录一下;但是人多了,服务员就忙不过来了,这时服务员可以为每张桌子提供一张菜单,客户慢慢看,选好菜了,就通知服务员处理,这样效率就高很多了。
3.3. 中断
中断分上下半部。
- 上半部硬中断主要保存数据,网卡通过硬中断通知 CPU 有数据到来。
- 下半部内核通过软中断处理接收的数据。
- 注册中断。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 内核启动初始化,注册软中断。
kernel_init
|-- net_dev_init
|-- open_softirq(NET_RX_SOFTIRQ, net_rx_action);
##########################################
# ioctl 接口触发开启网卡。
ksys_ioctl
|-- do_vfs_ioctl
|-- __dev_open
|-- e1000_configure
|-- e1000_configure_rx
|-- adapter->clean_rx = e1000_clean_rx_irq; # 软中断处理接收数据包接口。
|-- e1000_request_irq
|-- request_irq(adapter->pdev->irq, e1000_intr, ...); # 注册网卡硬中断 e1000_intr。
- 硬中断处理。
1
2
3
4
5
6
do_IRQ
|-- e1000_intr
|-- ew32(IMC, ~0); # 禁止网卡硬中断。
|-- __napi_schedule
|-- list_add_tail(&napi->poll_list, &sd->poll_list); # 将网卡的 napi 挂在 softnet_data 上。
|-- __raise_softirq_irqoff(NET_RX_SOFTIRQ); # 开启软中断处理接收数据。
- 软中断。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 软中断,处理数据包,放进 socket buffer,数据包处理完后,开启硬中断。
__do_softirq
|-- net_rx_action
|-- napi_poll # 遍历 softnet_data.poll_list
|-- e1000_clean
|-- e1000_clean_rx_irq
|-- e1000_receive_skb
|-- napi_gro_receive
|-- __netif_receive_skb
|-- ip_rcv
|-- tcp_v4_rcv
|-- ...
##########################################
if |-- process_backlog # 开启了 RPS。
|-- ...
|-- __netif_receive_skb
|-- ...
##########################################
|-- e1000_irq_enable # 重新开启硬中断。
3.4. DMA
DMA(Direct Memory Access)可以使得外部设备可以不用 CPU 干预,直接把数据传输到内存,这样可以解放 CPU,提高系统性能。它是 NAPI 中断缓解技术,实现的重要一环。
3.4.1. 网卡与驱动交互
- 系统通过 ring buffer 环形缓冲区管理内存描述符,通过一致性 DMA 映射(
dma_alloc_coherent)描述符(e1000_rx_desc)数组,方便 CPU 和网卡同步访问。 - 环形缓冲区内存描述符指向的内存块(e1000_rx_buffer)通过 DMA 流式映射(
dma_map_single),提供网卡写入。 - 网卡接收到数据,写入网卡缓存。
- 当网卡开始收到数据包后,通过 DMA 方式将数据拷贝到主存,并通过硬中断通知 CPU。
- CPU 接收到硬中断,禁止网卡再触发硬中断(虽然硬中断被禁止了,但是网卡可以继续接收数据,并将数据拷贝到主存),然后唤醒 CPU 软中断(NET_RX_SOFTIRQ -> net_rx_action)。
- 软中断从主存中读取处理网卡 DMA 方式写入的数据(skb),并将数据交给 TCP/IP 协议逐层处理。
- 在有限的时间内一定数量的主存上的数据被处理完后,系统将空闲的(ring buffer)内存描述符提供给网卡,方便网卡下次写入。
- 重新开启网卡硬中断,走上述步骤 3。
3.4.2. ring buffer
例如:e1000 网卡环形缓冲区(e1000_rx_ring)。
系统分配内存缓冲区,映射为 DMA 内存,提供网卡直接访问。
下图(图片来源:stack overflow)简述了 NIC <–> DMA <–> RAM 三者关系。
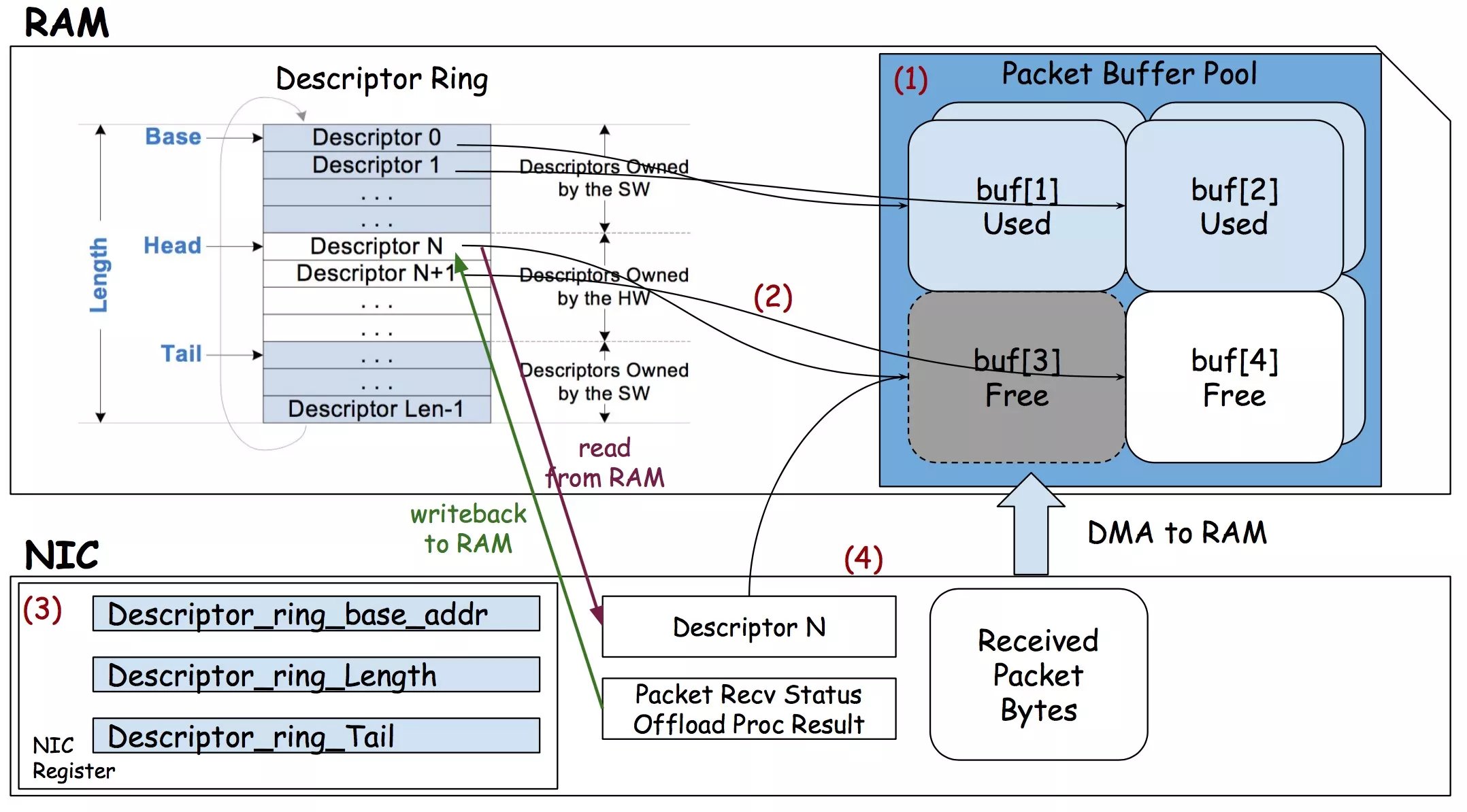
- ring buffer 数据结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
#ifdef CONFIG_ARCH_DMA_ADDR_T_64BIT
typedef u64 dma_addr_t;
#else
typedef u32 dma_addr_t;
#endif
/* drivers/net/ethernet/intel/e1000/e1000.h */
/* board specific private data structure */
struct e1000_adapter {
...
/* RX */
bool (*clean_rx)(struct e1000_adapter *adapter,
struct e1000_rx_ring *rx_ring,
int *work_done, int work_to_do);
void (*alloc_rx_buf)(struct e1000_adapter *adapter,
struct e1000_rx_ring *rx_ring,
int cleaned_count);
struct e1000_rx_ring *rx_ring; /* One per active queue */
...
};
struct e1000_rx_ring {
/* pointer to the descriptor ring memory */
void *desc; /* 内存描述符(e1000_rx_desc)数组。 */
/* physical address of the descriptor ring */
dma_addr_t dma; /* e1000_rx_desc 数组的一致性 DMA 地址。 */
/* length of descriptor ring in bytes */
unsigned int size; /* e1000_rx_desc 数组占用空间大小。 */
/* number of descriptors in the ring */
unsigned int count; /* e1000_rx_desc 描述符个数。 */
/* next descriptor to associate a buffer with */
unsigned int next_to_use; /* 刷新最新空闲内存位置,写入网卡寄存器通知网卡(next_to_use - 1)。*/
/* next descriptor to check for DD status bit */
unsigned int next_to_clean; /* Descriptor Done 标记下次要从该位置取出数据。*/
/* array of buffer information structs */
struct e1000_rx_buffer *buffer_info; /* 流式 DMA 内存,提供网卡通过内存描述符访问内存,DMA 方式写入数据。 */
struct sk_buff *rx_skb_top;
/* cpu for rx queue */
int cpu;
u16 rdh;
u16 rdt;
};
/* 描述符指向的内存块。*/
struct e1000_rx_buffer {
union {
struct page *page; /* jumbo: alloc_page */
u8 *data; /* else, netdev_alloc_frag */
} rxbuf;
dma_addr_t dma;
};
/* Receive Descriptor - 内存描述符。*/
struct e1000_rx_desc {
/* buffer_addr 指向 e1000_rx_buffer.dma 地址。*/
__le64 buffer_addr; /* Address of the descriptor's data buffer */
__le16 length; /* Length of data DMAed into data buffer */
__le16 csum; /* Packet checksum */
/* status:网卡写入数据到内存描述符对应的内存块,当前内存数据状态。 */
u8 status; /* Descriptor status */
u8 errors; /* Descriptor Errors */
__le16 special;
};
- 工作流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
e1000_open
|-- e1000_setup_all_tx_resources
|-- e1000_setup_tx_resources
|-- txdr->desc = dma_alloc_coherent # 一致性 DMA 映射内存描述符(CPU 和网卡可以同步访问)。
|-- e1000_configure(adapter);
|-- e1000_alloc_rx_buffers
|-- e1000_alloc_frag # 分配数据接收空间 skb。
|-- dma_map_single(..., DMA_FROM_DEVICE) # 流式 DMA 映射内存到网卡设备。
|-- writel(i, hw->hw_addr + rx_ring->rdt); # 将新的空闲描述符位置,写入网卡寄存器,通知网卡获取重新写入数据。
# 软中断调用驱动接口,从主存上读取网卡写入的数据,
__do_softirq
|-- net_rx_action
|-- napi_poll
|-- e1000_clean
|-- e1000_clean_rx_irq
|-- e1000_copybreak # 从网卡写入主存的数据(skb),拷贝一份出来。
|-- e1000_alloc_rx_skb # 创建一个新的 skb,方便数据拷贝。
|-- dma_sync_single_for_cpu # 驱动通过该接口访问网卡 DMA 方式写入的数据。
|-- skb_put_data # 将数据写入 skb。
|-- e1000_receive_skb # 从 ring buffer 取出网卡写入的数据。
|-- e1000_alloc_rx_buffers # 对应的 DMA 内存已经被系统读取,那么将该空闲的内存信息传递给网卡重新写入数据。(这个函数,不展开了,参考上面相应描述。)
-
ring buffer 偏移原理。
e1000_rx_ring.desc 指针指向了一个 e1000_rx_desc 数组,网卡和网卡驱动都通过这个数组进行读写数据。这个数组被称为
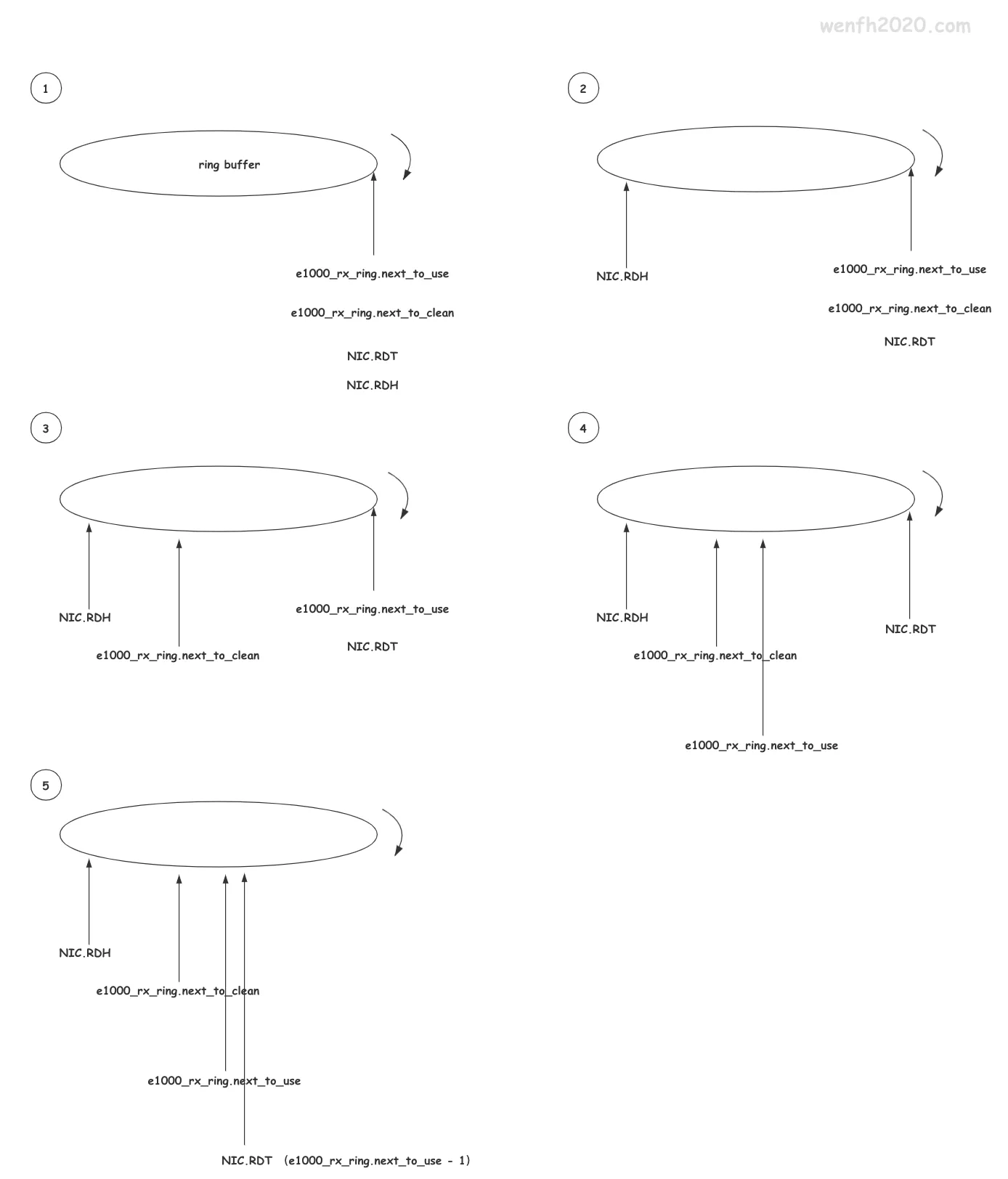
环形缓冲区:通过数组下标遍历数组,下标指向数组末位后,重新指向数组第一个位置,看起来像个环形结构,——理解它需要些抽象思维;因为网卡和网卡驱动都操作它,所以每个对象都维护了自己的一套head和tail进行标识。
- 初始状态,下标都指向数组一个元素 e1000_rx_ring.desc[0]。
- 网卡接收到数据通过 DMA 方式拷贝到主存(e1000_rx_ring.desc[i] -> e1000_rx_buffer),如下图,NIC.RDH 顺时针偏移,NIC.RDT 到 NIC.RDH 的 e1000_rx_desc[i]->e1000_rx_buffer 内存块都填充了接收数据。
- 网卡驱动顺时针遍历 ring buffer,根据网卡更新的 e1000_rx_ring.desc[i].status 状态,读取 e1000_rx_ring.desc[i] 指向的 e1000_rx_buffer 数据块,因为读取数据有时间限制(jiffies)和数据量限制(budget),网卡驱动不一定能一次性读取完成网卡写入主存的数据,所以最后读取的数据位置要进行记录,通过 e1000_rx_ring.next_to_clean 记录下一次要读取数据的位置。
- 既然网卡驱动已经读取了数据,那么已读取的数据已经没用了,可以(清理)重新提供给网卡继续写入,那么需要把下次要清理的位置记录起来:e1000_rx_ring.next_to_use。
- 但是这时候网卡还不知道驱动消费数据到哪个位置,那么驱动清理掉数据后,将已清理最后的位置(e1000_rx_ring.next_to_use - 1)写入网卡寄存器 RDT,告诉网卡,下次可以(顺时针)写入数据,从 NIC.RDH 到 NIC.RDT。
4. 调试
要了解更多细节,可以搭建 Linux 的调试环境进行源码调试。
详细请参考文章:搭建 Linux 内核网络调试环境(vscode + gdb + qemu)。
5. 参考
- 《Linux 内核源码剖析 - TCP/IP 实现》
- What is the relationship of DMA ring buffer and TX/RX ring for a network card?
- Linux网络协议栈:NAPI机制与处理流程分析(图解)
- NAPI机制分析
- 图解Linux网络包接收过程
- Linux e1000网卡驱动流程
- (转)网络数据包收发流程(三):e1000网卡和DMA
- linux网络流程分析(一)—网卡驱动
- Cache和DMA一致性
- dma基础_一文读懂dma的方方面面
- Linux网络系统原理笔记
- Linux 基础之网络包收发流程
- 如果让你来设计网络
- Linux网络 - 数据包的接收过程
- Linux网络包收发总体过程
- NAPI模式–中断和轮询的折中以及一个负载均衡的问题
- 【互联网后台技术】网卡的ring buffer调整
- 网卡收包流程
- 15 | 网络优化(上):移动开发工程师必备的网络优化知识
- 网卡的 Ring Buffer 详解
- Redis高负载下的中断优化
- 1. 网卡收包
- 2. NAPI机制
- 3. GRO机制
- 网络收包流程-报文从网卡驱动到网络层(或者网桥)的流程(非NAPI、NAPI)(一)
- 深入理解Linux网络技术内幕 第10章 帧的接收
- 数据包如何从物理网卡到达云主机的应用程序?
- 怎么打开网卡rss_Linux性能优化之RSS/RPS/RFS/XPS
- 玩转KVM: 了解网卡软中断RPS