
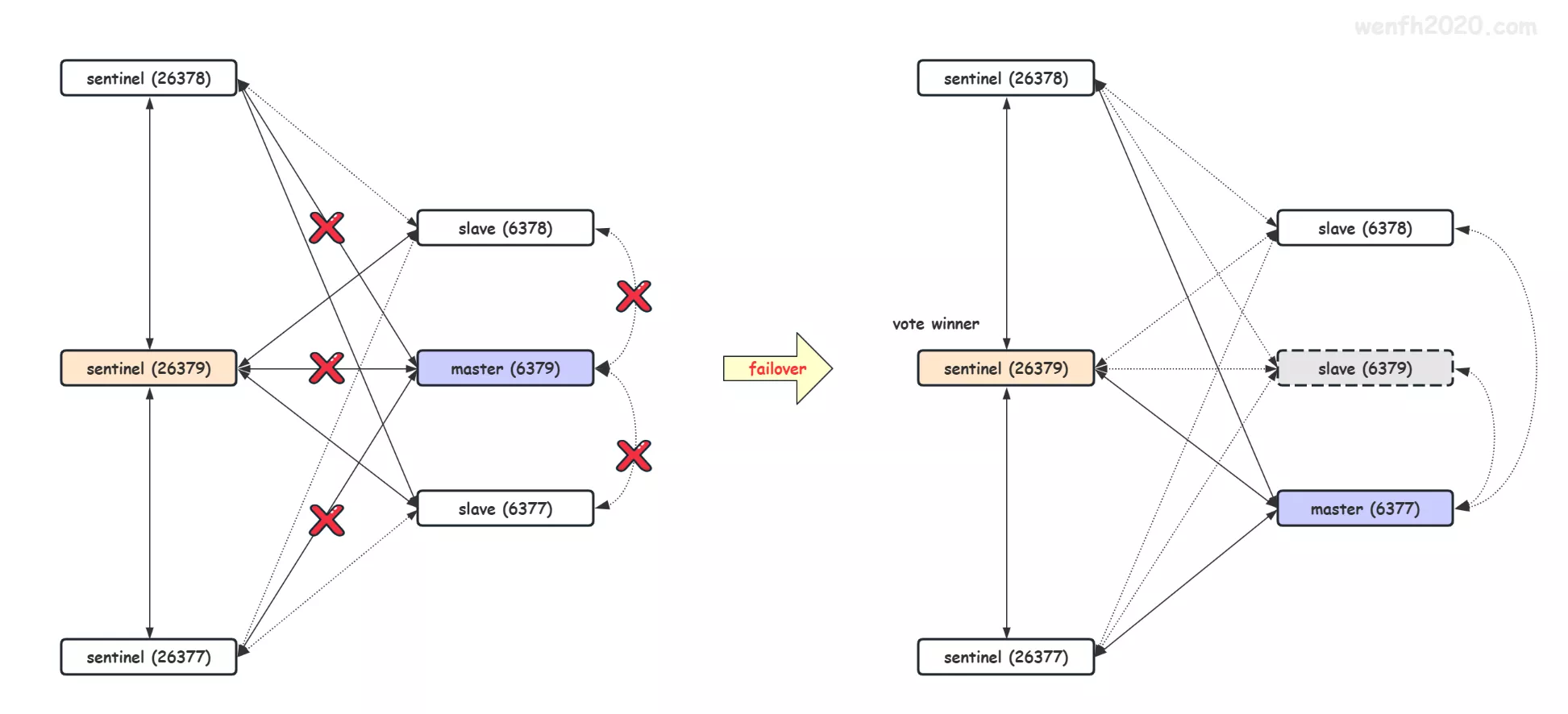
前面几章已经讲了:redis 集群各个角色之间的通信,主客观下线,投票选举;在选举中胜出的哨兵 leader,由它来完成 redis 集群的故障转移:redis 实例的角色转换。
哨兵故障转移主体流程:
- master 主观下线
- master 客观下线
- 选举
- leader 筛选原 master 的最优 slave
- 晋升最优 slave 为新 master
- 通知原 master 的其它 slave 链接新 master
- 结束故障转移
- 更新新 master 的存储结构关系
- 旧 master 重新上线被降级为 slave。
1. 故障转移
故障转移由许多环节组成,集群中每个 sentinel 都有机会实行,但是只有在选举过程中赢得选票的人,才可以完整完成整个故障转移流程。
1.1. 流程
sentinel 节点故障转移流程的几个环节:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
/* 初始状态。*/
#define SENTINEL_FAILOVER_STATE_NONE 0 /* No failover in progress. */
/* 开始进入选举投票状态。*/
#define SENTINEL_FAILOVER_STATE_WAIT_START 1 /* Wait for failover_start_time*/
/* 选出最优 slave。 */
#define SENTINEL_FAILOVER_STATE_SELECT_SLAVE 2 /* Select slave to promote */
/* 提升最优 slave 为新master。 */
#define SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE 3 /* Slave -> Master */
/* 等待最优 slave 成功晋升:info 回复 role:master。 */
#define SENTINEL_FAILOVER_STATE_WAIT_PROMOTION 4 /* Wait slave to change role */
/* slaves 连接新 master。 */
#define SENTINEL_FAILOVER_STATE_RECONF_SLAVES 5 /* SLAVEOF newmaster */
/* slave 成功晋升 master 后,更新 master <--> slave 的数据结构关系。 */
#define SENTINEL_FAILOVER_STATE_UPDATE_CONFIG 6 /* Monitor promoted slave. */
/* 进入故障转移流程。*/
void sentinelFailoverStateMachine(sentinelRedisInstance *ri) {
serverAssert(ri->flags & SRI_MASTER);
/* 确保当前没有故障转移正在执行。*/
if (!(ri->flags & SRI_FAILOVER_IN_PROGRESS)) return;
switch (ri->failover_state) {
case SENTINEL_FAILOVER_STATE_WAIT_START:
sentinelFailoverWaitStart(ri);
break;
case SENTINEL_FAILOVER_STATE_SELECT_SLAVE:
sentinelFailoverSelectSlave(ri);
break;
case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE:
sentinelFailoverSendSlaveOfNoOne(ri);
break;
case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION:
sentinelFailoverWaitPromotion(ri);
break;
case SENTINEL_FAILOVER_STATE_RECONF_SLAVES:
sentinelFailoverReconfNextSlave(ri);
break;
}
}
1.2. 测试
3 个 sentinel,3 个 redis 实例,一主两从。关闭主服务,再重新启动主服务,通过 sentinel 日志看看故障转移情况。
- 测试节点。
| node | ip | port |
|---|---|---|
| sentinel A | 127.0.0.1 | 26379 |
| sentinel B | 127.0.0.1 | 26377 |
| sentinel C | 127.0.0.1 | 26378 |
| master | 127.0.0.1 | 6379 |
| slave | 127.0.0.1 | 6378 |
| slave2 | 127.0.0.1 | 6377 |
- 测试脚本(github)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#!/bin/sh
...
# 关闭所有 redis 进程。
kill_redis
# 开启所有 sentinel 进程。
start_sentinels
# 打印 sentinel 进程信息。
redis_info redis-sentinel
# 开启所有 redis 进程。
start_redis
# 打印 redis 进程信息。
redis_info redis-server
# 将 6379 端口的 redis 设置为 master。
remaster 6379
# 向 redis 进程获取角色信息。
redis_role
# 向 sentinel 获取角色信息。
get_master_info_from_sentinel 26379
# 等待足够长时间,让 sentinel 发现所有节点,彼此建立通信。
sleep 100
# 关闭 6379 进程。
shutdown_redis 6379
# 等待 sentinel 故障转移成功(一般很快,根据需要设置时间。)
echo 'failover wait for 30s......'
sleep 30
# 模拟将下线的 6379 master 重新上线。
remaster_redis 6379
sleep 5
...
# 查看 sentinel 日志,观察工作流程。
- sentinel-26379 故障转移日志,它在选举中赢得选票,执行完整的故障转移流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
32121:X 30 Sep 2020 15:06:54.145 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
32121:X 30 Sep 2020 15:06:54.145 # Redis version=5.9.104, bits=64, commit=00000000, modified=0, pid=32121, just started
32121:X 30 Sep 2020 15:06:54.145 # Configuration loaded
# 当前 sentinel 端口为 26379
32123:X 30 Sep 2020 15:06:54.147 * Running mode=sentinel, port=26379.
# 当前 sentinel runnid: 0400c9**
32123:X 30 Sep 2020 15:06:54.148 # Sentinel ID is 0400c9170654ecbaeaf98fedb1630486e5f8f5b6
# 修改 sentinel 监控对象,监控端口为 6379 的 master。
32123:X 30 Sep 2020 15:06:54.148 # +monitor master mymaster 127.0.0.1 6378 quorum 2
32123:X 30 Sep 2020 15:07:00.211 # -monitor master mymaster 127.0.0.1 6378
32123:X 30 Sep 2020 15:07:00.237 # +monitor master mymaster 127.0.0.1 6379 quorum 2
# 设置故障转移有效时间段为 10 秒。
32123:X 30 Sep 2020 15:07:00.254 # +set master mymaster 127.0.0.1 6379 failover-timeout 10000
# 从 master 6379 中发现 slave 6378。
32123:X 30 Sep 2020 15:07:00.291 * +slave slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
# 当前 sentinel 通过 hello 频道的订阅信息,发现其它的 sentinel。
32123:X 30 Sep 2020 15:07:02.271 * +sentinel sentinel 989f0e00789a0b41cff738704ce8b04bad306714 127.0.0.1 26378 @ mymaster 127.0.0.1 6379
32123:X 30 Sep 2020 15:07:02.290 * +sentinel sentinel de0ffb0d63f77605db3fccb959f67b65b8fdb529 127.0.0.1 26377 @ mymaster 127.0.0.1 6379
# 从 master 6379 中发现 slave 6377。
32123:X 30 Sep 2020 15:07:10.359 * +slave slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
---
# 发现 master 6379 主观下线。
32123:X 30 Sep 2020 15:07:51.408 # +sdown master mymaster 127.0.0.1 6379
# 确认 master 6379 客观下线。
32123:X 30 Sep 2020 15:07:51.474 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2
# 开始进入选举环节,选举纪元(计数器) 29。(这个测试日志不是第一次,所以纪元有历史数据。)
32123:X 30 Sep 2020 15:07:51.474 # +new-epoch 29
# 尝试对 6379 开启故障转移流程,注意:这里还没正式开启,只有在选举中获胜的 sentinel 才会正式开启。
32123:X 30 Sep 2020 15:07:51.474 # +try-failover master mymaster 127.0.0.1 6379
# 当前 sentinel 没发现其它 sentinel 向它拉票,所以它把选票投给了自己。
32123:X 30 Sep 2020 15:07:51.494 # +vote-for-leader 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 29
# 26378 把票投给了当前 sentinel。
32123:X 30 Sep 2020 15:07:51.501 # 989f0e00789a0b41cff738704ce8b04bad306714 voted for 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 29
# 26377 把票投给了当前 sentinel。
32123:X 30 Sep 2020 15:07:51.501 # de0ffb0d63f77605db3fccb959f67b65b8fdb529 voted for 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 29
# 当前 sentinel 赢得选票,开启对 6379 开启故障转移。
32123:X 30 Sep 2020 15:07:51.560 # +elected-leader master mymaster 127.0.0.1 6379
# 进入筛选最优 slave 环节。
32123:X 30 Sep 2020 15:07:51.560 # +failover-state-select-slave master mymaster 127.0.0.1 6379
# 筛选出最优 slave 为 6377。
32123:X 30 Sep 2020 15:07:51.626 # +selected-slave slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
# 发送 "slaveof no one" 给 6377 提升它为 master。
32123:X 30 Sep 2020 15:07:51.626 * +failover-state-send-slaveof-noone slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
# 等待 6378 晋升结果。
32123:X 30 Sep 2020 15:07:51.697 * +failover-state-wait-promotion slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
# 6377 晋升 master 成功。
32123:X 30 Sep 2020 15:07:52.273 # +promoted-slave slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
# 进入重置关系环节,连接旧 master 的 slaves 连接新的 master。
32123:X 30 Sep 2020 15:07:52.273 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
# 给 6378 发送 "slaveof" 命令,让 slave 6378 连接新 master 6377。
32123:X 30 Sep 2020 15:07:52.348 * +slave-reconf-sent slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
32123:X 30 Sep 2020 15:07:52.615 # -odown master mymaster 127.0.0.1 6379
# slave 6378 接收命令 "slaveof",成功更新配置。
32123:X 30 Sep 2020 15:07:53.317 * +slave-reconf-inprog slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
# slave 6378 成功连接新 master 6377。
32123:X 30 Sep 2020 15:07:53.317 * +slave-reconf-done slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
# 连接旧 master 6379 所有的 slave 都处理完了,结束故障转移。
32123:X 30 Sep 2020 15:07:53.388 # +failover-end master mymaster 127.0.0.1 6379
# slave 6377 成功晋升 master,所以要更新当前 master 信息 6379 --> 6377。
32123:X 30 Sep 2020 15:07:53.388 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6377
# master / slave 重新建立联系。
32123:X 30 Sep 2020 15:07:53.389 * +slave slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6377
# 旧 master 6379 变成了新 master 6377 的 slave。
32123:X 30 Sep 2020 15:07:53.389 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
# 重新连接,发现 6379 没上线,标识它为主观下线,因为它不是 master 了,不需要走确认客观下线流程。
32123:X 30 Sep 2020 15:08:23.392 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
---
# 当前 sentinel 发现旧 master 6379 重新上线,去掉它主观下线标识。
32123:X 30 Sep 2020 15:10:22.709 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
# 旧 master 角色还是 master,被 sentinel 降级为 slave。
32123:X 30 Sep 2020 15:10:42.730 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
- sentinel-26378 故障转移日志。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
32129:X 30 Sep 2020 15:06:55.149 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
32129:X 30 Sep 2020 15:06:55.149 # Redis version=5.9.104, bits=64, commit=00000000, modified=0, pid=32129, just started
32129:X 30 Sep 2020 15:06:55.149 # Configuration loaded
# 当前 sentinel 端口为 26378。
32131:X 30 Sep 2020 15:06:55.151 * Running mode=sentinel, port=26378.
32131:X 30 Sep 2020 15:06:55.152 # Sentinel ID is 989f0e00789a0b41cff738704ce8b04bad306714
# 修改 sentinel 监控对象,监控端口为 6379 的 master。
32131:X 30 Sep 2020 15:06:55.152 # +monitor master mymaster 127.0.0.1 6378 quorum 2
32131:X 30 Sep 2020 15:07:00.220 # -monitor master mymaster 127.0.0.1 6378
32131:X 30 Sep 2020 15:07:00.243 # +monitor master mymaster 127.0.0.1 6379 quorum 2
# 设置故障转移有效时间段为 10 秒。
32131:X 30 Sep 2020 15:07:00.259 # +set master mymaster 127.0.0.1 6379 failover-timeout 10000
# 发现 slave 节点 6378。(已知节点会保存在 sentinel.conf 中,启动会加载。)
32131:X 30 Sep 2020 15:07:00.284 * +slave slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
# 发现 sentinel 节点。
32131:X 30 Sep 2020 15:07:02.290 * +sentinel sentinel de0ffb0d63f77605db3fccb959f67b65b8fdb529 127.0.0.1 26377 @ mymaster 127.0.0.1 6379
32131:X 30 Sep 2020 15:07:02.305 * +sentinel sentinel 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 127.0.0.1 26379 @ mymaster 127.0.0.1 6379
# 发现 slave 节点 6377。
32131:X 30 Sep 2020 15:07:10.345 * +slave slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
# 检测到 master 6379 主观下线。
32131:X 30 Sep 2020 15:07:51.396 # +sdown master mymaster 127.0.0.1 6379
32131:X 30 Sep 2020 15:07:51.497 # +new-epoch 29
# 收到 26379 的拉票,选票还没有投给其它人,那选票投给 26379 并选出了 leader 为 26379。
32131:X 30 Sep 2020 15:07:51.500 # +vote-for-leader 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 29
# 检测到 master 6379 客观下线。
32131:X 30 Sep 2020 15:07:51.500 # +odown master mymaster 127.0.0.1 6379 #quorum 2/2
# 满足开启故障转移条件,但是 26379 先开启了故障转移,那只有等待到一个 failover-timeout 过期才能进行下一轮故障转移。
32131:X 30 Sep 2020 15:07:51.500 # Next failover delay: I will not start a failover before Wed Sep 30 15:08:12 2020
# sentinel 26379 已经成功将 slave 6377 晋升为 master,它通过 hello 频道通知其它的 sentinel。
32131:X 30 Sep 2020 15:07:52.350 # +config-update-from sentinel 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 127.0.0.1 26379 @ mymaster 127.0.0.1 6379
# 更新 master 数据,
32131:X 30 Sep 2020 15:07:52.350 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6377
# 更新 master <--> slaves 的拓扑关系:
32131:X 30 Sep 2020 15:07:52.350 * +slave slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6377
32131:X 30 Sep 2020 15:07:52.350 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
# 6379 没有上线,所以标识为主观下线。
32131:X 30 Sep 2020 15:08:22.354 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
# 旧 master 6379 重新上线,当前 sentinel 去掉主观下线标识。
32131:X 30 Sep 2020 15:10:23.166 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
- sentinel-26377 故障转移日志(跟 sentinel-26378 日志差不多,不详细注释了。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
32138:X 30 Sep 2020 15:06:56.151 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
32138:X 30 Sep 2020 15:06:56.151 # Redis version=5.9.104, bits=64, commit=00000000, modified=0, pid=32138, just started
32138:X 30 Sep 2020 15:06:56.151 # Configuration loaded
32140:X 30 Sep 2020 15:06:56.155 * Running mode=sentinel, port=26377.
32140:X 30 Sep 2020 15:06:56.156 # Sentinel ID is de0ffb0d63f77605db3fccb959f67b65b8fdb529
32140:X 30 Sep 2020 15:06:56.156 # +monitor master mymaster 127.0.0.1 6378 quorum 2
32140:X 30 Sep 2020 15:07:00.227 # -monitor master mymaster 127.0.0.1 6378
32140:X 30 Sep 2020 15:07:00.250 # +monitor master mymaster 127.0.0.1 6379 quorum 2
32140:X 30 Sep 2020 15:07:00.265 # +set master mymaster 127.0.0.1 6379 failover-timeout 10000
32140:X 30 Sep 2020 15:07:00.284 * +slave slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6379
32140:X 30 Sep 2020 15:07:02.271 * +sentinel sentinel 989f0e00789a0b41cff738704ce8b04bad306714 127.0.0.1 26378 @ mymaster 127.0.0.1 6379
32140:X 30 Sep 2020 15:07:02.305 * +sentinel sentinel 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 127.0.0.1 26379 @ mymaster 127.0.0.1 6379
32140:X 30 Sep 2020 15:07:10.332 * +slave slave 127.0.0.1:6377 127.0.0.1 6377 @ mymaster 127.0.0.1 6379
32140:X 30 Sep 2020 15:07:51.371 # +sdown master mymaster 127.0.0.1 6379
32140:X 30 Sep 2020 15:07:51.498 # +new-epoch 29
32140:X 30 Sep 2020 15:07:51.500 # +vote-for-leader 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 29
32140:X 30 Sep 2020 15:07:52.349 # +config-update-from sentinel 0400c9170654ecbaeaf98fedb1630486e5f8f5b6 127.0.0.1 26379 @ mymaster 127.0.0.1 6379
32140:X 30 Sep 2020 15:07:52.349 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6377
32140:X 30 Sep 2020 15:07:52.349 * +slave slave 127.0.0.1:6378 127.0.0.1 6378 @ mymaster 127.0.0.1 6377
32140:X 30 Sep 2020 15:07:52.349 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
32140:X 30 Sep 2020 15:08:22.379 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
32140:X 30 Sep 2020 15:10:22.900 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6377
2. 源码流程
2.1. 开启故障转移
满足故障转移条件后,开启故障转移,进入投票选举环节。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
/* 定时检查 master 故障情况情况。*/
void sentinelHandleRedisInstance(sentinelRedisInstance *ri) {
...
if (ri->flags & SRI_MASTER) {
...
/* 是否满足故障转移条件,开启故障转移。 */
if (sentinelStartFailoverIfNeeded(ri)) {
...
}
/* 通过状态机,处理故障转移对应各个环节。*/
sentinelFailoverStateMachine(ri);
...
}
}
/* 是否满足故障转移条件,开启故障转移。 */
int sentinelStartFailoverIfNeeded(sentinelRedisInstance *master) {
...
/* 1. 检测到 master 客观下线。
* 2. 没有正在对该客观下线的 master 进行故障转移。
* 3. 需要与一个故障转移相隔一段足够长的时间。*/
sentinelStartFailover(master);
return 1;
}
/* 开启故障转移。*/
void sentinelStartFailover(sentinelRedisInstance *master) {
...
master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
master->flags |= SRI_FAILOVER_IN_PROGRESS;
master->failover_start_time = mstime() + rand() % SENTINEL_MAX_DESYNC;
...
}
2.2. 统计投票结果
开启故障转移后,要经过选举投票环节,经过票数统计,确认当前 sentinel 在选举中胜出,当前 sentinel 节点作为 leader 执行下一个环节:筛选客观下线 master 的最优 slave。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
void sentinelFailoverWaitStart(sentinelRedisInstance *ri) {
char *leader;
int isleader;
/* 统计故障转移票数。*/
leader = sentinelGetLeader(ri, ri->failover_epoch);
isleader = leader && strcasecmp(leader, sentinel.myid) == 0;
sdsfree(leader);
/* 选举出来的 leader 如果不是自己,或者这次故障转移不是强制执行。
* 那么不能执行故障转移余下环节。*/
if (!isleader && !(ri->flags & SRI_FORCE_FAILOVER)) {
int election_timeout = SENTINEL_ELECTION_TIMEOUT;
...
/* 如果我不是投票的 winner,那么一段时间后,退出故障转移工作流程。*/
if (mstime() - ri->failover_start_time > election_timeout) {
sentinelEvent(LL_WARNING, "-failover-abort-not-elected", ri, "%@");
sentinelAbortFailover(ri);
}
return;
}
...
/* 符合故障转移条件,执行故障转移下一个环节:筛选 master 对应的优质的 slave。 */
ri->failover_state = SENTINEL_FAILOVER_STATE_SELECT_SLAVE;
ri->failover_state_change_time = mstime();
...
}
/* 退出故障转移流程,恢复相关数据标识。 */
void sentinelAbortFailover(sentinelRedisInstance *ri) {
serverAssert(ri->flags & SRI_FAILOVER_IN_PROGRESS);
serverAssert(ri->failover_state <= SENTINEL_FAILOVER_STATE_WAIT_PROMOTION);
ri->flags &= ~(SRI_FAILOVER_IN_PROGRESS | SRI_FORCE_FAILOVER);
ri->failover_state = SENTINEL_FAILOVER_STATE_NONE;
ri->failover_state_change_time = mstime();
if (ri->promoted_slave) {
ri->promoted_slave->flags &= ~SRI_PROMOTED;
ri->promoted_slave = NULL;
}
}
2.3. 筛选最优 slave
筛选方法:先遍历 master 的 slaves,找出网络连接没有异常的 slave,将它们放进候选数组中,再通过快速排序从候选名单中筛选出最优的 slave。
最优 slave 需要具备条件:
- 网络连接没有处于异常状态的。
- 优先级小的。
- 数据复制偏移量比较大的。
- slave runid 字符串进行比较,筛选比较结果小于 0 的。
下面是筛选流程,英文文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/* Select a suitable slave to promote. The current algorithm only uses
* the following parameters:
*
* 1) None of the following conditions: S_DOWN, O_DOWN, DISCONNECTED.
* 2) Last time the slave replied to ping no more than 5 times the PING period.
* 3) info_refresh not older than 3 times the INFO refresh period.
* 4) master_link_down_time no more than:
* (now - master->s_down_since_time) + (master->down_after_period * 10).
* Basically since the master is down from our POV, the slave reports
* to be disconnected no more than 10 times the configured down-after-period.
* This is pretty much black magic but the idea is, the master was not
* available so the slave may be lagging, but not over a certain time.
* Anyway we'll select the best slave according to replication offset.
* 5) Slave priority can't be zero, otherwise the slave is discarded.
*
* Among all the slaves matching the above conditions we select the slave
* with, in order of sorting key:
*
* - lower slave_priority.
* - bigger processed replication offset.
* - lexicographically smaller runid.
*
* Basically if runid is the same, the slave that processed more commands
* from the master is selected.
*
* The function returns the pointer to the selected slave, otherwise
* NULL if no suitable slave was found.
*/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
void sentinelFailoverSelectSlave(sentinelRedisInstance *ri) {
/* 选择优质 slave。 */
sentinelRedisInstance *slave = sentinelSelectSlave(ri);
/* 如果 master 没有 slave 那么退出故障转移。 */
if (slave == NULL) {
sentinelEvent(LL_WARNING, "-failover-abort-no-good-slave", ri, "%@");
sentinelAbortFailover(ri);
} else {
/* 进入提升角色环节,要将优质 slave 提升为 master。 */
sentinelEvent(LL_WARNING, "+selected-slave", slave, "%@");
slave->flags |= SRI_PROMOTED;
/* 记录需要提升角色的 slave。 */
ri->promoted_slave = slave;
/* 进入提升角色环节。 */
ri->failover_state = SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE;
ri->failover_state_change_time = mstime();
sentinelEvent(LL_NOTICE, "+failover-state-send-slaveof-noone", slave, "%@");
}
}
sentinelRedisInstance *sentinelSelectSlave(sentinelRedisInstance *master) {
sentinelRedisInstance **instance =
zmalloc(sizeof(instance[0]) * dictSize(master->slaves));
sentinelRedisInstance *selected = NULL;
int instances = 0;
dictIterator *di;
dictEntry *de;
mstime_t max_master_down_time = 0;
if (master->flags & SRI_S_DOWN) {
max_master_down_time += mstime() - master->s_down_since_time;
}
max_master_down_time += master->down_after_period * 10;
/* 遍历客观下线的 master 的 slaves,筛选最优的 slave。 */
di = dictGetIterator(master->slaves);
while ((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
mstime_t info_validity_time;
/* 已经下线的 slave 不要选。 */
if (slave->flags & (SRI_S_DOWN | SRI_O_DOWN)) continue;
/* 已经断开连接的 slave 不要选。 */
if (slave->link->disconnected) continue;
/* 链接不是很好的,已经一段时间没有收到数据包的,不要选。 */
if (mstime() - slave->link->last_avail_time > SENTINEL_PING_PERIOD * 5) continue;
/* 优先级为 0 的,不要选。 */
if (slave->slave_priority == 0) continue;
/* 如果 master 已经主观下线,那么修改获取 info 信息的有效时间间隔。 */
if (master->flags & SRI_S_DOWN)
info_validity_time = SENTINEL_PING_PERIOD * 5;
else
info_validity_time = SENTINEL_INFO_PERIOD * 3;
/* 当获取的 info 信息的有效间间隔太长,不要选。因为在故障转移过程中,
* sentinel 给 slave 发送 INFO 命令的频率会提高到一秒一次。
* 详细参考 sentinelSendPeriodicCommands。如果 INFO 命令回复太慢,
* 说明该 slave 处在异常状态下。*/
if (mstime() - slave->info_refresh > info_validity_time) continue;
/* 如果该 slave 与 master 断开连接时间间隔过长,不要选。 */
if (slave->master_link_down_time > max_master_down_time) continue;
/* 经过一系列筛选,将满足条件的 slave 添加到候选名单中去。 */
instance[instances++] = slave;
}
dictReleaseIterator(di);
if (instances) {
/* 通过快速排序,二次筛选在候选名单里的 slave,选出最优的 slave。 */
qsort(instance, instances, sizeof(sentinelRedisInstance *),
compareSlavesForPromotion);
selected = instance[0];
}
zfree(instance);
return selected;
}
/* 通过快排从 slave 候选名单中筛选出最优 slave。 */
int compareSlavesForPromotion(const void *a, const void *b) {
sentinelRedisInstance **sa = (sentinelRedisInstance **)a,
**sb = (sentinelRedisInstance **)b;
char *sa_runid, *sb_runid;
if ((*sa)->slave_priority != (*sb)->slave_priority)
return (*sa)->slave_priority - (*sb)->slave_priority;
/* 选最大数据复制偏移量的 slave。 */
if ((*sa)->slave_repl_offset > (*sb)->slave_repl_offset) {
return -1; /* a < b */
} else if ((*sa)->slave_repl_offset < (*sb)->slave_repl_offset) {
return 1; /* a > b */
}
/* 如果上述条件都满足,那么对比候选 slave 的 runid 字符串,进行筛选。*/
sa_runid = (*sa)->runid;
sb_runid = (*sb)->runid;
if (sa_runid == NULL && sb_runid == NULL)
return 0;
else if (sa_runid == NULL)
return 1; /* a > b */
else if (sb_runid == NULL)
return -1; /* a < b */
return strcasecmp(sa_runid, sb_runid);
}
2.4. slave 晋升 master
sentinel leader 给 slave 发送 slaveof 命令,使得 master 客观下线后,原来链接客观下线 master 的 slaves,能重新建立 master <–> slave 的关系。
sentinel leader 给筛选出来的 slave 中发送 slave no one 命令,使得该 slave 成为 master 角色。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
/* 发送命令 "slaveof no one"。 */
void sentinelFailoverSendSlaveOfNoOne(sentinelRedisInstance *ri) {
int retval;
...
/* sentinel 给筛选出来的 slave 发送 "slaveof no one" 命令,让该 slave 成为 master。
* sentinel 并不关心命令返回的结果,因为它通过发送 “info” 命令,确认它的角色是否发生改变。 */
retval = sentinelSendSlaveOf(ri->promoted_slave, NULL, 0);
if (retval != C_OK) return;
sentinelEvent(LL_NOTICE, "+failover-state-wait-promotion",
ri->promoted_slave, "%@");
ri->failover_state = SENTINEL_FAILOVER_STATE_WAIT_PROMOTION;
ri->failover_state_change_time = mstime();
}
/* 通过事务给 slave 发命令,使得 redis 实例间重新建立主从关系。 */
int sentinelSendSlaveOf(sentinelRedisInstance *ri, char *host, int port) {
...
if (host == NULL) {
host = "NO";
memcpy(portstr, "ONE", 4);
}
...
/* 为了安全起见,几条命令,通过事务方式发送。 */
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s",
sentinelInstanceMapCommand(ri, "MULTI"));
...
/* 给 slave 发 "slaveof" 命令。 */
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s %s %s",
sentinelInstanceMapCommand(ri, "SLAVEOF"),
host, portstr);
...
/* 给 slave 发配置重写命令,上一条命令使得 slaves 之间的关系发生改变
* (slaveof/replicaof <masterip> <masterport>),
* redis 需要将其写入 redis.conf 配置文件。 */
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s REWRITE",
sentinelInstanceMapCommand(ri, "CONFIG"));
...
/* 通知 slave 关闭 normal 和 pubsub 的连接,使得在故障转移过程中,
* 原来接入的客户端在断开连接后,能够重新获取 master,重新连接。
* 当前 sentinel 与 slave 的连接,在 slave 回复后,也会断开。
* 详细参考 networking.c/void clientCommand(client *c) 实现。*/
for (int type = 0; type < 2; type++) {
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s KILL TYPE %s",
sentinelInstanceMapCommand(ri, "CLIENT"),
type == 0 ? "normal" : "pubsub");
...
}
/* 提交事务。 */
retval = redisAsyncCommand(ri->link->cc,
sentinelDiscardReplyCallback, ri, "%s",
sentinelInstanceMapCommand(ri, "EXEC"));
...
return C_OK;
}
2.5. 等待 slave 晋升成功
当 sentinel leader 给 slave 发送命令后,sentinel leader 需要通过发送 info 命令给 slave,并根据命令的回复内容,确认 slave 是否成功转换为 master。
因为 redis 是异步通信,发送命令给最优 slave 后,slave 会断开所有 “normal” 和 “pubsub” 连接,其它 client 也会重新连接。这个过程需要时间,但是这个过程的时间间隔不能超过 failover_timeout 故障转移时间,否则将退出故障转移流程。
当 slave 回复命令 info 内容,说明已经成功晋升为 master,进入故障转移下一步。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/* We actually wait for promotion indirectly checking with INFO when the
* slave turns into a master. */
void sentinelFailoverWaitPromotion(sentinelRedisInstance *ri) {
/* Just handle the timeout. Switching to the next state is handled
* by the function parsing the INFO command of the promoted slave. */
if (mstime() - ri->failover_state_change_time > ri->failover_timeout) {
sentinelEvent(LL_WARNING, "-failover-abort-slave-timeout", ri, "%@");
sentinelAbortFailover(ri);
}
}
/* 当 slave 回复 info,已经成功晋升为 master,进入故障转移下一步。 */
void sentinelRefreshInstanceInfo(sentinelRedisInstance *ri, const char *info) {
...
if ((ri->flags & SRI_SLAVE) && role == SRI_MASTER) {
if ((ri->flags & SRI_PROMOTED) &&
(ri->master->flags & SRI_FAILOVER_IN_PROGRESS) &&
(ri->master->failover_state == SENTINEL_FAILOVER_STATE_WAIT_PROMOTION)) {
...
ri->master->config_epoch = ri->master->failover_epoch;
/* 进入 SENTINEL_FAILOVER_STATE_RECONF_SLAVES 环节。 */
ri->master->failover_state = SENTINEL_FAILOVER_STATE_RECONF_SLAVES;
ri->master->failover_state_change_time = mstime();
...
}
}
...
}
2.6. slaves <–> new master
当最优 slave 成功晋升为 master 后,sentinel leader 再通过 SLAVEOF 命令,让其它的 slave 接入到新的 master 中去。
2.6.1. slave/master 连接状态
1
2
3
#define SRI_RECONF_SENT (1 << 8) /* SLAVEOF <newmaster> sent. */
#define SRI_RECONF_INPROG (1 << 9) /* Slave synchronization in progress. */
#define SRI_RECONF_DONE (1 << 10) /* Slave synchronized with new master. */
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
/* Send SLAVE OF <new master address> to all the remaining slaves that
* still don't appear to have the configuration updated. */
void sentinelFailoverReconfNextSlave(sentinelRedisInstance *master) {
dictIterator *di;
dictEntry *de;
int in_progress = 0;
/* 统计正在操作的 slave 个数。 */
di = dictGetIterator(master->slaves);
while ((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
if (slave->flags & (SRI_RECONF_SENT | SRI_RECONF_INPROG))
in_progress++;
}
dictReleaseIterator(di);
di = dictGetIterator(master->slaves);
/* 遍历 slave 进行 reconf,arallel_syncs 限制每次 reconf 的 slave 个数,避免操作失败。 */
while (in_progress < master->parallel_syncs && (de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
int retval;
/* 跳过已经晋升为 master 的 slave 或者已经成功处理 slaveof 命令的 slave。 */
if (slave->flags & (SRI_PROMOTED | SRI_RECONF_DONE)) continue;
/* 如果 slave 接收命令 slaveof 后,长时间没有更新配置成功,那么终止对它的 reconf 操作。 */
if ((slave->flags & SRI_RECONF_SENT) &&
(mstime() - slave->slave_reconf_sent_time) > SENTINEL_SLAVE_RECONF_TIMEOUT) {
sentinelEvent(LL_NOTICE, "-slave-reconf-sent-timeout", slave, "%@");
slave->flags &= ~SRI_RECONF_SENT;
slave->flags |= SRI_RECONF_DONE;
}
/* 跳过已发送 reconf 成功的。 */
if (slave->flags & (SRI_RECONF_SENT | SRI_RECONF_INPROG)) continue;
/* 不处理断线的 slave。 */
if (slave->link->disconnected) continue;
/* 发送命令 "SLAVEOF <new master>"。 */
retval = sentinelSendSlaveOf(slave,
master->promoted_slave->addr->ip,
master->promoted_slave->addr->port);
if (retval == C_OK) {
/* 更新 reconf 状态。 */
slave->flags |= SRI_RECONF_SENT;
slave->slave_reconf_sent_time = mstime();
sentinelEvent(LL_NOTICE, "+slave-reconf-sent", slave, "%@");
in_progress++;
}
}
dictReleaseIterator(di);
/* Check if all the slaves are reconfigured and handle timeout. */
sentinelFailoverDetectEnd(master);
}
2.6.2. info 回复刷新状态
sentinel leader 给 slave 发送 “slaveof” 命令,使得连接旧的 master 的 slave 去连接新 master。但是 sentinel leader 不会通过 “slaveof” 命令的回复获得结果,而是发完命令后,定时给 slave 发 “info” 命令,从 “info” 命令回复内容中,确认,slave 是否已经与新 masger 成功建立连接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
void sentinelRefreshInstanceInfo(sentinelRedisInstance *ri, const char *info) {
...
/* 检测 slave 连接新 master 的状态。 */
if ((ri->flags & SRI_SLAVE) && role == SRI_SLAVE &&
(ri->flags & (SRI_RECONF_SENT | SRI_RECONF_INPROG))) {
/* sentinel 收到 slave 的 info 回复,配置成功更新,修改状态为进行中:
* SRI_RECONF_SENT -> SRI_RECONF_INPROG. */
if ((ri->flags & SRI_RECONF_SENT) && ri->slave_master_host &&
strcmp(ri->slave_master_host, ri->master->promoted_slave->addr->ip) == 0 &&
ri->slave_master_port == ri->master->promoted_slave->addr->port) {
ri->flags &= ~SRI_RECONF_SENT;
/* 进入“进行中”状态。 */
ri->flags |= SRI_RECONF_INPROG;
sentinelEvent(LL_NOTICE, "+slave-reconf-inprog", ri, "%@");
}
/* 当 slave 已经连接上 master 了,更新状态为结束:
* SRI_RECONF_INPROG -> SRI_RECONF_DONE。 */
if ((ri->flags & SRI_RECONF_INPROG) &&
ri->slave_master_link_status == SENTINEL_MASTER_LINK_STATUS_UP) {
ri->flags &= ~SRI_RECONF_INPROG;
ri->flags |= SRI_RECONF_DONE;
sentinelEvent(LL_NOTICE, "+slave-reconf-done", ri, "%@");
}
}
...
}
2.7. 结束故障转移
检查原连接客观掉线的 slaves 是否已经全部成功连接新 master 了,或者这个环节是否处理超时。出现上述任何一种情况,故障转移都会结束。在故障转移结束前,如果还有剩余的 slaves 没有连上新 master,那么 sentinel leader,会再做一次努力,对它们再次发送 “slaveof” 命令。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
void sentinelFailoverDetectEnd(sentinelRedisInstance *master) {
int not_reconfigured = 0, timeout = 0;
dictIterator *di;
dictEntry *de;
mstime_t elapsed = mstime() - master->failover_state_change_time;
/* We can't consider failover finished if the promoted slave is
* not reachable. */
if (master->promoted_slave == NULL ||
master->promoted_slave->flags & SRI_S_DOWN) return;
/* 统计没有 reconf 的 slave 个数。 */
di = dictGetIterator(master->slaves);
while ((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
if (slave->flags & (SRI_PROMOTED | SRI_RECONF_DONE)) continue;
if (slave->flags & SRI_S_DOWN) continue;
not_reconfigured++;
}
dictReleaseIterator(di);
/* 如果 slave reconf 超时,需要强制结束这个环节。*/
if (elapsed > master->failover_timeout) {
not_reconfigured = 0;
timeout = 1;
sentinelEvent(LL_WARNING, "+failover-end-for-timeout", master, "%@");
}
if (not_reconfigured == 0) {
sentinelEvent(LL_WARNING, "+failover-end", master, "%@");
/* 当没有 reconf 的 slave 了进入下一个故障转移环节。*/
master->failover_state = SENTINEL_FAILOVER_STATE_UPDATE_CONFIG;
master->failover_state_change_time = mstime();
}
/* 如果 slave reconf 超时了,作为 sentinel leader 为了提高 slave reconf 的成功率。
* 在故障转移结束前,再做最后一次努力:对没有连接新 master 的 slave,再发一次 "slaveof" 命令。*/
if (timeout) {
dictIterator *di;
dictEntry *de;
di = dictGetIterator(master->slaves);
while ((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
int retval;
if (slave->flags & (SRI_PROMOTED | SRI_RECONF_DONE | SRI_RECONF_SENT)) continue;
if (slave->link->disconnected) continue;
retval = sentinelSendSlaveOf(slave,
master->promoted_slave->addr->ip,
master->promoted_slave->addr->port);
if (retval == C_OK) {
sentinelEvent(LL_NOTICE, "+slave-reconf-sent-be", slave, "%@");
slave->flags |= SRI_RECONF_SENT;
}
}
dictReleaseIterator(di);
}
}
2.8. 更新新 master 信息
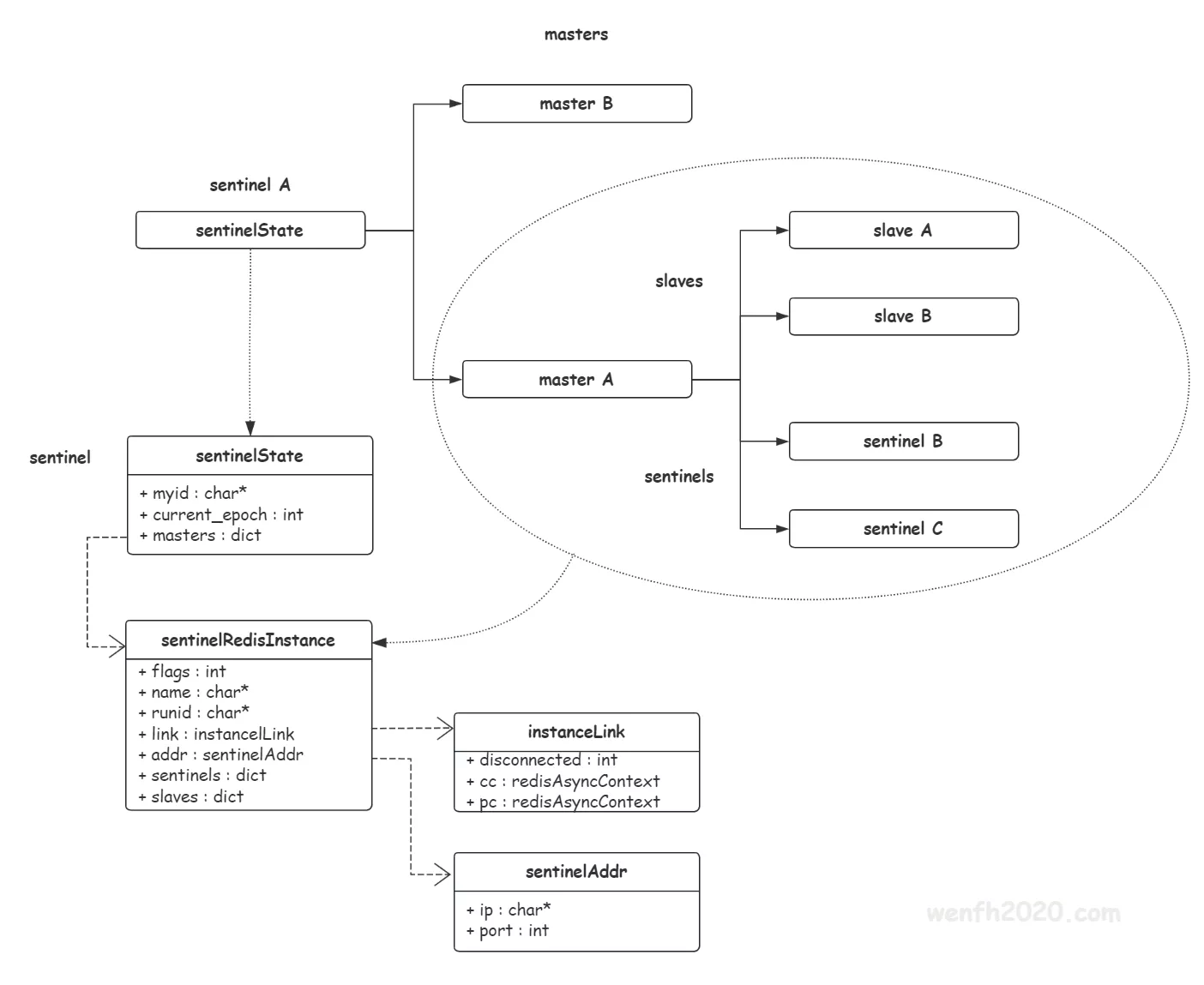
sentinel 存储节点信息的拓扑结构(如下图),所以当故障转移成功,sentinel leader 理应更新对应节点的数据和数据结构关系。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
/* 定时监控节点的工作情况。 */
void sentinelHandleDictOfRedisInstances(dict *instances) {
...
di = dictGetIterator(instances);
while ((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
...
if (ri->flags & SRI_MASTER) {
...
if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) {
/* 故障转移结束,更新 master 最新信息。*/
switch_to_promoted = ri;
}
}
}
if (switch_to_promoted)
sentinelFailoverSwitchToPromotedSlave(switch_to_promoted);
dictReleaseIterator(di);
}
/* 故障转移成功以后,新的 master 信息替换旧的。*/
void sentinelFailoverSwitchToPromotedSlave(sentinelRedisInstance *master) {
sentinelRedisInstance *ref = master->promoted_slave ? master->promoted_slave : master;
sentinelEvent(LL_WARNING, "+switch-master", master, "%s %s %d %s %d",
master->name, master->addr->ip, master->addr->port,
ref->addr->ip, ref->addr->port);
sentinelResetMasterAndChangeAddress(master, ref->addr->ip, ref->addr->port);
}
/* 重置旧 master 数据,建立新的 master <--> slave 数据关系。*/
int sentinelResetMasterAndChangeAddress(sentinelRedisInstance *master, char *ip, int port) {
sentinelAddr *oldaddr, *newaddr;
sentinelAddr **slaves = NULL;
int numslaves = 0, j;
dictIterator *di;
dictEntry *de;
newaddr = createSentinelAddr(ip, port);
if (newaddr == NULL) return C_ERR;
/* 将原来连接 master 的 slaves 重新放进一个 slaves 数组。 */
di = dictGetIterator(master->slaves);
while ((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
/* 如果是晋升 master 的 slave,不要放进数组。*/
if (sentinelAddrIsEqual(slave->addr, newaddr)) continue;
slaves = zrealloc(slaves, sizeof(sentinelAddr *) * (numslaves + 1));
slaves[numslaves++] = createSentinelAddr(slave->addr->ip, slave->addr->port);
}
dictReleaseIterator(di);
/* 我们把旧的 master 添加到 slaves 数组,因为旧的 master 有可能重新上线,
* sentinel 会给它发 "slaveof" 命令,让它角色下降为 slave。*/
if (!sentinelAddrIsEqual(newaddr, master->addr)) {
slaves = zrealloc(slaves, sizeof(sentinelAddr *) * (numslaves + 1));
slaves[numslaves++] = createSentinelAddr(master->addr->ip, master->addr->port);
}
/* 重置旧 master 数据,填充新的信息,使得旧 master 变成新 master。 */
sentinelResetMaster(master, SENTINEL_RESET_NO_SENTINELS);
oldaddr = master->addr;
master->addr = newaddr;
master->o_down_since_time = 0;
master->s_down_since_time = 0;
/* 新建 slaves 实例与新 master 建立关系。*/
for (j = 0; j < numslaves; j++) {
sentinelRedisInstance *slave;
slave = createSentinelRedisInstance(NULL, SRI_SLAVE, slaves[j]->ip,
slaves[j]->port, master->quorum, master);
releaseSentinelAddr(slaves[j]);
if (slave) sentinelEvent(LL_NOTICE, "+slave", slave, "%@");
}
zfree(slaves);
/* Release the old address at the end so we are safe even if the function
* gets the master->addr->ip and master->addr->port as arguments. */
releaseSentinelAddr(oldaddr);
sentinelFlushConfig();
return C_OK;
}
2.9. 旧 master 重新上线
原 master 恢复正常,重新连接 sentinel,这时候集群已经产生新的 master 了,所以旧 master,需要被 sentinel 降级为 slave。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
/* info 命令回复 */
void sentinelRefreshInstanceInfo(sentinelRedisInstance *ri, const char *info) {
...
/* sentinel 将旧 master 记录为 slave 了,旧 master 通过 info 还上报 master 角色。
* 需要发送 "slaveof" 命令将它降级为 slave。*/
if ((ri->flags & SRI_SLAVE) && role == SRI_MASTER) {
/* If this is a promoted slave we can change state to the
* failover state machine. */
if ((ri->flags & SRI_PROMOTED) &&
(ri->master->flags & SRI_FAILOVER_IN_PROGRESS) &&
(ri->master->failover_state == SENTINEL_FAILOVER_STATE_WAIT_PROMOTION)) {
...
} else {
mstime_t wait_time = SENTINEL_PUBLISH_PERIOD * 4;
if (!(ri->flags & SRI_PROMOTED) &&
sentinelMasterLooksSane(ri->master) &&
sentinelRedisInstanceNoDownFor(ri, wait_time) &&
mstime() - ri->role_reported_time > wait_time) {
/* 发送 "slaveof" 命令。 */
int retval = sentinelSendSlaveOf(ri,
ri->master->addr->ip,
ri->master->addr->port);
if (retval == C_OK)
sentinelEvent(LL_NOTICE, "+convert-to-slave", ri, "%@");
}
}
}
...
}