
redis 是 key-value 的 NoSQL 数据库,dict 是基础数据结构,dict 总体来说是一个哈希表,哈希表 O(1) 的时间复杂度,能高效进行数据读取。
dict 还有动态扩容/缩容功能,能灵活高效地使用机器内存。
因为 redis 是单进程服务,所以当数据量很大时,扩容/缩容这些内存操作,涉及到新内存重新分配,数据拷贝,必然会影响服务质量。redis 作者采用了渐进方式,将一次性操作,分散到 dict 对应的各个增删改查操作里,每个操作触发有限的数据迁移。所以 dict 会有两个哈希表(dictht ht[2];),相应的 rehashidx 迁移位置,方便数据迁移。
1. 数据结构
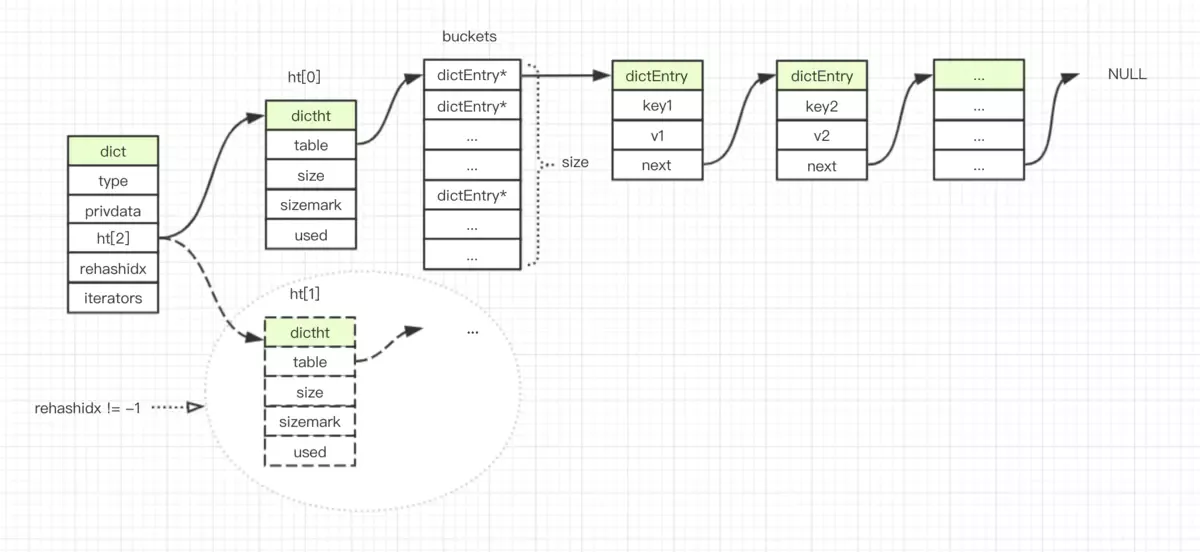
设计图来源:《redis dict 字典数据结构》
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
//字典
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;/* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
// 哈希表
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
// 链表数据结点
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
// 数据类型,不同应用实现是不同的,所以用指针函数抽象出通用的接口,方便调用。
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
2. 时间复杂度(读数据)
查找数据,哈希表 O(1) 时间复杂度,但是哈希表也会存在碰撞问题,所以哈希索引指向的列表长度也会影响效率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#define dictHashKey(d, key) (d)->type->hashFunction(key)
dictEntry *dictFind(dict *d, const void *key) {
dictEntry *he;
uint64_t h, idx, table;
if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
// 如果 key 已经存在则返回对应的数据结构。
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
// 如果数据正在迁移,从第二张表上查找。
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
3. 工作流程
- 堆栈调用流程,下面会通过这个堆栈函数调用时序,看以下写操作的源码流程:
调试方法,可以参考视频:
bilibili: Debug Redis in VsCode with Gdb
youtube: Debug Redis in VsCode with Gdb
1
2
3
4
5
6
7
8
9
10
11
12
#0 dictAdd (d=0x100529310, key=0x1018000b1, val=0x101800090) at dict.c:324
#1 0x000000010002bb9c in dbAdd (db=0x101005800, key=0x101800070, val=0x101800090) at db.c:159
#2 0x000000010002bd5c in setKey (db=0x101005800, key=0x101800070, val=0x101800090) at db.c:186
#3 0x000000010003abad in setGenericCommand (c=0x101015400, flags=0, key=0x101800070, val=0x101800090, expire=0x0, unit=0, ok_reply=0x0, abort_reply=0x0) at t_string.c:86
#4 0x000000010003afdd in setCommand (c=0x101015400) at t_string.c:139
#5 0x000000010001052d in call (c=0x101015400, flags=15) at server.c:2252
#6 0x00000001000112ac in processCommand (c=0x101015400) at server.c:2531
#7 0x0000000100025619 in processInputBuffer (c=0x101015400) at networking.c:1299
#8 0x0000000100021cb8 in readQueryFromClient (el=0x100528ba0, fd=5, privdata=0x101015400, mask=1) at networking.c:1363
#9 0x000000010000583c in aeProcessEvents (eventLoop=0x100528ba0, flags=3) at ae.c:412
#10 0x0000000100005ede in aeMain (eventLoop=0x100528ba0) at ae.c:455
#11 0x00000001000159d7 in main (argc=2, argv=0x7ffeefbff8c8) at server.c:4114
4. 写数据
4.1. 保存数据
数据库保存数据时,先检查这个键是否已经存在,从而分开添加,删除逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/* High level Set operation. This function can be used in order to set
* a key, whatever it was existing or not, to a new object.
*
* 1) The ref count of the value object is incremented.
* 2) clients WATCHing for the destination key notified.
* 3) The expire time of the key is reset (the key is made persistent). */
void setKey(redisDb *db, robj *key, robj *val) {
if (lookupKeyWrite(db,key) == NULL) {
dbAdd(db,key,val);
} else {
dbOverwrite(db,key,val);
}
incrRefCount(val);
removeExpire(db,key);
signalModifiedKey(db,key);
}
4.2. 添加数据
要添加一个元素,首先需要申请一个空间,申请空间涉及到是否需要扩容,key 是否已经存在了。
1
2
3
4
5
6
7
8
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val) {
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
4.3. 增加数据结点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
/* Low level add. This function adds the entry but instead of setting
* a value returns the dictEntry structure to the user, that will make
* sure to fill the value field as he wishes.
*
* This function is also directly exposed to the user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned.
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key) {
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
// 检查 key 是否存在,避免重复添加。
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
// 如果哈希表正在迁移数据,操作哈希表2.
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
4.4. 哈希索引
检查哈希键是否已经被占用,被占用了就返回 -1,否则返回 key 对应的哈希索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
/* Returns the index of a free slot that can be populated with
* a hash entry for the given 'key'.
* If the key already exists, -1 is returned.
*
* Note that if we are in the process of rehashing the hash table, the
* index is always returned in the context of the second (new) hash table. */
static int _dictKeyIndex(dict *d, const void *key) {
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* Compute the key hash value */
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
// 如果 key 已经存在则返回 -1。
if (key==he->key || dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
// 如果哈希表处在数据迁移状态,从第二张表上查找。
if (!dictIsRehashing(d)) break;
}
return idx;
}
5. 数据迁移
5.1. 哈希表数据迁移
避免数据量大,一次性迁移需要耗费大量资源,每次只迁移部分数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
/* This function performs just a step of rehashing, and only if there are
* no safe iterators bound to our hash table. When we have iterators in the
* middle of a rehashing we can't mess with the two hash tables otherwise
* some element can be missed or duplicated.
*
* This function is called by common lookup or update operations in the
* dictionary so that the hash table automatically migrates from H1 to H2
* while it is actively used. */
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
// empty_visits 记录哈希表最大遍历空桶个数。
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
// 从 ht[0] rehashidx 位置开始遍历 n 个桶进行数据迁移。
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
// 当遍历限制的空桶数量后,返回。
if (--empty_visits == 0) return 1;
}
// 获取桶上的数据链表
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 旧的数据链表插入新的数据链表前面。
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
// 数据迁移完毕,重置哈希表两个 table。
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
5.2. 定时执行任务
1
2
3
4
5
6
7
8
9
10
11
/* Rehash for an amount of time between ms milliseconds and ms+1 milliseconds */
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
6. 扩容缩容
dict 是 redis 基础数据之一,该数据结构有动态扩容和缩容功能。
6.1. 是否需要扩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d) {
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
// 当使用的数据大于哈希表大小就可以扩展了。当`dict_can_resize` 不允许扩展时,数据的使用与哈希表的大小对比,超出一个比率强制扩展内存。
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) {
// 使用数据大小的两倍增长
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
6.2. 扩容容量大小
1
2
3
4
5
6
7
8
9
10
11
12
/* Our hash table capability is a power of two */
static unsigned long _dictNextPower(unsigned long size) {
unsigned long i = DICT_HT_INITIAL_SIZE;
// 新容量大小是 2 的 n 次方,并且这个数值是第一个大于 2 * 原长度 的值。
if (size >= LONG_MAX) return LONG_MAX;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
6.3. 扩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size) {
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
// 如果哈希表还是空的,给表1分配空间,否则空间分配给表2
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
6.4. 缩容
- 缩容,部分删除操作,会触发重新分配内存进行存储。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#define HASHTABLE_MIN_FILL 10 /* Minimal hash table fill 10% */
int zsetDel(robj *zobj, sds ele) {
...
if (htNeedsResize(zs->dict)) dictResize(zs->dict);
...
}
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
/* Resize the table to the minimal size that contains all the elements,
* but with the invariant of a USED/BUCKETS ratio near to <= 1 */
int dictResize(dict *d) {
int minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal);
}
7. 随机键
随机键是配合一些算法使用的,例如 maxmemory 的淘汰策略,需要对数据进行采样,如果要随机取多个数据,dictGetSomeKeys 速度要比 dictGetRandomKey 快,但是随机分布效果没有dictGetRandomKey 好。
7.1. 随机取多个
字典随机连续采样。不保证能采样满足 count 个数。采集到指定数量样本,或者样本不够,但是查找次数到达上限,会退出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count) {
unsigned long j; /* internal hash table id, 0 or 1. */
unsigned long tables; /* 1 or 2 tables? */
unsigned long stored = 0, maxsizemask;
unsigned long maxsteps;
if (dictSize(d) < count) count = dictSize(d);
maxsteps = count*10;
// 如果字典正在数据迁移,多迁移几个数据,然后再进行逻辑。
for (j = 0; j < count; j++) {
if (dictIsRehashing(d))
_dictRehashStep(d);
else
break;
}
tables = dictIsRehashing(d) ? 2 : 1;
maxsizemask = d->ht[0].sizemask;
if (tables > 1 && maxsizemask < d->ht[1].sizemask)
maxsizemask = d->ht[1].sizemask;
unsigned long i = random() & maxsizemask;
unsigned long emptylen = 0;
// 两个条件,采集到指定数量样本,或者样本不够,但是查找次数到达上限。
while(stored < count && maxsteps--) {
for (j = 0; j < tables; j++) {
if (tables == 2 && j == 0 && i < (unsigned long) d->rehashidx) {
/* 哈希表正在数据迁移,我们在表 1 上采样,如果 i < d->rehashidx,
* 说明 i 下标指向的数据已经迁移到表 2 中去了,那么我们到表 2 中进行采样。
* 如果 i 下标大于表 2 的大小,那么在表2 中索引将会越界,那么继续在表 1 中
* 没有迁移的数据段( > rehashidx)中查找。*/
if (i >= d->ht[1].size)
i = d->rehashidx;
else
continue;
}
// 如果下标已经超出了当前表大小,继续遍历下一张表。
if (i >= d->ht[j].size) continue;
dictEntry *he = d->ht[j].table[i];
// 如果连续几个桶都是空的,再随机位置进行采样。
if (he == NULL) {
emptylen++;
if (emptylen >= 5 && emptylen > count) {
i = random() & maxsizemask;
emptylen = 0;
}
} else {
emptylen = 0;
while (he) {
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) return stored;
}
}
}
i = (i+1) & maxsizemask;
}
return stored;
}
7.2. 随机取一个
先找一个随机非空桶,再在桶里随机找一个元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
/* Return a random entry from the hash table. Useful to
* implement randomized algorithms */
dictEntry *dictGetRandomKey(dict *d) {
dictEntry *he, *orighe;
unsigned long h;
int listlen, listele;
if (dictSize(d) == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
if (dictIsRehashing(d)) {
do {
// 哈希表正在进行数据迁移,
// 从 表 1 的 rehashidx 到 d->ht[0].size 和 表 2 上随机抽取数据。
// 但是当哈希表正在扩容时,表2的大小至少是表 1 的两倍,而随机值落在表 2 的几率会更
//大。这个时候表2 的数据还没怎么进行填充,所以数据采集就会失败。失败几率会比较高。
h = d->rehashidx + (random() % (d->ht[0].size +
d->ht[1].size -
d->rehashidx));
he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] :
d->ht[0].table[h];
} while(he == NULL);
} else {
do {
h = random() & d->ht[0].sizemask;
he = d->ht[0].table[h];
} while(he == NULL);
}
listlen = 0;
orighe = he;
while(he) {
he = he->next;
listlen++;
}
listele = random() % listlen;
he = orighe;
while(listele--) he = he->next;
return he;
}