Redis 6.0 版本增加了多线程并发处理网络 IO 功能,主要是为了利用多核资源,减轻主线程负载,提高程序整体性能。
1. 架构
1.1. 整体框架
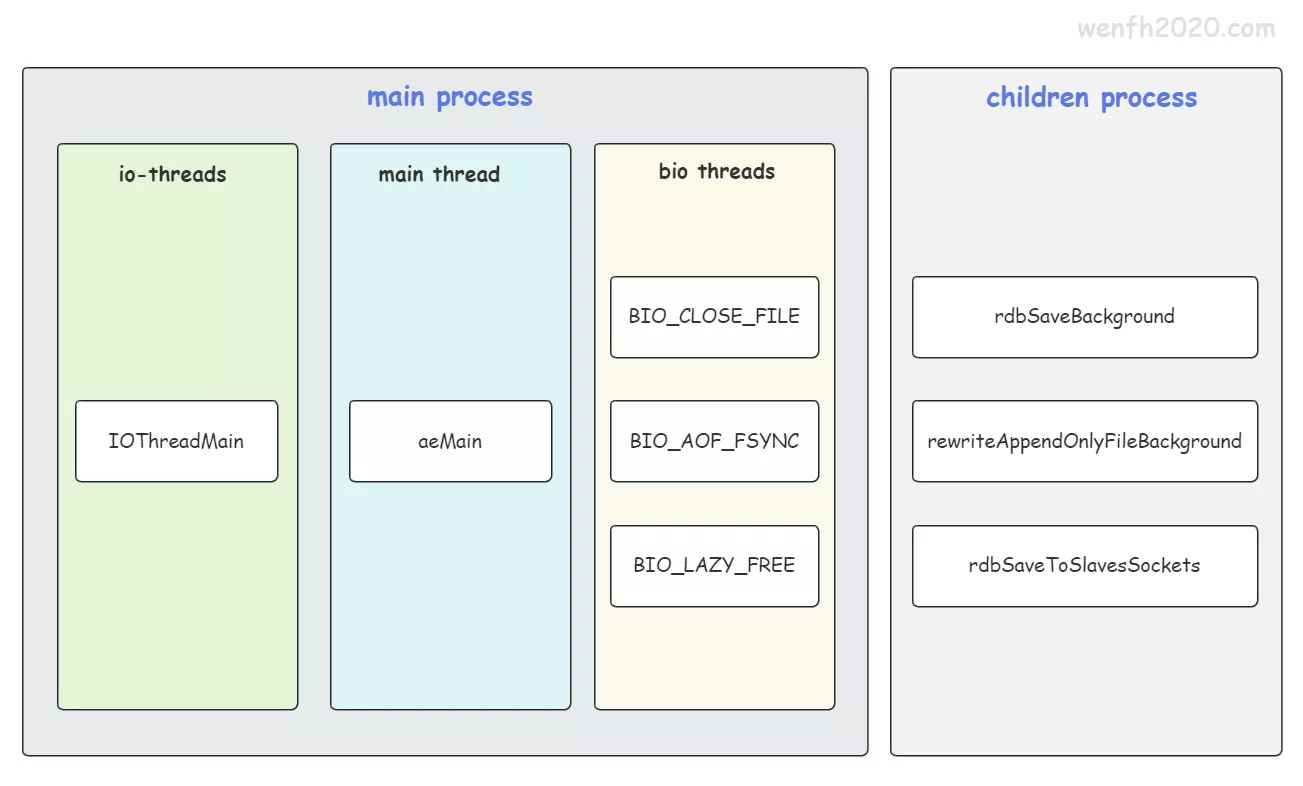
Redis 是 多进程 + 多线程 混合并发模型。
- 子进程持久化:重写 aof 文件 / 保存 rdb 文件。
- 多线程:主线程 + 后台线程 + 新增网络 IO 线程(Redis 6.0)。
详细参考:《[Redis] 浅析 Redis 并发模型》
1.2. 网络 IO 框架
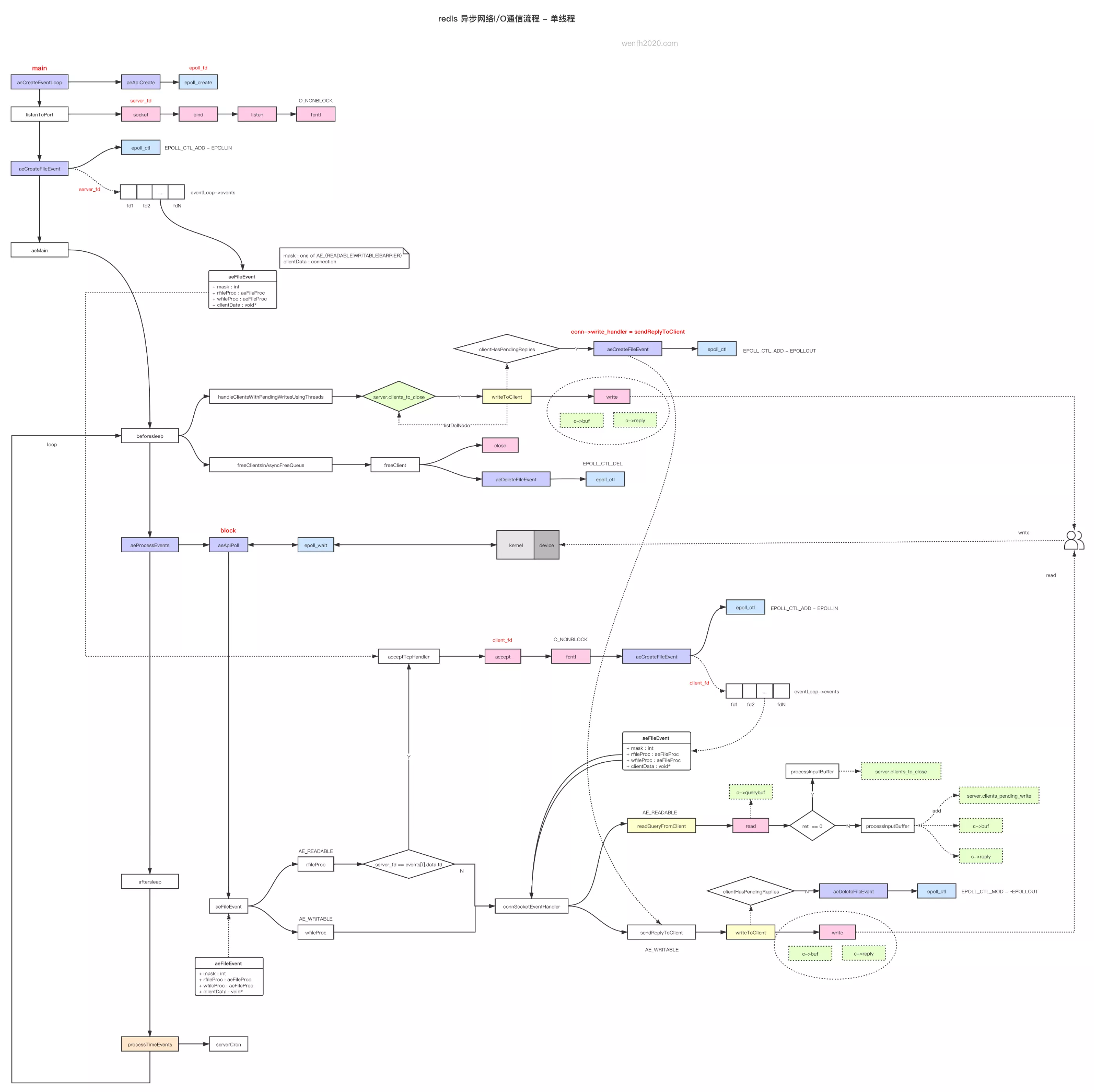
1.2.1. 主线程异步网络 IO
下图描述了 Redis 客户端与服务端主线程异步通信流程,有兴趣的朋友可以参考:《[redis 源码走读] 异步通信流程-单线程》,这里不详细展开了。
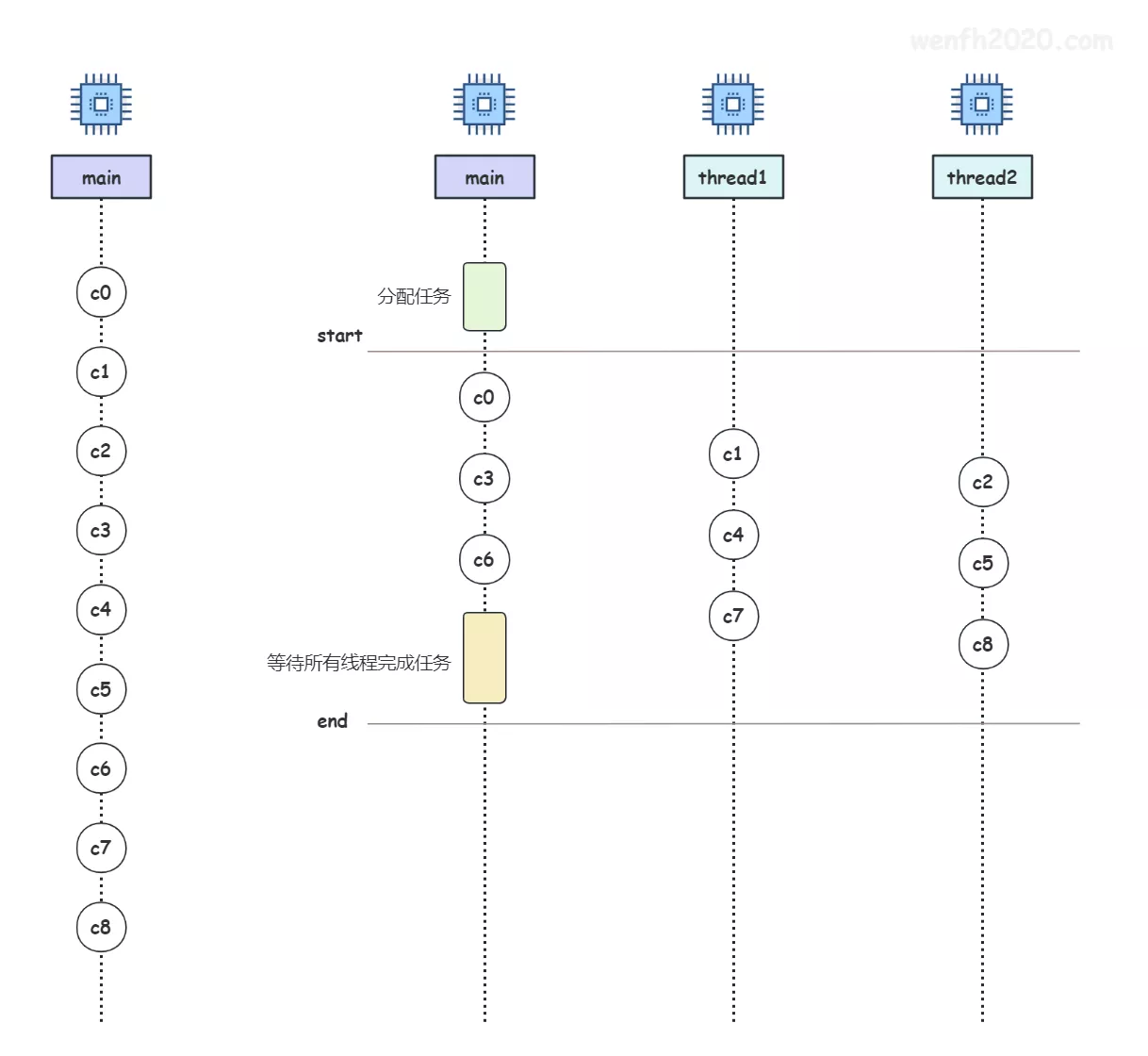
1.2.2. 多线程网络 IO 框架
Redis 6.0 以前,主线程处理网络 IO;Redis 6.0 增加了多线程处理网络 IO 功能,详见下图。
- 如果没开启多线程,那么 Redis 只会使用主线程处理网络 IO,主线程单线程处理网络 IO 是串行的。
- 为了保证主逻辑处理方式整体不变,多线程 IO 工作方式,不允许同时并发读写操作,同一时刻只允许读或只允许写。
- 如果开启了多线程,而且等待处理的 client 数量很少,新增的网络 IO 线程会被挂起,仍然使用主线程工作;否则启用多线程工作,将等待的 clients,平均分配给多个线程(主线程+新增线程)并行处理。
- 任务分配完以后,主线程将处理自己的任务,并等待新增线程都处理完任务后,才会执行下一个步骤的其它操作,这样做的目的是为了保证整体逻辑串行;不因为引入多线程处理方式改变了原来的主逻辑,尽力将多线程并行逻辑的影响减少到最小。
2. 配置
io-threads 线程配置,redis.conf 配置文件默认是不开放的,默认只有一个线程在工作,这个线程就是主线程。
io-threads 4,如果开放多线程配置,那么 IO 处理线程默认共有 4 个,包括主线程。也就是说,新增的 IO 线程有 3 个。io-threads-do-reads no,是否开启读操作多线程模式;因为 Redis 作为缓存服务,读入数据比较小,写出数据比较多,所以读操作非必要不需要开启多线程模式。
1
2
3
4
5
6
7
# redis.conf
# 配置多线程处理线程个数,默认 4。
# io-threads 4
#
# 多线程是否处理读事件,默认关闭。
# io-threads-do-reads no
3. 源码剖析
网络读写操作大同小异,下面根据源码剖析写操作。
3.1. 主线程
- 根据需要网络 IO 的 clients 数量决定是否需要启动多线程模式。
- 如果开启了多线程模式,将需要 IO 的 clients 分配给多个线程进行工作。
- 主线程对分配给自己的 clients 进行对应的读写任务。
- 等待其它子线程都完成任务后,再进行其它操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0;
// 如果 client 很少,关闭多线程模式,用主线程处理写操作。
if (stopThreadedIOIfNeeded()) {
// 主线程处理写操作。
return handleClientsWithPendingWrites();
}
if (!io_threads_active) startThreadedIO();
// 主线程分配任务,将 client 按取模的方式分配给各个线程。
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 标识写操作。
io_threads_op = IO_THREADS_OP_WRITE;
// 设置 io_threads_pending 数据,
// 后面根据这个数据确定子线程是否已完成任务。
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
// 主线程处理第一个队列。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 写数据,发送给回复给客户端。
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
// 等待所有子线程完成任务。
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 如果有的 client 数据还没发送完(异步),那么注册写事件,下次再触发发送。
if (clientHasPendingReplies(c)
&& connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR) {
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
return processed;
}
3.2. 子线程
- 主线程已分配给子线程 clients。
- 子线程遍历 clients 执行对应的读写操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void *IOThreadMain(void *myid) {
long id = (unsigned long)myid;
while(1) {
...
// 根据操作类型,处理对应的读/写逻辑。
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
}
...
}
// 已完成任务,清空数据。
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
}
}
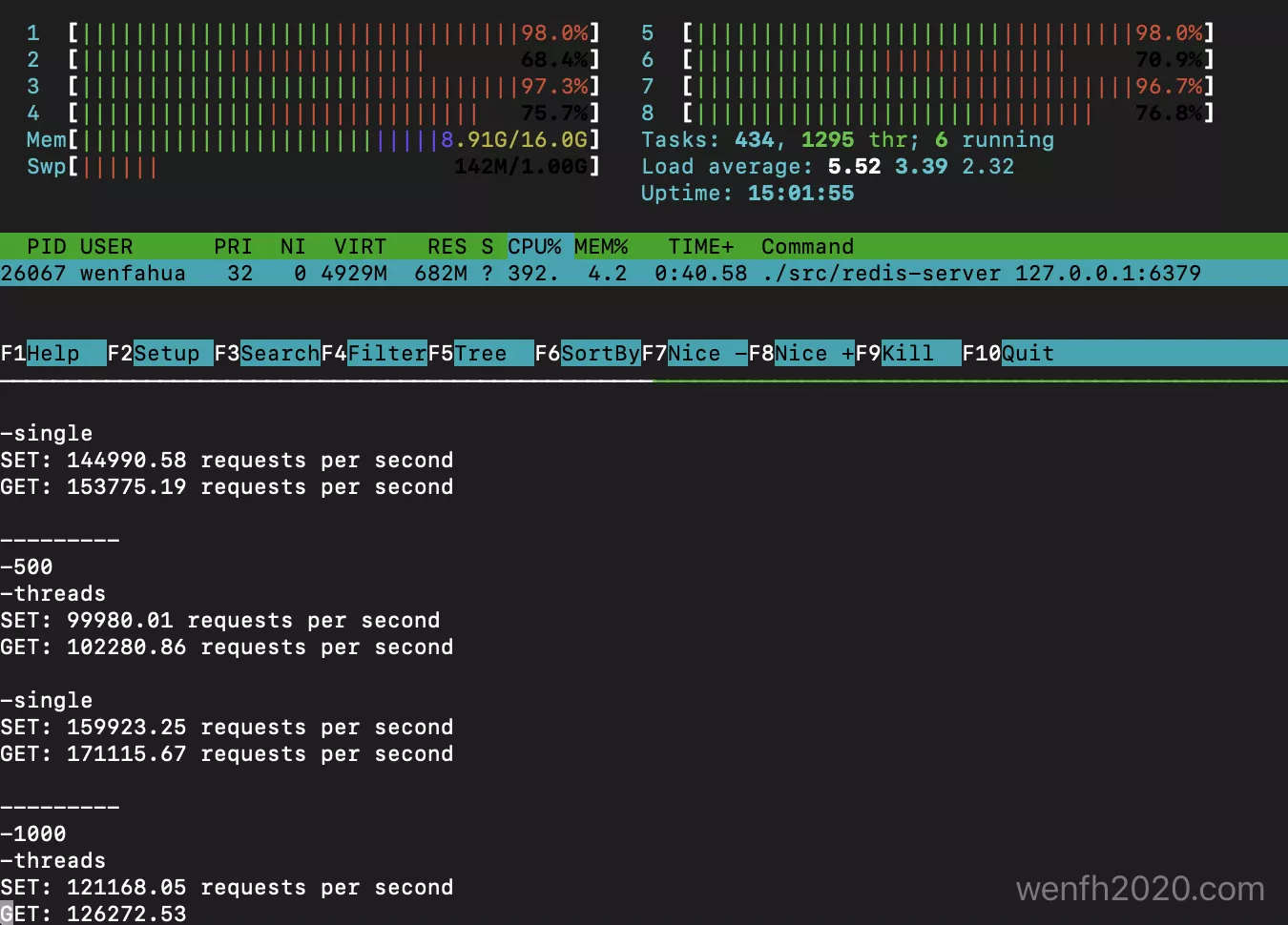
4. 测试
-
压测设备:8 核心,16G 内存。
-
配置。多线程模式测试,开启读写两个选项;单线程模式测试则会关闭。
1
2
3
# redis.conf
io-threads 4
io-threads-do-reads yes
- 压测命令。
命令逻辑已整理成脚本,放到 github,顺手录制了测试视频:压力测试 redis 多线程处理网络 I/O。
1
2
3
4
5
# 压测工具会模拟多个终端,防止超出限制,被停止。
ulimit -n 16384
# 可以设置对应的链接数/包体大小进行测试。
./redis-benchmark -c xxxx -r 1000000 -n 100000 -t set,get -q --threads 2 -d yyyy
- 压测结果:多线程没有单线程好 ^_^!。可能测试数据 key-value 中的 value 体量太小了未能看见应有的结果,所以我们要根据自身业务场景开启多线程网络 IO 功能。