需求:限制用户一段时间内的发包数量。
实现:想了不少方案,最终决定使用 时间轮 实现。
1. 时间轮
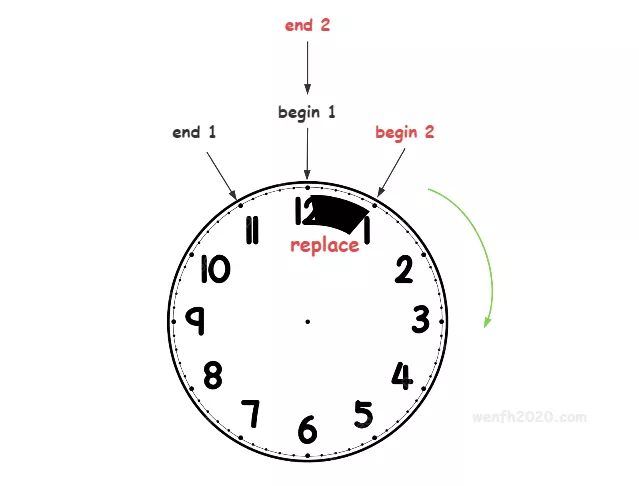
时钟,大家应该不陌生,12 个刻度,每个大刻度 5 分钟。无论时钟上的针怎么转,都在 12 个刻度范围内,所以这个思路非常适合解决一段时间内的业务逻辑统计,而且非常高效。
- 通过数组实现时间轮。
- 数组每个下标表示一个刻度值。
- 数组大小表示刻度个数。
- 时间轮顺时针转动,当下标轮询到数组的结尾,重新指向数组开始位置,从而形成一个时间环。
- 时间轮转动过程中,向前转动,会覆盖以前的旧数据。
下图是时间轮转一个刻度的图示。
2. 实现
核心算法:根据时间转动的轮子: CRateLimitMgr::RotateWheel。
- nSlots:槽个数,表示刻度个数。
- nSlotDuration:每个槽代表的时间段(单位:秒)
- nMsgLimitCnt: 整个时间段内,限制的操作数量。
- 头文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
// 管理对象一个时间段内的操作数量
class CRateLimitMgr {
public:
CRateLimitMgr() {}
virtual ~CRateLimitMgr() {}
// nSlots: 槽个数
// nSlotDuration: 每个槽的时间段(单位:秒)
// nMsgLimitCnt: (nSlots * nSlotDuration)时间段内允许操作消息的条数
bool Init(int nSlots, int nSlotDuration, int nMsgLimitCnt);
// 增加对象统计数量
bool IncrCnt(const std::string& strObjId);
// 对象是否已被限制
bool IsLimited(const std::string& strObjId);
private:
// 被限制的对象
struct SLimitObject {
explicit SLimitObject(const std::string& strId, int nSlots,
const std::chrono::steady_clock::time_point& tp)
: m_strId(strId), m_vecWheel(nSlots, 0), m_tpLastRotation(tp) {}
std::string m_strId; // 对象 ID
int m_nCurSlot = 0; // 时间轮,当前指向槽位置
int m_nMsgTotalCnt = 0; // 消息总数
std::vector<int> m_vecWheel; // 记录时间轮每个槽上的操作数量
// 记录最近一次执行轮换操作的时间点
std::chrono::steady_clock::time_point m_tpLastRotation;
};
// 转动时间轮,重算对象统计的数据
void RotateWheel(std::shared_ptr<SLimitObject>& obj);
private:
std::mutex m_mtx;
int m_nSlots = 0; // 时间轮:槽个数
int m_nSlotDuration = 0; // 时间轮:每个槽的时间段(精度:秒)
int m_nMsgLimitCnt = 0; //(nSlots * nSlotDuration)时间段内允许操作消息的条数
// 哈希结构记录限制对象,查询效率高
std::unordered_map<std::string, std::shared_ptr<SLimitObject>> m_umapObj;
};
- 源文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
bool CRateLimitMgr::Init(int nSlots, int nSlotDuration, int nMsgLimitCnt) {
if (nSlots <= 0 || nSlotDuration <= 0 || nMsgLimitCnt <=0) {
return false;
}
std::lock_guard<std::mutex> lock(m_mtx);
m_nSlots = nSlots;
m_nMsgLimitCnt = nMsgLimitCnt;
m_nSlotDuration = nSlotDuration;
}
bool CRateLimitMgr::IncrCnt(const std::string& strObjId) {
std::lock_guard<std::mutex> lock(m_mtx);
auto it = m_umapObj.find(strObjId);
if (it == m_umapObj.end()) {
auto obj = std::make_shared<SLimitObject>(strObjId, m_nSlots,
std::chrono::steady_clock::now());
it = m_umapObj.insert(std::make_pair(strObjId, obj)).first;
}
auto& obj = it->second;
RotateWheel(obj);
if (obj->m_nMsgTotalCnt >= m_nMsgLimitCnt) {
return false;
}
obj->m_vecWheel[obj->m_nCurSlot]++;
obj->m_nMsgTotalCnt++;
return true;
}
bool CRateLimitMgr::IsLimited(const std::string& strObjId) {
std::lock_guard<std::mutex> lock(m_mtx);
auto it = m_umapObj.find(strObjId);
if (it == m_umapObj.end()) {
return false;
}
auto& obj = it->second;
RotateWheel(obj);
return obj->m_nMsgTotalCnt >= m_nMsgLimitCnt;
}
void CRateLimitMgr::RotateWheel(std::shared_ptr<SLimitObject>& obj) {
// 获取当前时间点
auto tpNow = std::chrono::steady_clock::now();
// 计算自上次轮换以来经过的秒数
auto nElapsed = std::chrono::duration_cast<std::chrono::seconds>(
tpNow - obj->m_tpLastRotation).count();
// 计算经过的完整轮盘槽数
int nElapsedSlots = nElapsed / m_nSlotDuration;
// 如果经过的槽数大于 0,则需要更新轮盘(顺时针)
if (nElapsedSlots > 0) {
// 计算实际需要更新的槽数,不能超过总槽数
int nSlotsToUpdate = std::min(nElapsedSlots, m_nSlots);
// 遍历需要更新的槽数
for (int i = 1; i <= nSlotsToUpdate; i++) {
// 计算当前槽的索引
int nSlotIndex = (obj->m_nCurSlot + i) % m_nSlots;
// 从总消息计数中减去当前槽的消息数
obj->m_nMsgTotalCnt -= obj->m_vecWheel[nSlotIndex];
// 将当前槽的消息数重置为 0
obj->m_vecWheel[nSlotIndex] = 0;
}
// 更新当前槽的索引
obj->m_nCurSlot = (obj->m_nCurSlot + nSlotsToUpdate) % m_nSlots;
// 更新上次轮换时间点,设置为当前槽的开始时间
obj->m_tpLastRotation = tpNow - std::chrono::seconds(
nElapsed % m_nSlotDuration);
}
}
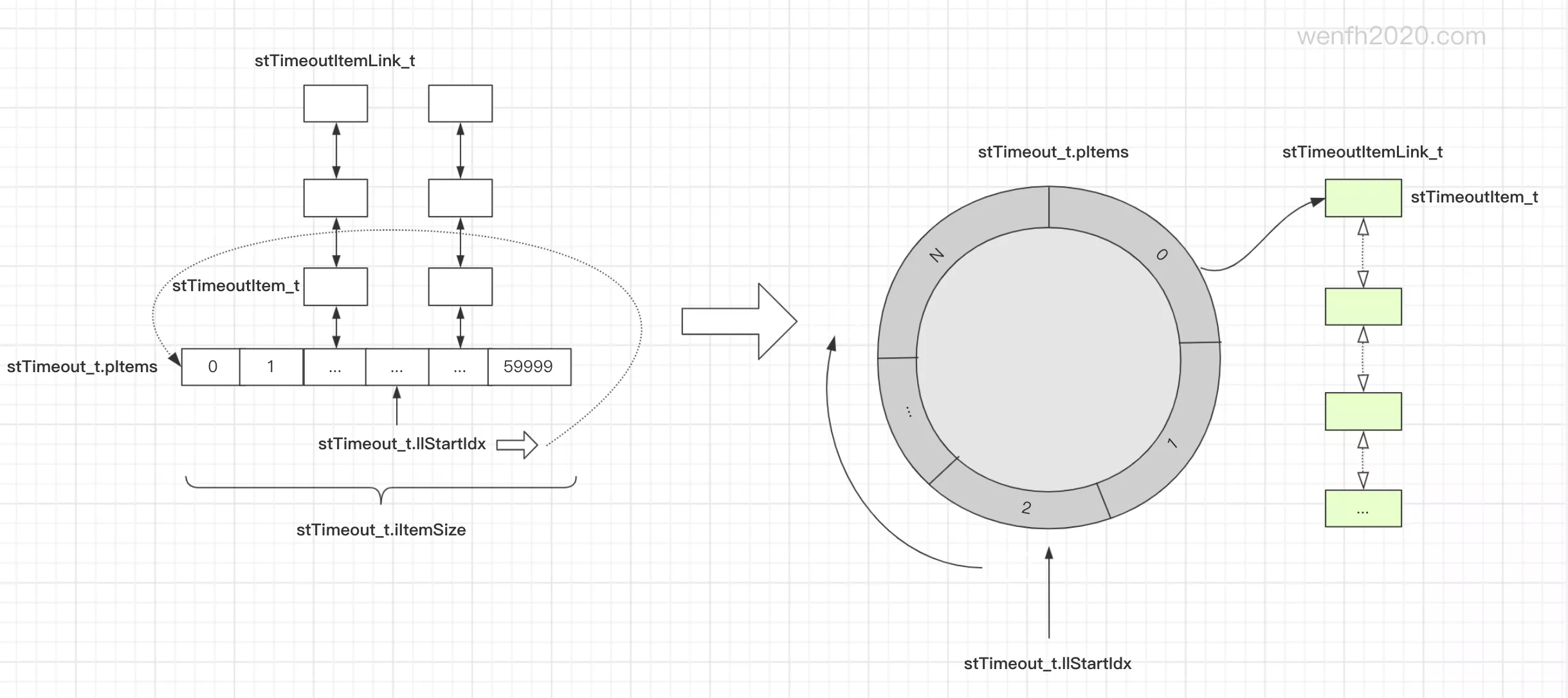
3. 环形数据结构
时间轮由环形数组实现,思路非常巧妙,其中环形数据结构,在很多开源项目中也有广泛应用。
3.1. 定时器
采用时间轮实现的策略并不少见,例如定时器。
- libco 定时器:60 * 1000 大小的数组,每一毫秒一个刻度,轻松实现 1 分钟以内的定时任务。
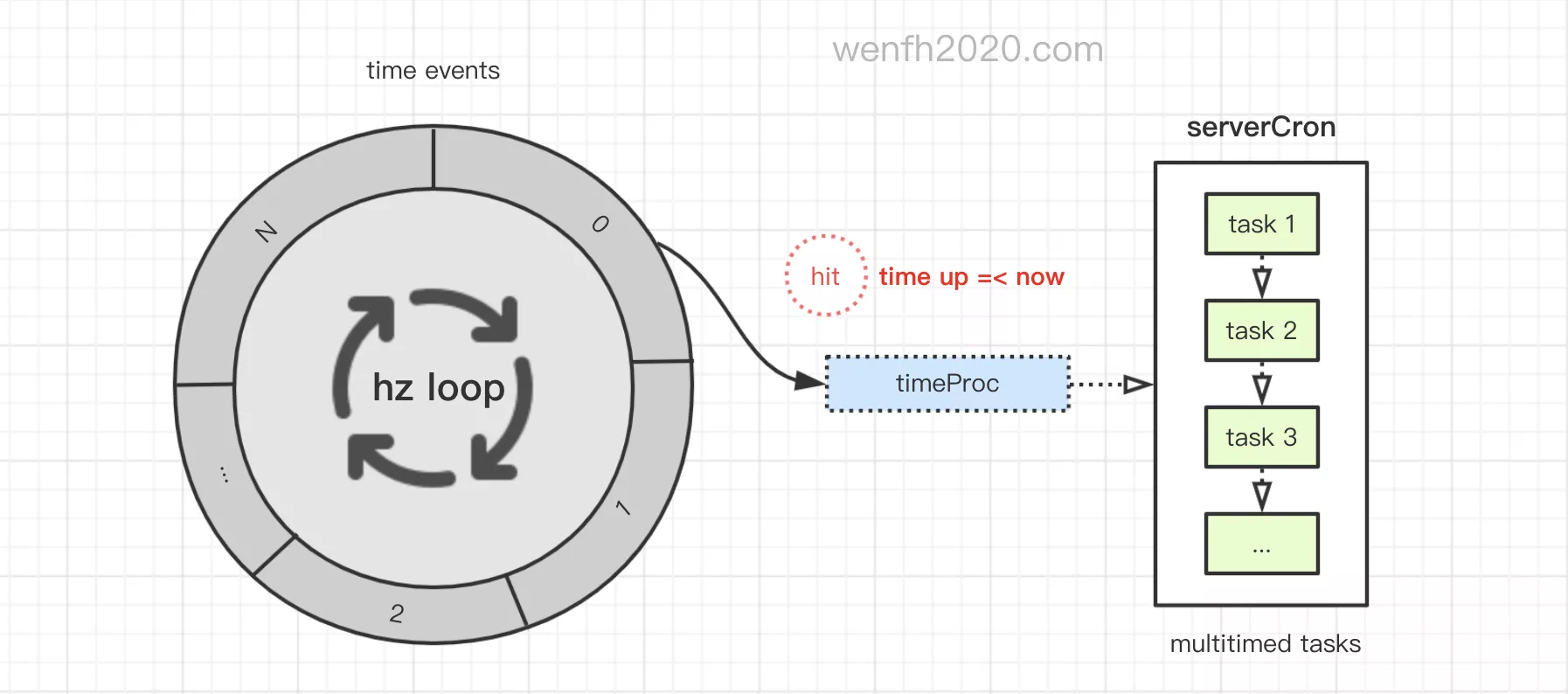
- redis 多定时任务设计。
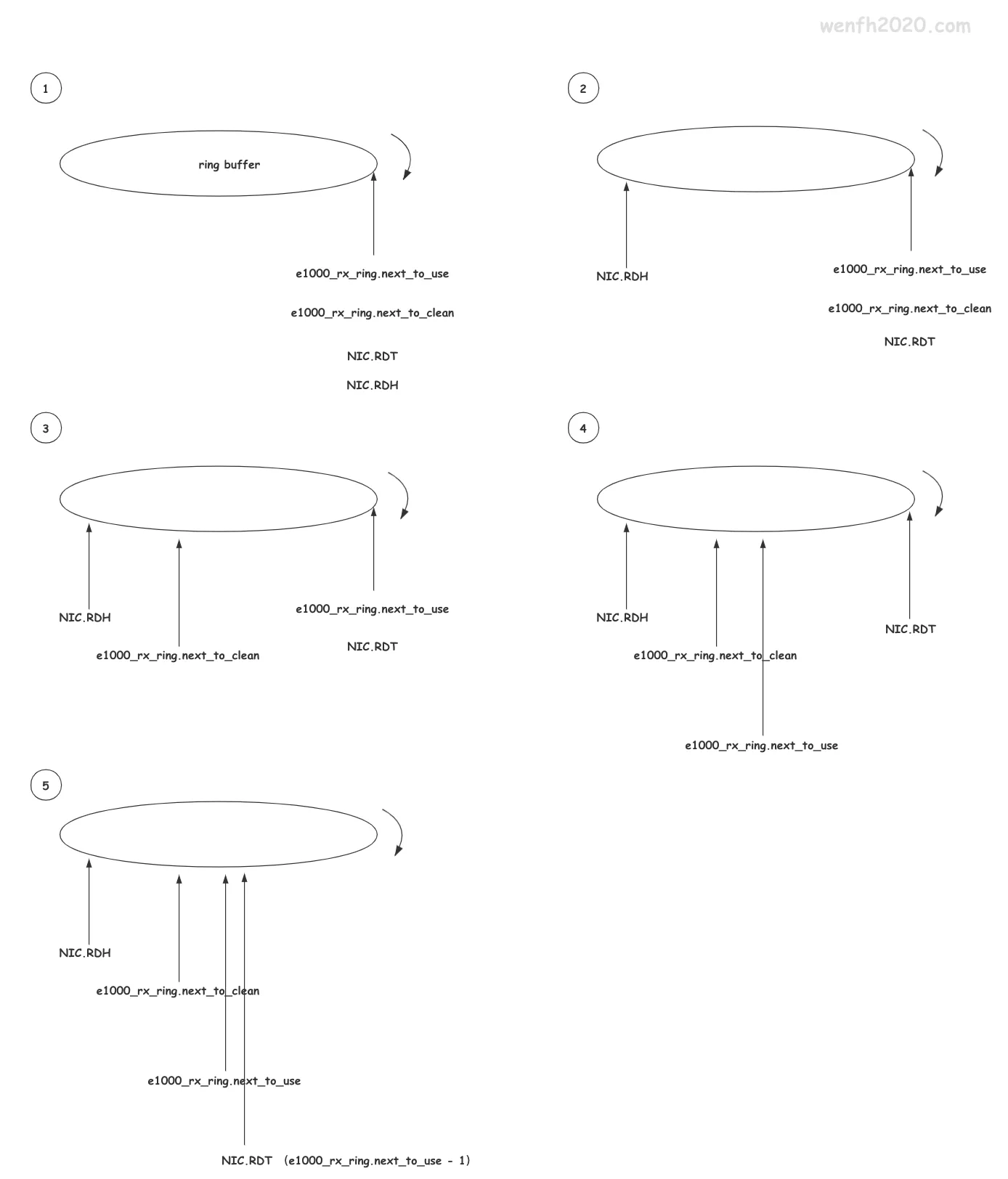
3.2. 环形缓冲区
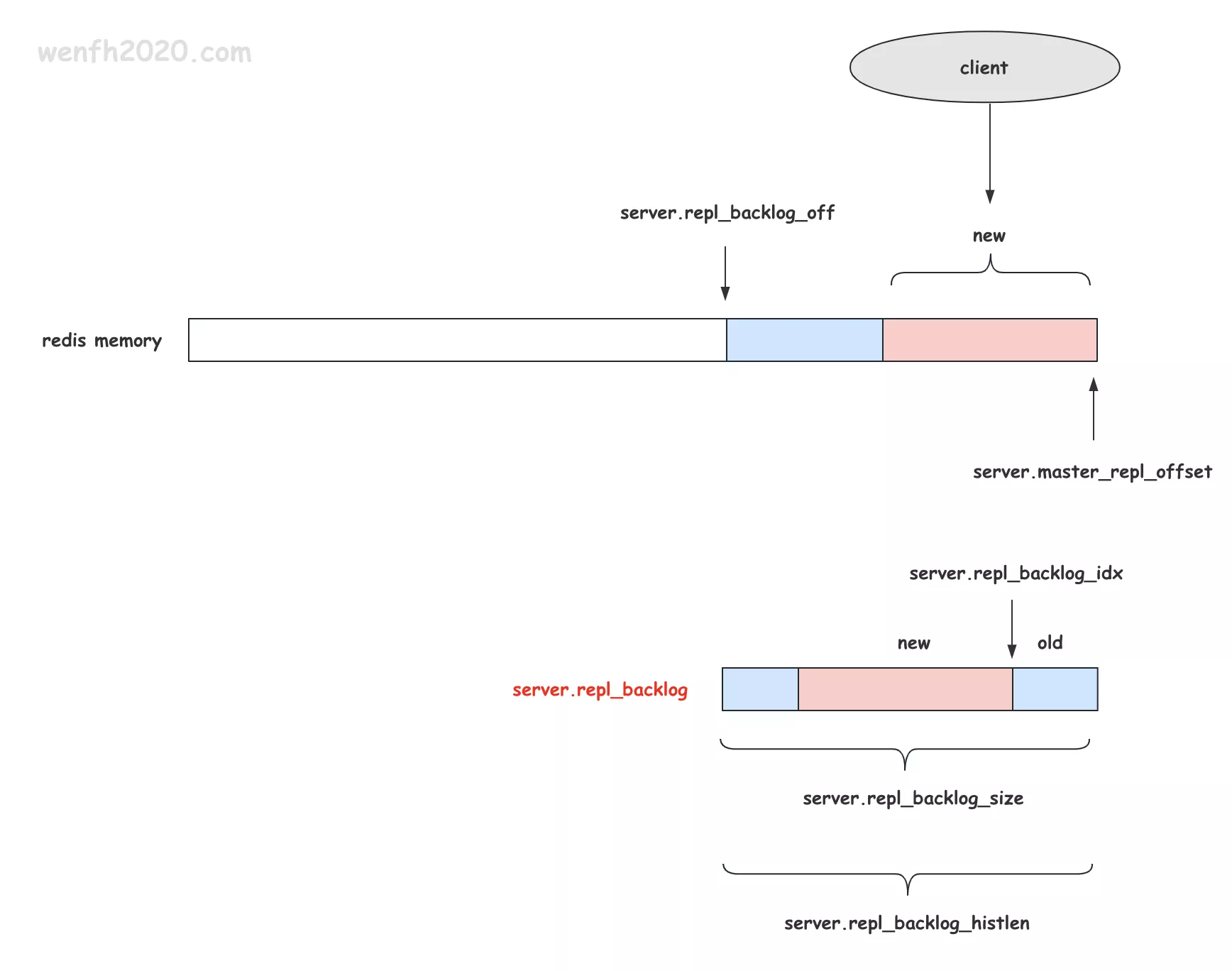
- redis 复制积压缓冲区。master 把需要复制到 slave 的数据,填充到积压缓冲区里。当复制双方增量复制时,master 从缓冲区中取增量数据,发送给 slave。
- linux 网卡环形缓冲区(ring buffer),系统分配内存缓冲区,映射为 DMA 内存,提供网卡直接访问。