
一致性哈希算法是一种特殊的哈希算法,目的是解决分布式缓存的问题。
本章主要讲述一致性哈希算法在 kimserver 架构下的使用流程,以及算法实现。
算法原理,这篇帖子(《五分钟理解一致性哈希算法》)讲得很通俗易懂,可以去看看。
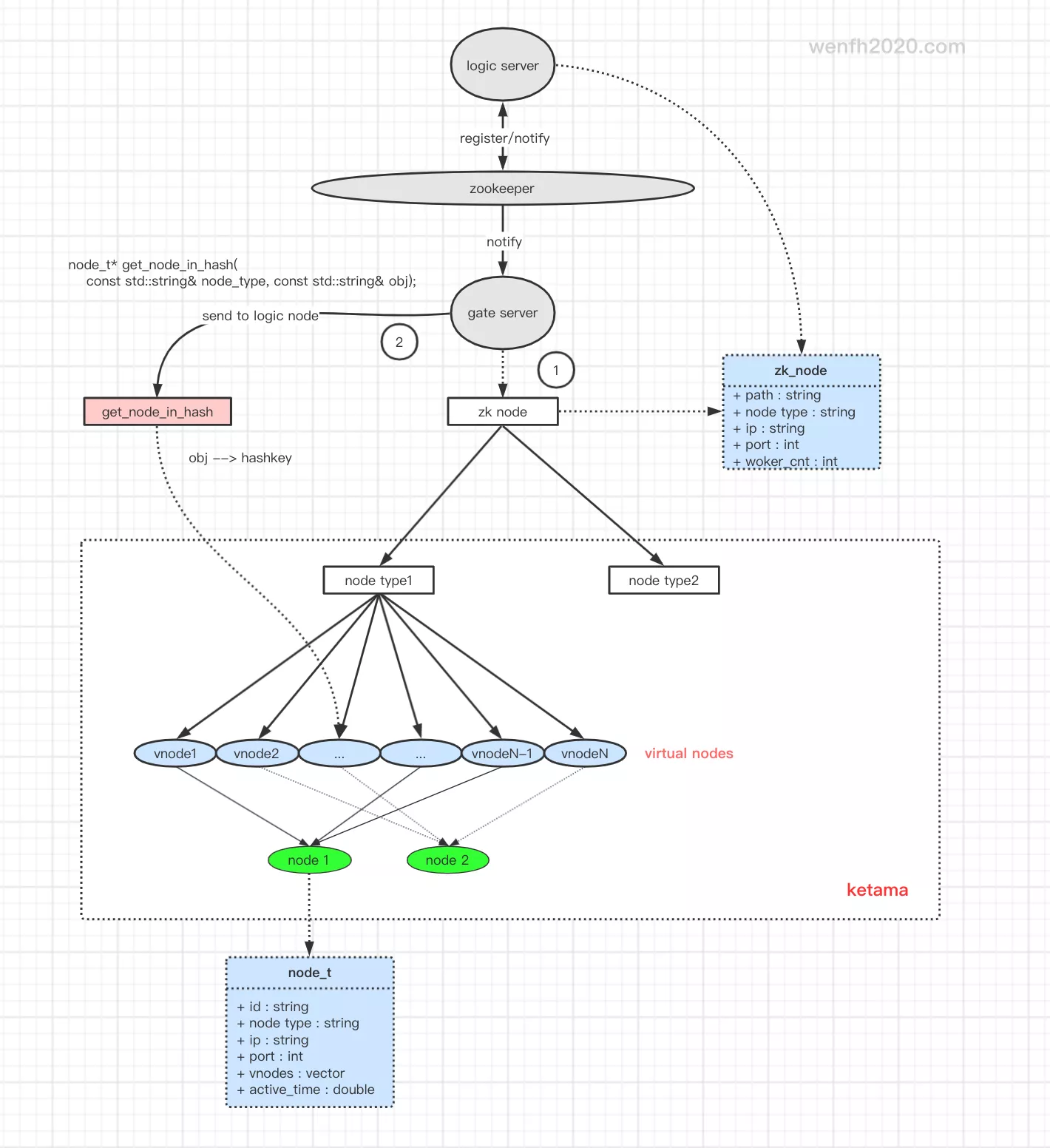
1. 流程
节点间相互通信流程:
- 节点间通过
zookeeper进行节点发现。发现新的节点信息然后通过一致性哈希算法,创建一层虚拟节点与实体节点信息建立映射。 - 两个节点通信,通过一致性哈希算法获取对应节点信息。将发送目标通过哈希算法,生成一个哈希键(uint32_t),然后从虚拟节点上找出虚拟节点映射的实体节点进行发送。
详细通信流程可以参考 《[kimserver] 分布式系统-多进程框架节点通信》
2. 算法测试结果
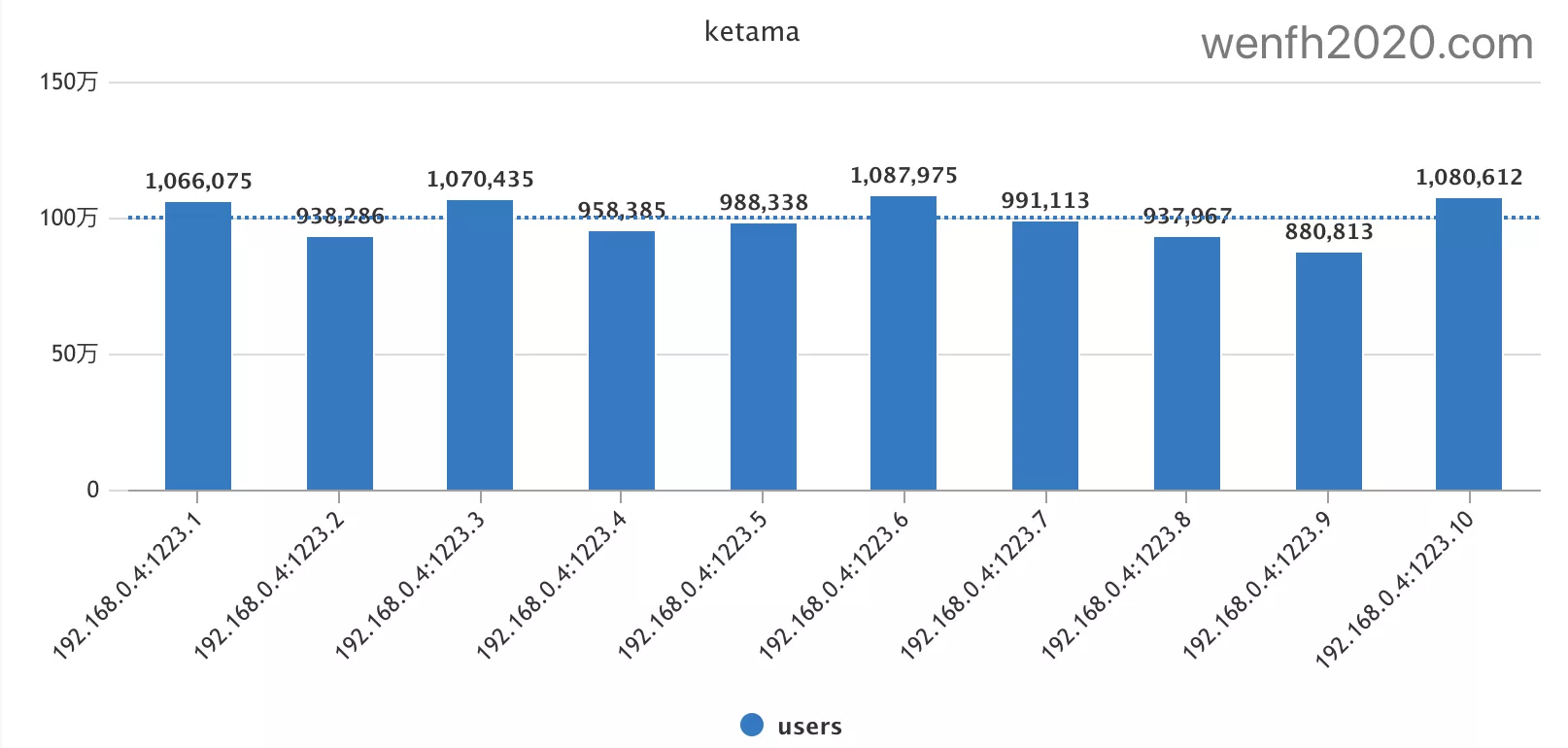
2.1. 数据分布
模拟 1000 w 个不同用户,它们路由到 10 个节点上的数据分布情况,每个节点数据量相差不大,分布基本均匀,在 100w 上下浮动,但是最大值和最小值相差 23.5 %,所以这个分布算法还有改进空间。
(1087975-880813) / 880813.0 == 0.235194076382
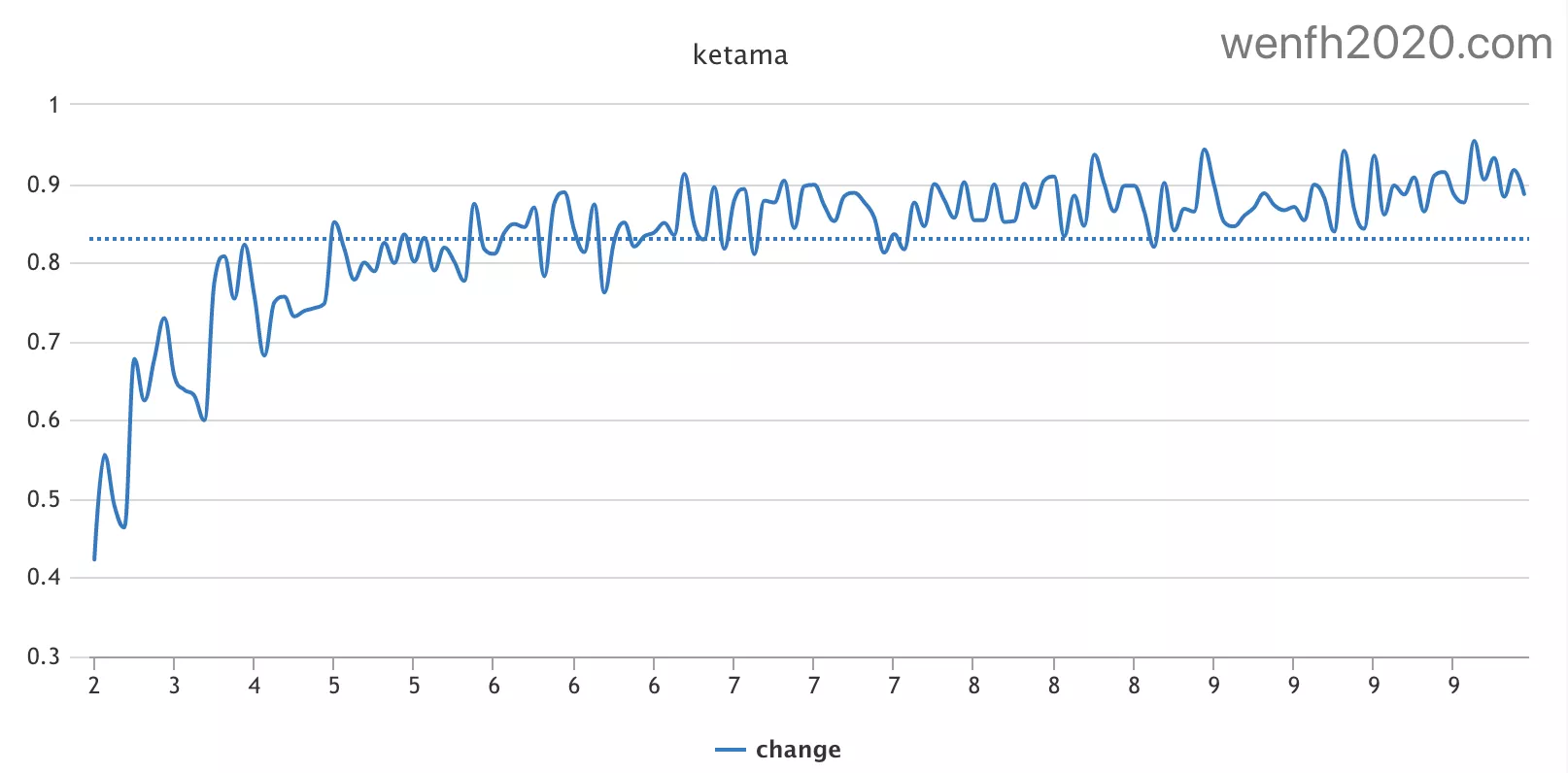
2.2. 增加节点
增加节点后,旧节点上的数据变化情况,下图主要显示了每次增加节点后,数据仍然路由到原节点的百分比,节点越多,节点上的数据变化越稳定。
2.3. 删除节点
删除节点,剩余节点上的原有数据位置没有变化,被删除节点上的数据,将重新路由到剩余节点中去。重新路由的数据分布情况请参考上面说的 数据分布。
既然旧节点上的原有数据没变化就不上图了,这也符合一致性哈希算法预期。
3. 源码分析
3.1. 数据结构
- 为了节点发现,发送给 zookeeper 的节点信息,为了方便服务之间数据交换,设计成 protobuf 结构。
1
2
3
4
5
6
7
8
/* 节点发现信息。 */
message zk_node {
string path = 1; /* zookeeper path. store which return from zk. */
string type = 2 ; /* node type. */
string ip = 3; /* node ip. */
uint32 port = 4; /* node port. */
uint32 worker_cnt = 5; /* node worker count. */
}
- 真实节点的节点信息。保存了与它建立映射的虚拟节点,方便删除操作。
1
2
3
4
5
6
7
8
9
/* 真实节点信息。 */
typedef struct node_s {
std::string id; /* node id: "ip:port.worker_index" */
std::string type; /* node type. */
std::string ip; /* node ip. */
int port; /* node port. */
std::vector<uint32_t> vnodes; /* virtual nodes which point to me. */
double active_time; /* time for checking online. */
} node_t;
- 一致性哈希节点管理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Nodes {
private:
/* 真实节点信息。
* key: node_id, value: node info. */
std::unordered_map<std::string, node_t*> m_nodes;
/* 虚拟节点到真实节点的映射。
* key: vnode(hash) -> node. */
typedef std::map<uint32_t, node_t*> VNODE2NODE_MAP;
/* 服务集群里有不同类型的服务节点,需要根据节点类型分类节点。
* key: node type, value: (vnodes -> node) */
std::unordered_map<std::string, VNODE2NODE_MAP> m_vnodes;
};
3.2. 接口
3.2.1. 添加节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
bool Nodes::add_node(const std::string& node_type, const std::string& ip, int port, int worker) {
LOG_INFO("add node, node type: %s, ip: %s, port: %d, worker: %d",
node_type.c_str(), ip.c_str(), port, worker);
/* 每个真实节点信息,将它的数据格式化出一个对应 id(ip:port.worker_index),方便查找。*/
std::string node_id = format_identity(ip, port, worker);
if (m_nodes.find(node_id) != m_nodes.end()) {
LOG_DEBUG("node (%s) has been added!", node_id.c_str());
return true;
}
/* 真实节点信息。 */
node_t* node;
/* 虚拟节点数组。 */
std::vector<uint32_t> vnodes;
/* 虚拟节点映射真实节点。 */
VNODE2NODE_MAP& vnode2node = m_vnodes[node_type];
int old_vnode_cnt = vnode2node.size();
/* 为真实节点生成虚拟节点。 */
vnodes = gen_vnodes(node_id);
node = new node_t{node_id, node_type, ip, port, vnodes, time_now()};
/* 虚拟节点与真实节点建立映射。 */
for (auto& v : vnodes) {
if (!vnode2node.insert({v, node}).second) {
LOG_WARN(
"duplicate virtual nodes! "
"vnode: %lu, node type: %s, ip: %s, port: %d, worker: %d.",
v, node_type.c_str(), ip.c_str(), port, worker);
continue;
}
}
if (vnode2node.size() == old_vnode_cnt) {
LOG_ERROR("add virtual nodes failed! node id: %s, node type: %s",
node->id.c_str(), node->type.c_str());
SAFE_DELETE(node);
return false;
}
m_nodes[node_id] = node;
return true;
}
3.2.2. 删除节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
bool Nodes::del_node(const std::string& node_id) {
LOG_INFO("delete node: %s", node_id.c_str());
auto it = m_nodes.find(node_id);
if (it == m_nodes.end()) {
return false;
}
/* clear vnode. */
node_t* node = it->second;
auto itr = m_vnodes.find(node->type);
if (itr != m_vnodes.end()) {
/* 删除真实节点映射的所有虚拟节点。 */
for (auto& v : node->vnodes) {
itr->second.erase(v);
}
}
/* 删除真实节点。 */
LOG_INFO("delete node: %s done!", node->id.c_str());
delete node;
m_nodes.erase(it);
return true;
}
3.2.3. 获取节点
获取节点接口性能测试,100w 个调用耗时 0.642390 s,效率还过得去吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
node_t* Nodes::get_node_in_hash(const std::string& node_type, const std::string& obj) {
auto it = m_vnodes.find(node_type);
if (it == m_vnodes.end()) {
return nullptr;
}
/* obj 通过哈希算法,生成一个 uint32_t 的哈希键。 */
uint32_t hash_key = hash(obj);
const VNODE2NODE_MAP& vnode2node = it->second;
if (vnode2node.size() == 0) {
LOG_WARN(
"can't not find node in virtual nodes. node type: %s, obj: %s, hash key: %lu",
node_type.c_str(), obj.c_str(), hash_key);
return nullptr;
}
/* 顺时针查找不小于哈希键的最小的一个虚拟节点(虚拟节点是一个 uint32_t 数值)。*/
auto itr = vnode2node.lower_bound(hash_key);
if (itr == vnode2node.end()) {
itr = vnode2node.begin();
}
return itr->second;
}
主要性能损耗,在节点数据的查找上。系统就是这样,每添加一个新的功能,都会蚕食系统的整体性能,累积下来,损耗就是一个很可观的数字了。且看节点数据通信火焰图,这个接口的调用就占了整个系统性能的 2.81%。

火焰图参考:如何生成火焰图🔥
3.3. 算法实现
3.3.1. 虚拟节点
创建分布均匀的散列虚拟节点。为了兼顾性能,默认每个真实节点生成对应的 200 个虚拟节点,虚拟节点其实是一个 uint32_t 数据。
为了让它能散列开,分布均匀,采用对真实节点信息进行组合,生成 16 个字节的 md5 字符串,该字符串分为 4 组,每组 4 个字节,4 个字节的字符串通过移位组合成 4 个字节的 uint32 key。因为 md5 字符串里面的字母都是随机的,理论上,随机产生的数据应该是均匀的。这样 200 个散列 key 能映射到实体节点上,这样比较符合一致性哈希算法原理。
这个虚拟节点算法是开源者贡献,经过测试,比较符合算法预期。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
std::vector<uint32_t> Nodes::gen_vnodes(const std::string& node_id) {
std::string s;
int hash_point = 4;
std::vector<uint32_t> vnodes;
for (int i = 0; i < m_vnode_cnt / hash_point; i++) {
s = md5(format_str("%d@%s#%d", m_vnode_cnt - i, node_id.c_str(), i));
for (int j = 0; j < hash_point; j++) {
uint32_t v = ((uint32_t)(s[3 + j * hash_point] & 0xFF) << 24) |
((uint32_t)(s[2 + j * hash_point] & 0xFF) << 16) |
((uint32_t)(s[1 + j * hash_point] & 0xFF) << 8) |
(s[j * hash_point] & 0xFF);
vnodes.push_back(v);
}
}
return vnodes;
}
3.4. 哈希键转换
提供三种类型的哈希算法,默认是 fnv1a_64,根据业务场景,选择对应冲突率比较小的。
1
2
3
4
5
6
7
8
9
10
uint32_t Nodes::hash(const std::string& obj) {
if (m_ha == HASH_ALGORITHM::FNV1_64) {
return hash_fnv1_64(obj.c_str(), obj.size());
} else if (m_ha == HASH_ALGORITHM::MURMUR3_32) {
return murmur3_32(obj.c_str(), obj.size(), 0x000001b3);
} else {
return hash_fnv1a_64(obj.c_str(), obj.size());
}
}