
走读网络协议栈 tcp 发送数据的内核源码(Linux - 5.0.1 下载)。
数据发送实现比较复杂,牵涉到 OSI 模型所有分层,所以需要对每个分层都要有所了解,才能理清工作流程和实现思路。
最好的两个参考资料:
书籍:《Linux 内核源码剖析 - TCP/IP 实现》 上下两册。
1. 通信分层
- OSI 模型 / TCP/IP 分层模型。详细分层原理请参考:网络分层概述。
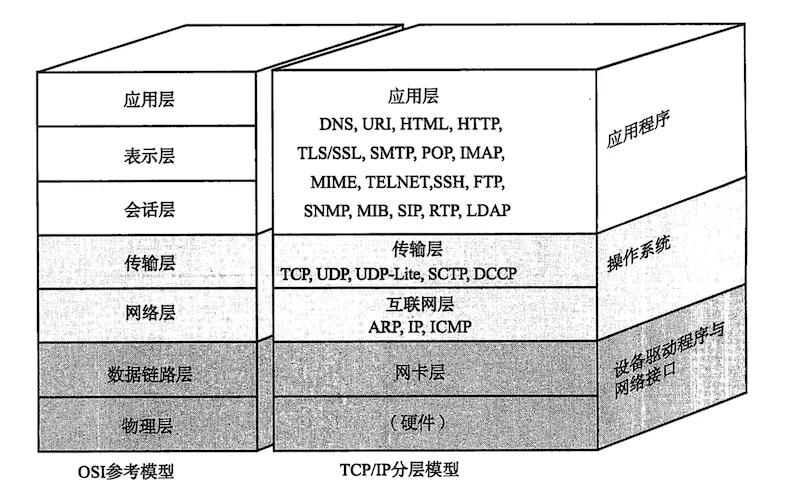
图片来源:《图解 TCP_IP》
-
内核函数堆栈。
write 发送数据,详细工作流程可以参考内核函数堆栈。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
__dev_queue_xmit(struct sk_buff * skb, struct net_device * sb_dev) (/root/linux-5.0.1/net/core/dev.c:3891)
dev_queue_xmit(struct sk_buff * skb) (/root/linux-5.0.1/net/core/dev.c:3897)
# 网络介质层(数据发往设备)。
neigh_hh_output() (/root/linux-5.0.1/include/net/neighbour.h:498)
neigh_output() (/root/linux-5.0.1/include/net/neighbour.h:506)
# 邻居子系统(链路层)。
ip_finish_output2(struct net * net, struct sock * sk, struct sk_buff * skb) (/root/linux-5.0.1/net/ipv4/ip_output.c:229)
NF_HOOK_COND() (/root/linux-5.0.1/include/linux/netfilter.h:278)
ip_output(struct net * net, struct sock * sk, struct sk_buff * skb) (/root/linux-5.0.1/net/ipv4/ip_output.c:405)
# 网络 ip 层。
__tcp_transmit_skb(struct sock * sk, struct sk_buff * skb, int clone_it, gfp_t gfp_mask, u32 rcv_nxt) (/root/linux-5.0.1/net/ipv4/tcp_output.c:1032)
tcp_transmit_skb() (/root/linux-5.0.1/net/ipv4/tcp_output.c:1176)
tcp_write_xmit(struct sock * sk, unsigned int mss_now, int nonagle, int push_one, gfp_t gfp) (/root/linux-5.0.1/net/ipv4/tcp_output.c:2402)
__tcp_push_pending_frames(struct sock * sk, unsigned int cur_mss, int nonagle) (/root/linux-5.0.1/net/ipv4/tcp_output.c:2578)
tcp_push(struct sock * sk, int flags, int mss_now, int nonagle, int size_goal) (/root/linux-5.0.1/net/ipv4/tcp.c:735)
tcp_sendmsg_locked(struct sock * sk, struct msghdr * msg, size_t size) (/root/linux-5.0.1/net/ipv4/tcp.c:1406)
tcp_sendmsg(struct sock * sk, struct msghdr * msg, size_t size) (/root/linux-5.0.1/net/ipv4/tcp.c:1443)
# tcp 传输层。
sock_sendmsg_nosec() (/root/linux-5.0.1/net/socket.c:622)
sock_sendmsg(struct socket * sock, struct msghdr * msg) (/root/linux-5.0.1/net/socket.c:632)
sock_write_iter(struct kiocb * iocb, struct iov_iter * from) (/root/linux-5.0.1/net/socket.c:901)
# socket -> sock。
call_write_iter() (/root/linux-5.0.1/include/linux/fs.h:1863)
new_sync_write() (/root/linux-5.0.1/fs/read_write.c:474)
__vfs_write(struct file * file, const char * p, size_t count, loff_t * pos) (/root/linux-5.0.1/fs/read_write.c:487)
vfs_write(struct file * file, const char * buf, size_t count, loff_t * pos) (/root/linux-5.0.1/fs/read_write.c:549)
# 虚拟文件系统管理。
ksys_write(unsigned int fd, const char * buf, size_t count) (/root/linux-5.0.1/fs/read_write.c:598)
do_syscall_64(unsigned long nr, struct pt_regs * regs) (/root/linux-5.0.1/arch/x86/entry/common.c:290)
entry_SYSCALL_64() (/root/linux-5.0.1/arch/x86/entry/entry_64.S:175)
# 系统调用。
...
# 应用层。
- 函数调用层次。

- 通信分层数据包封装格式。
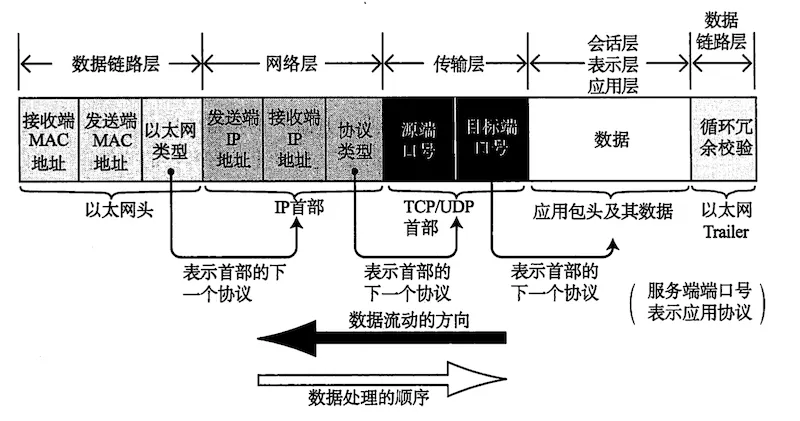
图片来源:《图解 TCP_IP》
2. 数据发送层次
2.1. VFS
- 文件与 socket。socket 是 Linux 一种 特殊文件,socket 在创建时(
sock_alloc_file)会关联对应的文件处理,所以我们在 TCP 通信过程中,发送数据,用户层调用write接口,在内核里实际是调用了sock_write_iter接口。
详细参考:《[内核源码] 网络协议栈 - socket (tcp)》 - 4.1 文件部分

图片来源:《Linux 内核源代码情景分析》- 第五章 - 文件系统
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
/* ./include/linux/fs.h */
struct file_operations {
struct module *owner;
...
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
...
} __randomize_layout;
/* ./net/socket.c */
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
...
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
...
};
/* net/socket.c */
struct file *sock_alloc_file(struct socket *sock, int flags, const char *dname) {
...
file = alloc_file_pseudo(SOCK_INODE(sock), sock_mnt, dname,
O_RDWR | (flags & O_NONBLOCK),
&socket_file_ops);
...
/* 文件和socket相互建立联系。 */
sock->file = file;
file->private_data = sock;
return file;
}
- 数据发送逻辑。发送数据从用户层通过系统调用进入到内核逻辑,通过 fd 文件描述符,找到对应的文件,然后再找到与文件关联的对应的 socket,进行发送数据。
1
write() --> fd --> file --> sock_sendmsg()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count) {
return ksys_write(fd, buf, count);
}
ssize_t ksys_write(unsigned int fd, const char __user *buf, size_t count) {
struct fd f = fdget_pos(fd);
...
if (f.file) {
...
ret = vfs_write(f.file, buf, count, &pos);
...
}
...
}
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos) {
...
ret = __vfs_write(file, buf, count, pos);
...
}
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count,
loff_t *pos) {
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
/* sock_write_iter */
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}
static ssize_t new_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos) {
...
ret = call_write_iter(filp, &kiocb, &iter);
...
}
static inline ssize_t call_write_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter) {
/* sock_write_iter */
return file->f_op->write_iter(kio, iter);
}
static ssize_t sock_write_iter(struct kiocb *iocb, struct iov_iter *from) {
struct file *file = iocb->ki_filp;
struct socket *sock = file->private_data;
struct msghdr msg = {
.msg_iter = *from,
.msg_iocb = iocb
};
ssize_t res;
...
res = sock_sendmsg(sock, &msg);
*from = msg.msg_iter;
return res;
}
int sock_sendmsg(struct socket *sock, struct msghdr *msg) {
int err = security_socket_sendmsg(sock, msg,
msg_data_left(msg));
return err ?: sock_sendmsg_nosec(sock, msg);
}
2.2. socket
fd –> file –> socket –> sock –> tcp
- 接口调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/* net/socket.c */
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg) {
/* inet_sendmsg */
int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg));
...
}
/* net/ipv4/af_inet.c */
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size) {
struct sock *sk = sock->sk;
...
return sk->sk_prot->sendmsg(sk, msg, size);
}
/* net/ipv4/tcp.c */
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size) {
...
ret = tcp_sendmsg_locked(sk, msg, size);
...
}
- sock 操作对象。
1
socket.ops --> inetsw_array[socket.type].ops --> inet_stream_ops
- 结构关联。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
/* ./net/ipv4/af_inet.c */
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
...
.sendmsg = inet_sendmsg,
...
};
/* ./net/ipv4/tcp_ipv4.c */
struct proto tcp_prot = {
.name = "TCP",
...
.sendmsg = tcp_sendmsg,
...
};
/* af_inet.c */
static struct inet_protosw inetsw_array[] = {
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK,
},
...
};
struct socket {
...
short type;
...
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};
/* inet_stream_ops 与 socket.ops 关联。 */
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern) {
...
struct inet_protosw *answer;
struct proto *answer_prot;
...
/* 查找对应的协议。 */
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
...
}
...
/* 关联。 */
sock->ops = answer->ops;
...
}
/* tcp_prot 与 socket 关联。 */
struct sock *sk_alloc(struct net *net, int family, gfp_t priority,
struct proto *prot, int kern) {
struct sock *sk;
...
sk->sk_prot = sk->sk_prot_creator = prot;
...
}
2.3. TCP 传输层
2.3.1. sk_buff
socket 数据缓存,sk_buff 用于保存接收或者发送的数据报文信息,目的为了方便网络协议栈的各层间进行无缝传递数据。sk_buff 数据存储的两个区域:
data:连续数据区(数据拷贝)。skb_shared_info:共享数据区。
详细请参考:《Linux 内核源码剖析 - TCP/IP 实现》- 第三章 - 套接口缓存

图片来源:《Linux 内核源码剖析 - TCP/IP 实现》- 3.2.3

图片来源:《Linux 内核源码剖析 - TCP/IP 实现》- 3.2.3
tcp 的数据输出,数据首先是从应用层在流入内核,内核会将应用层传入的数据进行拷贝,拷贝到 sk_buff 链表中进行发送,参考下图。
sk_write_queue:发送队列的双向链表头。sk_send_head:指向发送队列中下一个要发送的数据包。

图片来源:《Linux 内核源码剖析 - TCP/IP 实现》- 30.1
2.3.2. MTU / MSS
网络上传输的网络包大小是有限制的,理解 MTU 和 MSS 这两个限制概念。
- MTU:Maximum Transmission Unit。
- MSS:Max Segment Size。
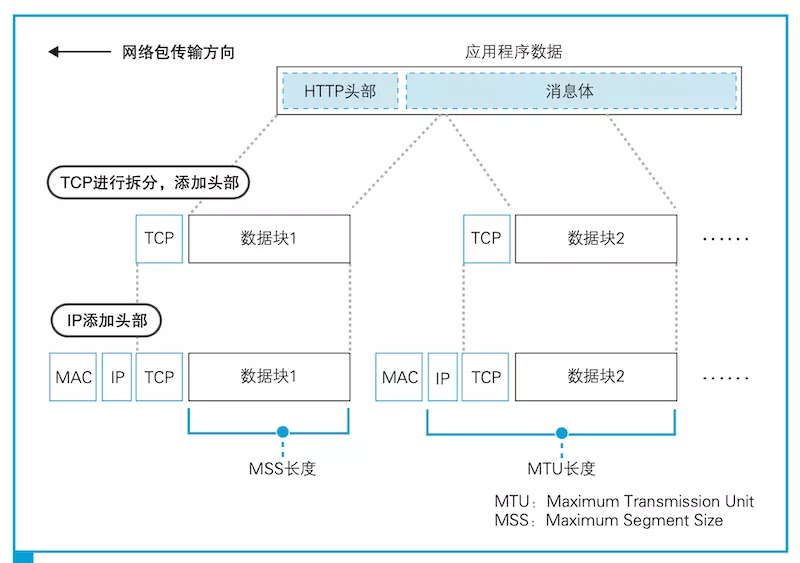
图片来源:《网络是怎样连接的》
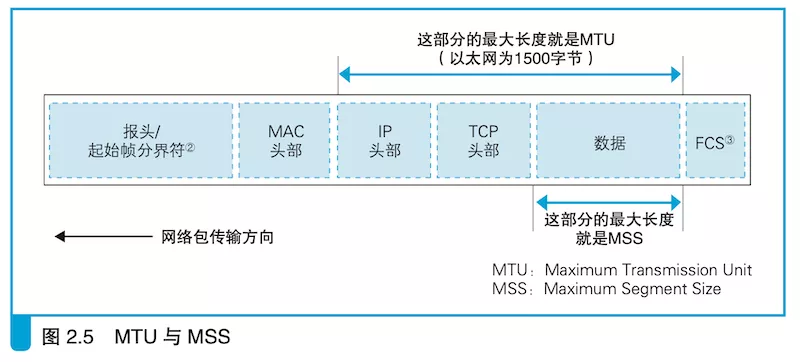
图片来源:《网络是怎样连接的》
2.3.3. 数据发送逻辑
tcp_sendmsg_locked主要工作是要把用户层的数据填充到内核的发送队列进行发送。
源码注释参考:
《Linux 内核源码剖析 - TCP/IP 实现》- 下册 - 第 30 章 TCP 的输出。

图片来源:《Linux 内核源码剖析 - TCP/IP 实现》- 下册 - 30.3.3 传输接口层的实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size) {
struct tcp_sock *tp = tcp_sk(sk);
struct ubuf_info *uarg = NULL;
struct sk_buff *skb;
struct sockcm_cookie sockc;
int flags, err, copied = 0;
int mss_now = 0, size_goal, copied_syn = 0;
bool process_backlog = false;
bool zc = false;
long timeo;
...
/* 获取等待的时间,如果阻塞模式,获取超时时间,非阻塞为 0。 */
timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
...
/* Wait for a connection to finish. One exception is TCP Fast Open
* (passive side) where data is allowed to be sent before a connection
* is fully established. */
if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) &&
!tcp_passive_fastopen(sk)) {
/* 等待连接建立。 */
err = sk_stream_wait_connect(sk, &timeo);
if (err != 0)
goto do_error;
}
...
restart:
/* 获取当前有效的 mss。
* mtu: max transmission unit.
* mss: max segment size. (mtu - (ip header size) - (tcp header size)).
* GSO: Generic Segmentation Offload.
* size_goal 表示数据报到达网络设备时,数据段的最大长度,该长度用来分割数据,
* TCP 发送段时,每个 SKB 的大小不能超过该值。
* 不支持 GSO 情况下, size_goal 就等于 MSS,如果支持 GSO,
* 那么 size_goal 是 mss 的整数倍,数据报发送到网络设备后再由网络设备根据 MSS 进行分割。
*/
mss_now = tcp_send_mss(sk, &size_goal, flags);
...
/* 将 msg 数据拷贝到 skb,等待发送。 */
while (msg_data_left(msg)) {
int copy = 0;
/* 从等待发送数据链表中,取最后一个 skb,将将要发送的数据填充到 skb,等待发送。 */
skb = tcp_write_queue_tail(sk);
if (skb)
/* size_goal - skb->len 判断 skb 是否已满,大于零说明 skb 还有剩余空间,
* 还能往 skb 追加填充数据,组成一个 mss 的数据包,发往 ip 层。 */
copy = size_goal - skb->len;
/* 如果当前 skb 空间不足,那么要重新创建一个 sk_buffer 装载数据。
或者被设置了 eor 标记不能合并。*/
if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) {
bool first_skb;
int linear;
new_segment:
/* 如果发送队列的总大小(sk_wmem_queued)>= 发送缓存上限(sk_sndbuf)
* 或者发送缓冲区中尚未发送的数据量,超过了用户的设置值,那么进入等待状态。*/
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf;
/* 重新分配一个 sk_buffer 结构。 */
skb = sk_stream_alloc_skb(sk, 0, sk->sk_allocation,
tcp_rtx_and_write_queues_empty(sk));
...
/* 将 skb 添加进发送队列尾部。 */
skb_entail(sk, skb);
/* skb 数据缓冲区大小是 size_goal。 */
copy = size_goal;
...
}
/* Try to append data to the end of skb. */
if (copy > msg_data_left(msg))
copy = msg_data_left(msg);
/* skb 的线性存储区底部是否还有空间。 */
if (skb_availroom(skb) > 0 && !zc) {
/* We have some space in skb head. Superb! */
copy = min_t(int, copy, skb_availroom(skb));
/* 将数据拷贝到连续的数据区域。*/
err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy);
if (err)
goto do_fault;
} else if (!zc) {
bool merge = true;
int i = skb_shinfo(skb)->nr_frags;
struct page_frag *pfrag = sk_page_frag(sk);
...
copy = min_t(int, copy, pfrag->size - pfrag->offset);
...
/* 如果 skb 的线性存储区底部已经没有空间了,
* 将数据拷贝到 skb 的 struct skb_shared_info 结构指向的不需要连续的页面区域。 */
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
pfrag->page,
pfrag->offset,
copy);
...
pfrag->offset += copy;
} else {
/* zero copy. */
}
/* 如果复制的数据长度为零(或者第一次拷贝),那么取消 PSH 标志。 */
if (!copied)
TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH;
/* 更新发送队列的最后一个序号 write_seq。 */
tp->write_seq += copy;
/* 更新 skb 的结束序号。 */
TCP_SKB_CB(skb)->end_seq += copy;
/* 初始化 gso 分段数 gso_segs. */
tcp_skb_pcount_set(skb, 0);
copied += copy;
if (!msg_data_left(msg)) {
if (unlikely(flags & MSG_EOR))
/* #define MSG_EOR 0x80 -- End of record */
TCP_SKB_CB(skb)->eor = 1;
/* 用户层数据已经拷贝完毕,进行发送。 */
goto out;
}
/* 如果当前 skb 还可以填充数据,或者发送的是带外数据,或者使用 tcp repair 选项,
* 那么继续拷贝数据,先不发送。*/
if (skb->len < size_goal || (flags & MSG_OOB) || unlikely(tp->repair))
continue;
/* 检查是否必须立即发送。 */
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
/* 积累的数据包数量太多了,需要发送出去。*/
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
/* 如果是第一个网络包,那么只发送当前段。 */
tcp_push_one(sk, mss_now);
continue;
...
wait_for_sndbuf:
/* 发送队列中段数据总长度已经达到了发送缓冲区的长度上限,那么设置 SOCK_NOSPACE。*/
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
wait_for_memory:
/* 在进入睡眠等待前,如果已有数据从用户空间复制过来,那么通过 tcp_push 先发送出去。 */
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
/* 进入睡眠,等待内存空闲信号唤醒。 */
err = sk_stream_wait_memory(sk, &timeo);
if (err != 0)
goto do_error;
/* 睡眠后 MSS 和 TSO 段长可能会发生变化,重新计算。 */
mss_now = tcp_send_mss(sk, &size_goal, flags);
}
...
out:
/* 在连接状态下,在发送过程中,如果有正常的退出,或者由于错误退出,
* 但是已经有复制数据了,都会进入发送环节。 */
if (copied) {
/* 如果已经有数据复制到发送队列了,就尝试立即发送。 */
tcp_tx_timestamp(sk, sockc.tsflags);
/* 是否能立即发送数据要看是否启用了 Nagle 算法。 */
tcp_push(sk, flags, mss_now, tp->nonagle, size_goal);
}
return copied;
...
}
- tcp 头部。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
/* include/uapi/linux/tcp.h */
struct tcphdr {
__be16 source;
__be16 dest;
__be32 seq;
__be32 ack_seq;
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4,
doff:4,
fin:1,
syn:1,
rst:1,
psh:1,
ack:1,
urg:1,
ece:1,
cwr:1;
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4,
res1:4,
cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif
__be16 window;
__sum16 check;
__be16 urg_ptr;
};
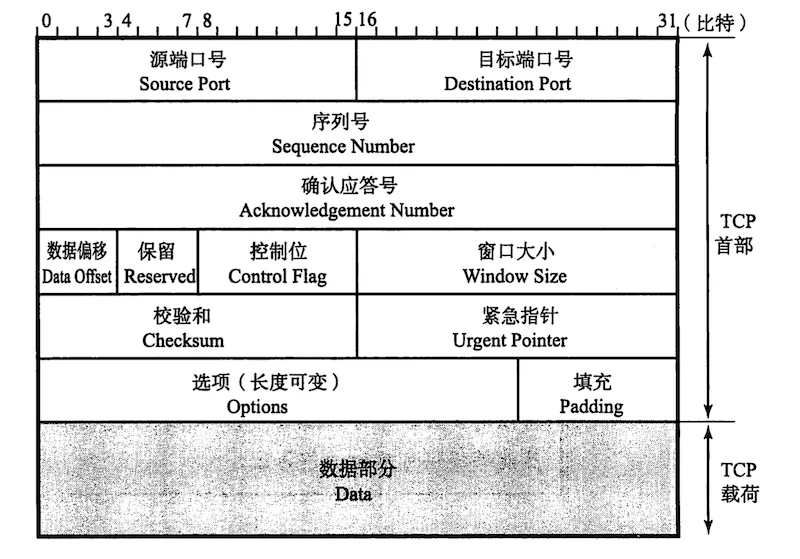
图片来源:《图解 TCP_IP》 – 6.7 TCP 首部格式
图片来源:《网络是怎样连接的》
tcp_transmit_skb填充 tcp 头部,将缓存数据进行发送。从上面发送逻辑,如果数据填充到缓冲区后,需要调用接口将数据发送出去,tcp_push,tcp_push_one,__tcp_push_pending_frames这几个接口内部都要调用tcp_write_xmit,tcp_write_xmit需要将数据通过tcp_transmit_skb填充 TCP 头部,从传输层发送到 IP 层处理。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp) {
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
...
while ((skb = tcp_send_head(sk))) {
...
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
...
}
...
}
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it,
gfp_t gfp_mask) {
return __tcp_transmit_skb(sk, skb, clone_it, gfp_mask,
tcp_sk(sk)->rcv_nxt);
}
/* This routine actually transmits TCP packets queued in by
* tcp_do_sendmsg(). This is used by both the initial
* transmission and possible later retransmissions.
* All SKB's seen here are completely headerless. It is our
* job to build the TCP header, and pass the packet down to
* IP so it can do the same plus pass the packet off to the
* device.
*
* We are working here with either a clone of the original
* SKB, or a fresh unique copy made by the retransmit engine.
*/
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt) {
const struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet;
struct tcp_sock *tp;
struct tcp_skb_cb *tcb;
struct tcp_out_options opts;
unsigned int tcp_options_size, tcp_header_size;
struct sk_buff *oskb = NULL;
struct tcp_md5sig_key *md5;
struct tcphdr *th;
u64 prior_wstamp;
int err;
...
tp = tcp_sk(sk);
...
inet = inet_sk(sk);
tcb = TCP_SKB_CB(skb);
memset(&opts, 0, sizeof(opts));
if (unlikely(tcb->tcp_flags & TCPHDR_SYN))
tcp_options_size = tcp_syn_options(sk, skb, &opts, &md5);
else
tcp_options_size = tcp_established_options(sk, skb, &opts, &md5);
tcp_header_size = tcp_options_size + sizeof(struct tcphdr);
...
skb_push(skb, tcp_header_size);
skb_reset_transport_header(skb);
skb_orphan(skb);
skb->sk = sk;
skb->destructor = skb_is_tcp_pure_ack(skb) ? __sock_wfree : tcp_wfree;
skb_set_hash_from_sk(skb, sk);
refcount_add(skb->truesize, &sk->sk_wmem_alloc);
skb_set_dst_pending_confirm(skb, sk->sk_dst_pending_confirm);
/* Build TCP header and checksum it. */
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(rcv_nxt);
*(((__be16 *)th) + 6) = htons(((tcp_header_size >> 2) << 12) | tcb->tcp_flags);
th->check = 0;
th->urg_ptr = 0;
/* The urg_mode check is necessary during a below snd_una win probe */
if (unlikely(tcp_urg_mode(tp) && before(tcb->seq, tp->snd_up))) {
if (before(tp->snd_up, tcb->seq + 0x10000)) {
th->urg_ptr = htons(tp->snd_up - tcb->seq);
th->urg = 1;
} else if (after(tcb->seq + 0xFFFF, tp->snd_nxt)) {
th->urg_ptr = htons(0xFFFF);
th->urg = 1;
}
}
tcp_options_write((__be32 *)(th + 1), tp, &opts);
skb_shinfo(skb)->gso_type = sk->sk_gso_type;
if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) {
th->window = htons(tcp_select_window(sk));
tcp_ecn_send(sk, skb, th, tcp_header_size);
} else {
/* RFC1323: The window in SYN & SYN/ACK segments
* is never scaled.
*/
th->window = htons(min(tp->rcv_wnd, 65535U));
}
...
/* ip_queue_xmit */
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
...
return err;
}
2.4. IP 网络层
- IPv4 IP 头部。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/* include/uapi/linux/ip.h */
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
/*The options start here. */
};
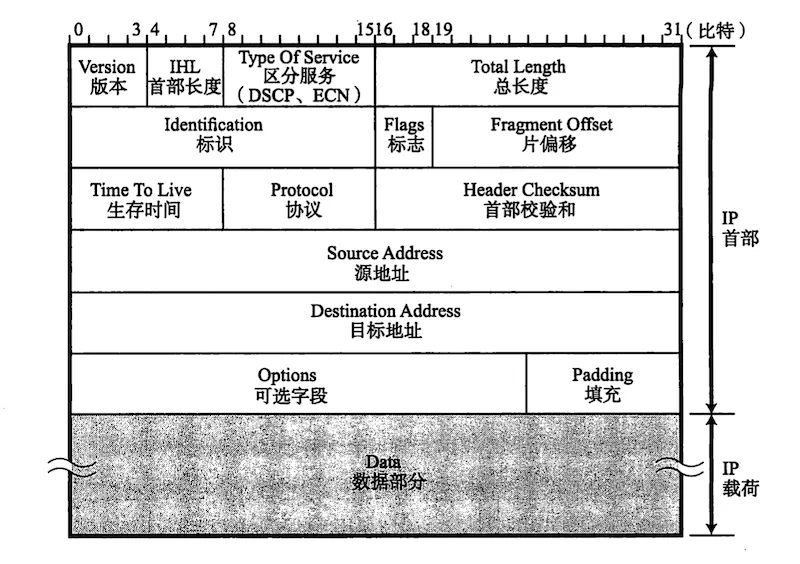
《图解 TCP_IP》 – 4.7 IPv4 首部
图片来源:《网络是怎样连接的》
- IP 层数据发送逻辑。选取路由,填充 IP 头,调用
ip_local_out发送 IP 包。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
/* net/ipv4/ip_output.c */
static inline int ip_queue_xmit(struct sock *sk, struct sk_buff *skb,
struct flowi *fl) {
return __ip_queue_xmit(sk, skb, fl, inet_sk(sk)->tos);
}
/* Note: skb->sk can be different from sk, in case of tunnels */
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos) {
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
...
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
rt = skb_rtable(skb);
if (rt)
goto packet_routed;
/* 选取路由。
* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (!rt) {
__be32 daddr;
/* Use correct destination address if we have options. */
daddr = inet->inet_daddr;
if (inet_opt && inet_opt->opt.srr)
daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will
* keep trying until route appears or the connection times
* itself out.
*/
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS_TOS(sk, tos),
sk->sk_bound_dev_if);
if (IS_ERR(rt))
goto no_route;
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
packet_routed:
...
/* 创建 IP 头,往里面填充数据。
* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
/* Transport layer set skb->h.foo itself. */
if (inet_opt && inet_opt->opt.optlen) {
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
ip_select_ident_segs(net, skb, sk,
skb_shinfo(skb)->gso_segs ?: 1);
...
/* 发送 IP 包。 */
res = ip_local_out(net, sk, skb);
...
}
int ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb) {
int err;
err = __ip_local_out(net, sk, skb);
if (likely(err == 1))
err = dst_output(net, sk, skb);
return err;
}
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb) {
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
...
skb->protocol = htons(ETH_P_IP);
/* 截获数据包,对数据包进行干预,例如 ip_tables。 */
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
/* Output packet to network from transport. */
static inline int dst_output(struct net *net, struct sock *sk, struct sk_buff *skb) {
return skb_dst(skb)->output(net, sk, skb);
}
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb) {
struct net_device *dev = skb_dst(skb)->dev;
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUT, skb->len);
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
2.5. MAC 层
IP 层调用 ip_finish_output 进入 MAC 层,对 skb 添加二层头(填充 MAC 信息)。
而数据发往下一跳的 MAC 地址,需要发送 arp 报文获取,这些操作会在 邻居子系统 里实现。然后,数据再从 MAC 层通过 dev_queue_xmit 发往设备层。
参考:《Linux 内核源码剖析 - TCP/IP 实现》- 上册 - 第十七章 邻居子系统
因为在以太网上传输 IP 数据报时,以太网设备并不能识别(IPv4) 32 位 IP 地址,而是以 48 位以太网地址传输以太网数据包的。以太网帧本体的前端是以太网的首部,它总共占 14 个字节。分别是 6 个字节的目标 MAC 地址,6 个字节的源 MAC 地址以及 2 个字节的上层协议类型。紧随帧头后面的是数据。一个数据帧所能容纳的最大数据范围是 46 ~ 1500 个字节。帧尾是一个叫做 FCS(Frame Check Sequence,帧检验序列)的 4 个字节。

内容和图片来源 《图解 TCP_IP》 - 3.3.3 以太网的历史。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
static int ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb) {
...
return ip_finish_output2(net, sk, skb);
}
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb) {
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev;
unsigned int hh_len = LL_RESERVED_SPACE(dev);
struct neighbour *neigh;
u32 nexthop;
...
/* 获取下一跳。从 struct rtable 路由表里面找到下一跳 */
nexthop = (__force u32) rt_nexthop(rt, ip_hdr(skb)->daddr);
/* 获取邻居子系统(下一跳肯定在和本机在同一个局域网中。)*/
neigh = __ipv4_neigh_lookup_noref(dev, nexthop);
if (unlikely(!neigh))
neigh = __neigh_create(&arp_tbl, &nexthop, dev, false);
if (!IS_ERR(neigh)) {
...
/* 通过邻居子系统输出,将下一跳的 MAC 头填充到 skb 缓存中,并将数据发送到设备层。
* 如果下一跳的 MAC 地址还没有,需要通过发送 arp 包获取。*/
res = neigh_output(neigh, skb);
...
}
...
}
/* include/net/neighbour.h */
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb) {
/* struct hh_cache 结构用来缓存二层首部。 */
const struct hh_cache *hh = &n->hh;
if ((n->nud_state & NUD_CONNECTED) && hh->hh_len)
/* 如果目的路由缓存了链路层的首部,快速输出到下一层。 */
return neigh_hh_output(hh, skb);
else
/* neigh_resolve_output。
* 还没有二层信息缓存,需要发送 arp 获取,然后再发到下一层。*/
return n->output(n, skb);
}
/* net/core/neighbour.c */
int neigh_resolve_output(struct neighbour *neigh, struct sk_buff *skb) {
int rc = 0;
/* neigh_event_send 确保输出的邻居状态有效,才能发送数据包。 */
if (!neigh_event_send(neigh, skb)) {
int err;
struct net_device *dev = neigh->dev;
unsigned int seq;
/* 缓存二层头。 */
if (dev->header_ops->cache && !neigh->hh.hh_len)
neigh_hh_init(neigh);
do {
...
/* 填充 MAC 包头 */
err = dev_hard_header(skb, dev, ntohs(skb->protocol),
neigh->ha, NULL, skb->len);
} while (read_seqretry(&neigh->ha_lock, seq));
if (err >= 0)
rc = dev_queue_xmit(skb);
...
}
...
}
static inline int neigh_hh_output(const struct hh_cache *hh, struct sk_buff *skb) {
unsigned int hh_alen = 0;
unsigned int seq;
unsigned int hh_len;
/* 填充二层头到 skb. */
do {
seq = read_seqbegin(&hh->hh_lock);
hh_len = hh->hh_len;
if (likely(hh_len <= HH_DATA_MOD)) {
hh_alen = HH_DATA_MOD;
/* skb_push() would proceed silently if we have room for
* the unaligned size but not for the aligned size:
* check headroom explicitly.
*/
if (likely(skb_headroom(skb) >= HH_DATA_MOD)) {
/* this is inlined by gcc */
memcpy(skb->data - HH_DATA_MOD, hh->hh_data,
HH_DATA_MOD);
}
} else {
hh_alen = HH_DATA_ALIGN(hh_len);
if (likely(skb_headroom(skb) >= hh_alen)) {
memcpy(skb->data - hh_alen, hh->hh_data,
hh_alen);
}
}
} while (read_seqretry(&hh->hh_lock, seq));
...
__skb_push(skb, hh_len);
return dev_queue_xmit(skb);
}
2.6. 设备层
数据从应用层发出,经过各种包装,来到设备层,通过 dev_queue_xmit 发送到硬件输出。
dev_queue_xmit 处理逻辑:若支持流量控制,则将等待输出的数据包根据规则加入到输出网络设备队列中排队,并在合适的时机激活网络输出软中断,依次将报文从队列中取出通过网络设备输出。若不支持流量控制,则直接将数据包从网络设备输出。
详细内容请参考:《Linux 内核源码剖析 - TCP/IP 实现》- 上册 - 第八章 - 接口层的输出。

图片来源:《Linux 内核源码剖析 - TCP/IP 实现》- 上册 - 第八章 - 接口层的输出。
3. 总结流程
- 应用程序通过系统调用 write 接口发送网络包,socket 层把数据拷贝到 socket 的发送缓冲区中;
- TCP/IP 协议栈层层包装处理发送缓冲区数据。
- 协议栈处理完成后产生软中断通知驱动程序,因为这时发送队列中有新的网络帧需要发送。
- 网卡驱动程序从发包队列中读出网络帧,并通过物理网卡把它发送出去。
4. 参考
- 《图解 TCP_IP》
- 《网络是怎样连接的》
- 《Linux 内核源代码情景分析》
- 《Linux 内核源码剖析 - TCP/IP 实现》
- vscode + gdb 远程调试 linux (EPOLL) 内核源码
- [内核源码] 网络协议栈 - socket (tcp)
- Linux网络系统原理笔记
- 25 张图,一万字,拆解 Linux 网络包发送过程
- 浅析TCP协议报文生成过程
- TCP发送源码学习(1)–tcp_sendmsg
- Linux操作系统学习笔记(二十二)网络通信之发包
- TCP数据发送之TSO/GSO
- linux tcp GSO和TSO实现
- Linux Kernel TCP/IP Stack|Linux网络硬核系列
- TCP的发送系列 — tcp_sendmsg()的实现(一)
- ARP协议与邻居子系统剖析
- Linux基础之网络包收发流程