
本文结合 Linux 5.0.1 内核源码,浅析 Linux 进程管理中的完全公平调度器(CFS)工作原理。
1. 概述
完全公平调度器(Completely Fair Scheduler, CFS)自 Linux 内核 2.6.23 版本引入,是默认的进程调度算法,目标是在所有可运行进程之间公平地分配 CPU 时间。
CFS 的核心是 虚拟运行时间(vruntime)——可以理解为”考虑了优先级的已用 CPU 时间”。优先级高的进程,vruntime 增长得慢,因此能获得更多 CPU 时间。调度器始终选择 vruntime 最小的进程运行,从而让所有进程尽可能公平地共享 CPU。
vruntime 是调度决策的核心依据,但完整的调度行为还需考虑处理器亲和性、负载均衡、中断与唤醒事件等因素。
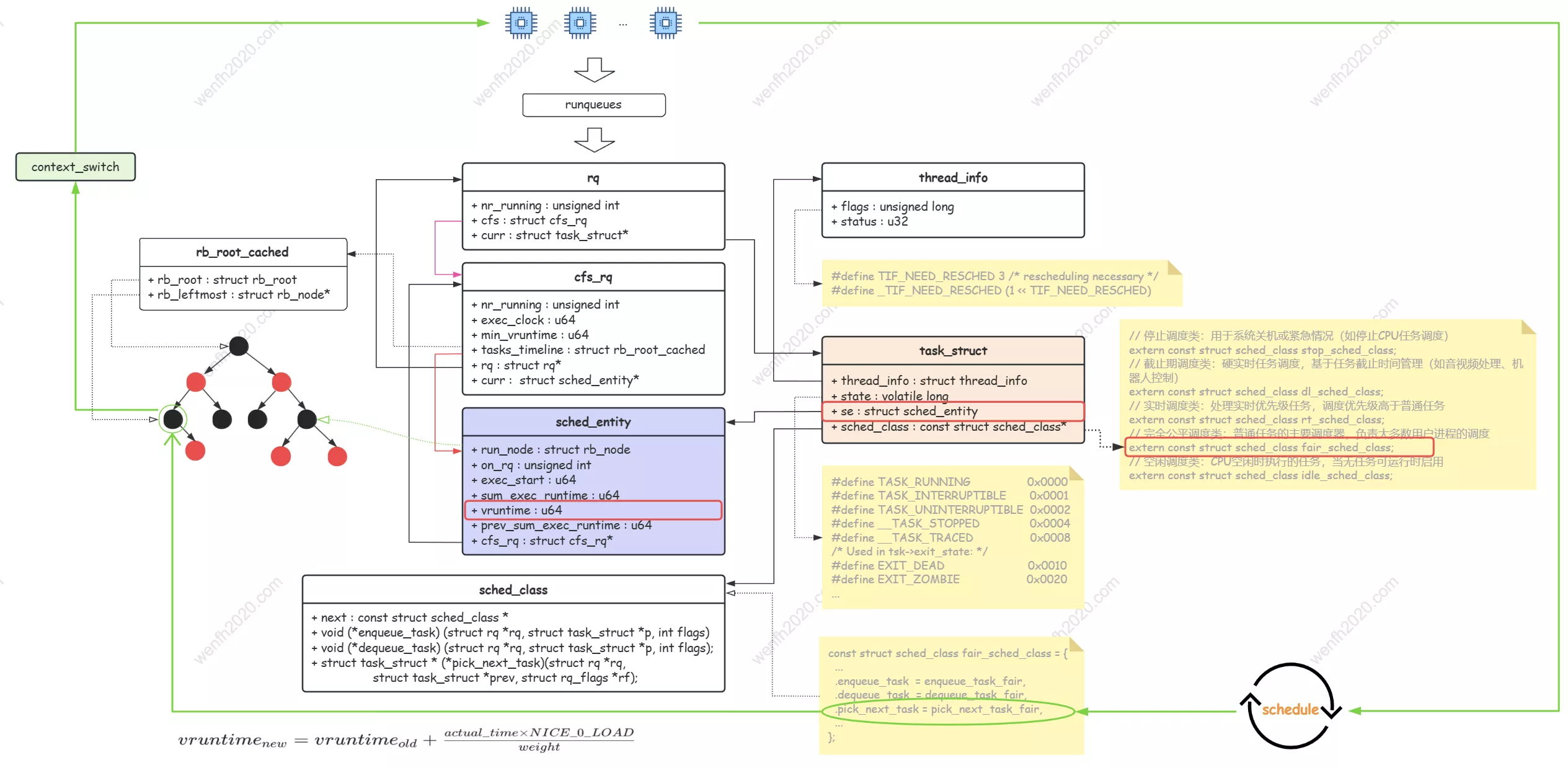
源码结构关系,请参考本章 核心结构 部分内容。
2. 虚拟运行时间调度
在 Linux 的完全公平调度器(CFS)设计中,每个 CPU 核心都拥有一个独立的调度域,其就绪队列使用一颗 红黑树 来组织。这棵树的排序关键字是每个进程的 “虚拟运行时间”(vruntime)。
核心机制与 vruntime 的作用:
- 排序依据:进程的 vruntime 值决定了它在红黑树中的位置,值越小,位置越靠左。
- 调度选择:调度器总是挑选 vruntime 最小的(即红黑树最左侧的)进程投入运行,这保证了最 “饥饿” 的进程能优先获得 CPU。
- 公平的实现:进程在 CPU 上运行后,其 vruntime 会随之增长,这使它逐渐向右移动,让位于其他 vruntime 更小的进程。高优先级进程(nice 值小 - 权重大)的 vruntime 增长更慢,因此能更频繁地被调度,从而获得更多的实际 CPU 时间。
2.1. vruntime
vruntime 它表示该进程在 CPU 上实际运行的时间经过加权后的结果。
调度器会优先选择 vruntime 值最小的进程运行,以确保每个进程的 vruntime 尽可能接近,从而实现公平的 CPU 时间分配。
1
新 vruntime = 旧 vruntime + 任务实际运行时间 × (nice 0 的权重 / 当前权重)
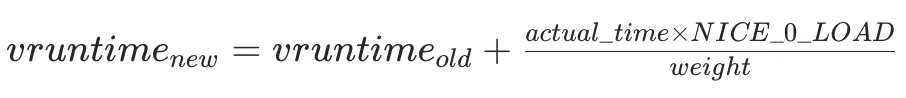
从时间计算公式可知:weight 权重越大 → vruntime 涨得越慢 → 更容易抢到 CPU。
相关结构体详见 核心结构 章节。
2.2. 红黑树管理 vruntime
在 CFS 调度器中,所有可运行任务都作为调度实体按虚拟运行时间(vruntime)组织在红黑树中。
该红黑树通过运行队列的 rq.cfs.tasks_timeline 字段进行管理。
系统在每次调度时,从红黑树中获取最左侧节点(即 vruntime 最小的调度实体)进行调度。
这意味着任务的 vruntime 值越小,其调度优先级越高,越有可能获得 CPU 时间。
下图中,vruntime 最小的节点(值为 10)位于红黑树最左侧,它将是下一个被调度的任务。

调度实体节点入队逻辑(进入任务就绪队列):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 比较两个调度实体的 vruntime 大小
static inline int entity_before(struct sched_entity *a, struct sched_entity *b) {
return (s64)(a->vruntime - b->vruntime) < 0;
}
// 将调度实体按 vruntime 插入红黑树
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se) {
struct rb_node **link = &cfs_rq->tasks_timeline.rb_root.rb_node;
struct rb_node *parent = NULL;
struct sched_entity *entry;
bool leftmost = true; // 标记是否将成为最左节点
// 从根节点遍历红黑树,寻找合适的插入位置
while (*link) {
parent = *link;
// 从 rb_node 获取包含它的 sched_entity
entry = rb_entry(parent, struct sched_entity, run_node);
if (entity_before(se, entry)) {
link = &parent->rb_left; // vruntime 更小,走左子树
} else {
link = &parent->rb_right; // vruntime 更大或相等,走右子树
leftmost = false;
}
}
// 将新节点链接到父节点下
rb_link_node(&se->run_node, parent, link);
// 调整红黑树平衡,并更新缓存的最左节点
rb_insert_color_cached(&se->run_node, &cfs_rq->tasks_timeline, leftmost);
}
2.3. vruntime 更新
update_curr 负责更新当前运行任务的 vruntime,在任何可能影响运行时间计算的时刻被调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static void update_curr(struct cfs_rq *cfs_rq) {
struct sched_entity *curr = cfs_rq->curr;
// 获取任务时钟(不含中断时间)
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
...
delta_exec = now - curr->exec_start;
...
curr->exec_start = now;
...
// 根据权重计算加权虚拟时间:权重越大 → vruntime 增长越慢
curr->vruntime += calc_delta_fair(delta_exec, curr);
...
}
calc_delta_fair 根据任务权重调整 vruntime 增量,内部调用 __calc_delta 完成计算。
1
2
3
4
5
6
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se) {
if (unlikely(se->load.weight != NICE_0_LOAD)) {
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
}
return delta;
}
2.4. 进程任务调度
调度函数(__schedule)从当前 CPU 的任务就绪队列 cfs_rq 中取出一个合适的任务进行调度。
__schedule -> cur cpu -> rq -> cfs_rq-> pick_next_task -> fair_sched_class -> pick_next_task_fair -> context_switch(rq, prev, next)
核心调度函数 __schedule:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 核心调度函数:选择下一个任务并执行上下文切换
static void __sched notrace __schedule(bool preempt) {
struct task_struct *prev, *next;
struct rq *rq;
int cpu;
cpu = smp_processor_id(); // 获取当前 CPU ID
rq = cpu_rq(cpu); // 获取当前 CPU 的运行队列
prev = rq->curr; // 当前正在运行的任务
...
// 从运行队列中选择下一个要运行的任务
next = pick_next_task(rq, prev, &rf);
...
if (likely(prev != next)) {
...
rq->curr = next;
...
// 保存 prev 上下文,加载 next 上下文
rq = context_switch(rq, prev, next, &rf);
}
...
}
创建任务时根据优先级绑定调度器:
1
2
3
4
5
6
7
8
9
10
11
12
int sched_fork(unsigned long clone_flags, struct task_struct *p) {
...
if (dl_prio(p->prio)) {
return -EAGAIN;
} else if (rt_prio(p->prio)) {
p->sched_class = &rt_sched_class;
} else {
// 普通优先级进程使用完全公平调度器调度
p->sched_class = &fair_sched_class;
}
...
}
选择下一个运行任务(优先走 CFS 快速路径,否则遍历所有调度类):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) {
const struct sched_class *class;
struct task_struct *p;
// 快速路径:所有任务都在 CFS 中,直接选择
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto again;
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
}
again:
// 按优先级从高到低遍历所有调度类
for_each_class(class) {
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
...
}
CFS 选择 vruntime 最小的调度实体作为下一个任务:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) {
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
...
struct sched_entity *curr = cfs_rq->curr;
...
// 从红黑树中选择 vruntime 最小的调度实体
se = pick_next_entity(cfs_rq, curr);
// 从调度实体获取对应的 task_struct
p = task_of(se);
...
// 将前一个任务放回运行队列
put_prev_entity(cfs_rq, &prev->se);
// 将选中的任务从队列取出,准备运行
set_next_entity(cfs_rq, se);
...
return p;
}
3. 核心结构
为了进一步理解 CFS 的调度源码,下面简单地梳理一下相关的数据结构关系。
3.1. 调度结构关系
| 结构 | 描述 |
|---|---|
| rq | 每 CPU 运行队列,管理该 CPU 上所有可运行任务,包含 cfs_rq、rt_rq 等子队列。 |
| cfs_rq | CFS 运行队列,用红黑树按 vruntime 排序调度实体,最左节点即下一个调度目标。 |
| task_struct | 进程/线程核心结构,包含 PID、优先级、状态、调度实体等信息。 |
| sched_entity | 调度实体,调度器的基本操作单元,存储 vruntime、权重等调度信息。 |
| sched_class | 调度类接口,定义 enqueue_task、pick_next_task 等操作,不同调度策略各自实现。 |
3.2. 结构描述
3.2.1. 运行队列 rq
1
2
3
4
5
6
7
8
9
// 每 CPU 一个运行队列,缓存行对齐
DECLARE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
struct rq {
unsigned int nr_running; // 可运行任务总数
struct cfs_rq cfs; // CFS 运行队列
struct task_struct *curr; // 当前运行任务
u64 clock_task; // 任务时钟(不含中断时间)
};
3.2.2. 完全公平调度运行队列 cfs_rq
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct load_weight {
unsigned long weight; // 权重越大,vruntime 增长越慢
...
};
struct cfs_rq {
struct load_weight load;
unsigned long runnable_weight; // 队列总权重,用于负载均衡
unsigned int nr_running; // 可运行任务数
unsigned int h_nr_running; // 层级任务计数(CGroup)
u64 exec_clock; // 累计执行时间
u64 min_vruntime; // 队列最小 vruntime
struct rb_root_cached tasks_timeline; // 红黑树
struct sched_entity *curr;
struct sched_entity *next;
struct rq *rq;
...
};
// 缓存最左节点,O(1) 获取最小 vruntime
struct rb_root_cached {
struct rb_root rb_root;
struct rb_node *rb_leftmost;
};
3.2.3. 进程结构 task_struct
1
2
3
4
5
6
7
8
9
10
struct task_struct {
struct thread_info thread_info;
volatile long state; // TASK_RUNNING, TASK_INTERRUPTIBLE 等
...
const struct sched_class* sched_class; // 调度类
struct sched_entity se; // 调度实体
int on_rq; // 是否在运行队列上
int prio; // 动态优先级
...
};
3.2.4. 调度实体 sched_entity
调度实体可以是一个进程或一个进程组,调度器依据其信息决定 CPU 时间分配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct load_weight {
unsigned long weight; // 负载权重
u32 inv_weight; // weight 的倒数,避免除法运算
};
struct sched_entity {
struct load_weight load;
unsigned long runnable_weight;
struct rb_node run_node; // 红黑树节点
struct list_head group_node;
unsigned int on_rq; // 是否在就绪队列上
u64 exec_start; // 时间片开始时间
u64 sum_exec_runtime; // 实际 CPU 占用时间
u64 vruntime; // 虚拟运行时间
...
};
3.2.5. 调度器 sched_class
1
2
3
4
5
6
7
8
9
10
struct sched_class {
const struct sched_class *next; // 调度类链表
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task)(
struct rq *rq, struct task_struct *prev, struct rq_flags *rf);
void (*put_prev_task)(struct rq *rq, struct task_struct *p);
...
};
内核调度类实例(优先级从高到低):
1
2
3
4
5
extern const struct sched_class stop_sched_class; // 停止调度(关机等)
extern const struct sched_class dl_sched_class; // 截止期调度(硬实时)
extern const struct sched_class rt_sched_class; // 实时调度
extern const struct sched_class fair_sched_class; // 完全公平调度(默认)
extern const struct sched_class idle_sched_class; // 空闲调度
4. 参考
- 《深入 Linux 内核架构》
- 《Linux 内核设计与实现》
- linux 调度子系统 8 - schedule 函数
- 处理器调度 (RR, MLFQ 和 CFS;优先级翻转;多处理器调度)