-
初体验 Claude code
Claude code 神器啊!基于 “先问后做” 原则,用它做项目,快一个月几乎没有手动写过代码。从业二十载,曾无数次想象过行业的发展,就是未曾想到过,编程工具如今发展到如此智能的地步。
尽管 AI 发展迅速,它也会像人一样犯错:修复一个 bug,却引入几个新 bug,但是只要你的需求文档思路清晰,实现步骤有条理,阐述逻辑严谨,cc 就会实现得非常好。
这样看来它还没强大到:单凭输入的几个关键字就能准确地同步人类大脑的想法。换句话说,你得把大脑里的想法,尽可能地告诉它,它才能很好地工作。
Claude code(后面简称 cc)

-
[network] 记一次网站网络流量优化
近期将博客迁移至阿里云 Docker 环境后,网站出现流量异常问题。
经排查,瓶颈主要集中于图片资源与服务端缓存配置。通过一系列针对性优化,页面首次加载流量由 7 MB 显著优化至 500KB 左右,性能得到大幅提升。
![[network] 记一次网站网络流量优化](data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 9'%3E%3C/svg%3E)
-
[内核源码] 浅析 CFS 完全公平调度器工作原理
本文结合 Linux 5.0.1 内核源码,浅析 Linux 进程管理中的完全公平调度器(CFS)工作原理。
-
[C++] 提高 C++ 项目编译速度的神兵利器
最近接手的一个 Linux C++ 项目,编译速度把我折腾得怀疑人生。
—— 编译经过优化,源代码一行未改,全编译时间硬是从 半个小时 缩短到
3 分钟!!!(OMG,此处省略一万字…)划重点,三板斧:
-
[C++] Google Authenticator 算法实现
谷歌验证码采用基于共享密钥的动态验证机制。服务端与客户端使用相同的密钥,并据此分别生成匹配的动态验证码以完成校验。尽管共享密钥本身并非绝对安全,但由于它仅在初次设置时低频次传输,且作为二次验证使用,因此仍能为核心账户安全提供一道坚实有效的屏障。
-
[算法] 一致性哈希算法
一致性哈希是后端系统中解决数据路由与负载均衡问题的关键技术。理解其工作原理,对于设计高扩展、高可用的分布式系统至关重要。本文将介绍其算法思想与经典应用场景。
-
[C++] 浅析 std::share_ptr 内部结构
最近阅读了 C++ 智能指针的部分实现源码,简单总结和记录一下 std::share_ptr/std::weak_ptr 内部结构和工作原理。
-
[Redis] 浅析 Redis 并发模型
很多朋友以为 Redis 是单线程程序,事实上它是
多进程 + 多线程混合并发模型,这样能利用多核优势,提高性能。- 子进程持久化:重写 aof 文件 / 保存 rdb 文件。
- 多线程:主线程 + 后台线程 + 新增网络 IO 线程(Redis 6.0)。
-
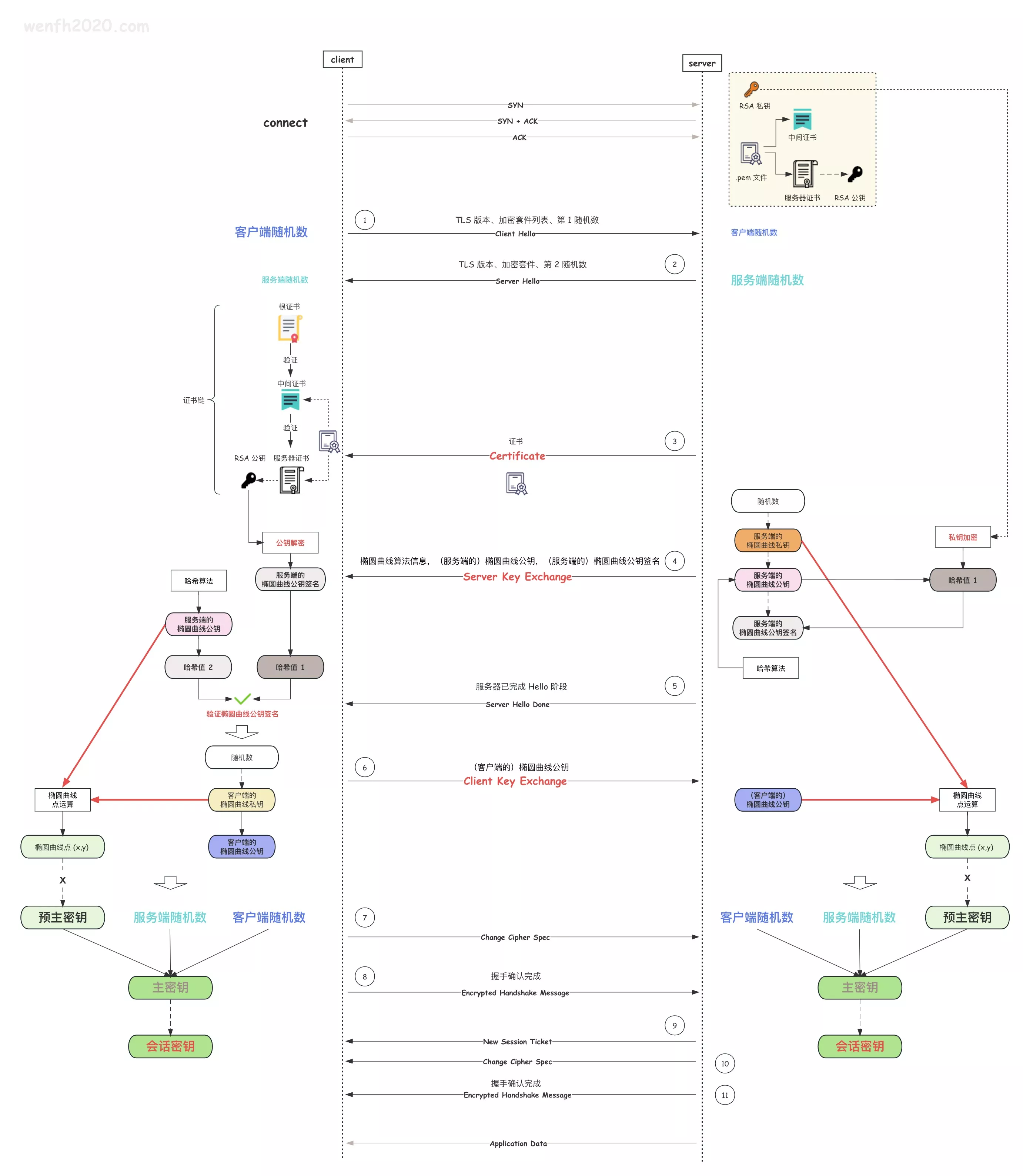
浅析 HTTPS TLS(ECDHE)协议的握手流程(图解)
通过 wireshark 抓取 HTTPS 包,理解 TLS 1.2 安全通信协议的握手流程。
重点理解几个点:
- TLS 握手流程:通过 wireshark 抓取 HTTPS 包理解。
- 协商加密:双方通过 ECDHE 椭圆曲线的密钥交换算法,协商出共享的
会话密钥进行内容对称加密通信,避免传输会话密钥被中间人窃取。 - CA 证书:证书用来验证服务端的合法性。证书类似于身份证,可以证明某人是某人,当然身份证可以伪造,一般人可能识别不出来,但是国家相关部门可以验证你的身份合法性。同理,服务端可以通过 CA 证书识别自身身份,客户端接收服务端发送的证书,并通过
证书链验证该证书,以此确认服务端身份。
-
[QT] 浅析信号与槽
QT 的信号与槽技术,是一种用于对象间通信的机制。它允许一个对象发出一个信号,而其他对象可以通过连接到该信号的槽来接收并处理该信号。
本文将通过调试走读 QT (5.14.2) 信号与槽开源源码,理解它的工作原理。
-
[C++] C++ 有什么好用的线程池?
C++ 有什么推荐的线程池库吗?…
-
[C++] 深入探索 C++ 多态 ① - 虚函数调用链路
最近翻阅侯捷先生的两本书:(翻译)《深度探索 C++ 对象模型》 和 《C++ 虚拟与多态》,获益良多。
要理解多态的工作原理,得理解这几个知识点的关系:
虚函数、虚函数表、虚函数指针、以及对象的内存布局。
-
[stl 源码分析] std::sort
std::sort 是标准库里比较经典的算法,它是一个复合排序,结合了几种算法的优点。
-
[内核源码] Linux 网络数据接收流程(TCP)- NAPI
走读 Linux(5.0.1)源码,理解 TCP 网络数据接收和读取工作流程(NAPI)。
要搞清楚数据的接收和读取流程,需要梳理这几个角色之间的关系:网卡(本文:e1000),主存,CPU,网卡驱动,内核,应用程序。
-
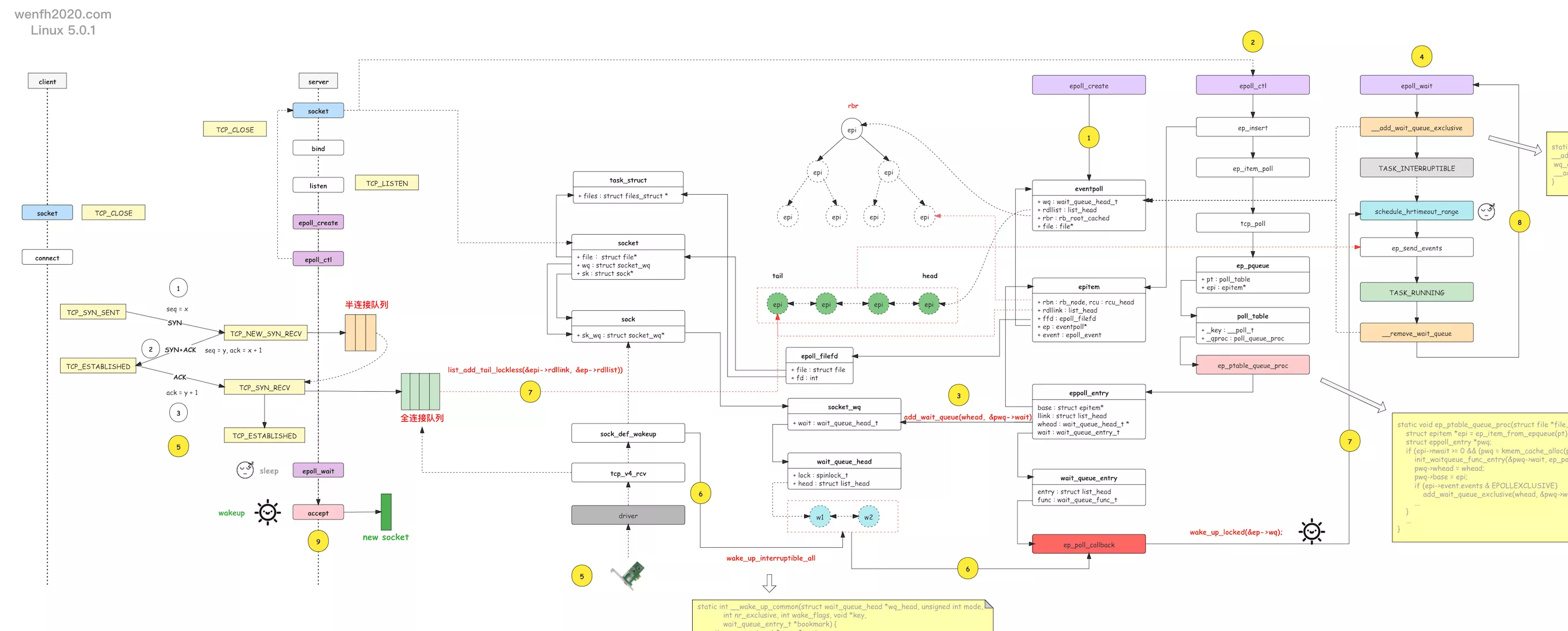
tcp + epoll 内核睡眠唤醒工作流程
本章整理了一下服务端 tcp 的第三次握手和 epoll 内核的等待唤醒工作流程。
-
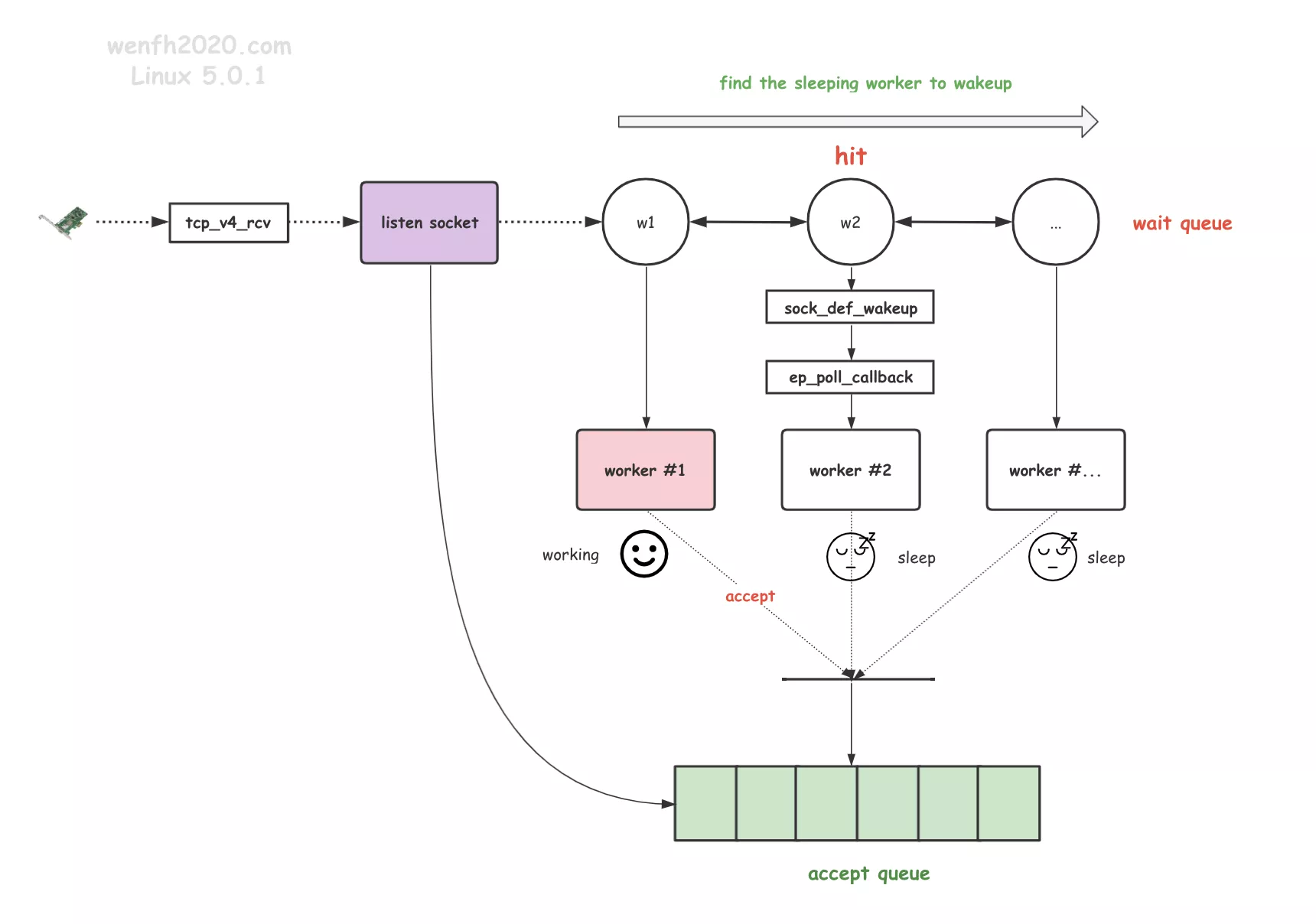
探索惊群 ①
惊群比较抽象,类似于抢红包 😁。它多出现在高性能的多进程/多线程服务中,例如:nginx。
探索惊群系列文章将深入 Linux (5.0.1) 内核,透过多进程模型去剖析惊群现象、惊群原理、惊群的解决方案。
-
[内核源码] 网络协议栈 - tcp 三次握手状态
走读网络协议栈 tcp 的内核源码(Linux - 5.0.1 下载)。通过 Linux 内核源码理解 tcp 三次握手状态变化。
因为我走读的是 Linux 5.0.1 源码,与旧版的 Linux 3.x 系列比较,新版的三次握手的状态已经发生改变,这个需要注意一下。
-
即时通讯方案
im - 即时通讯,支持功能:文字 + 音视频 + 文件传输。分布式服务架构,支持海量用户。
-
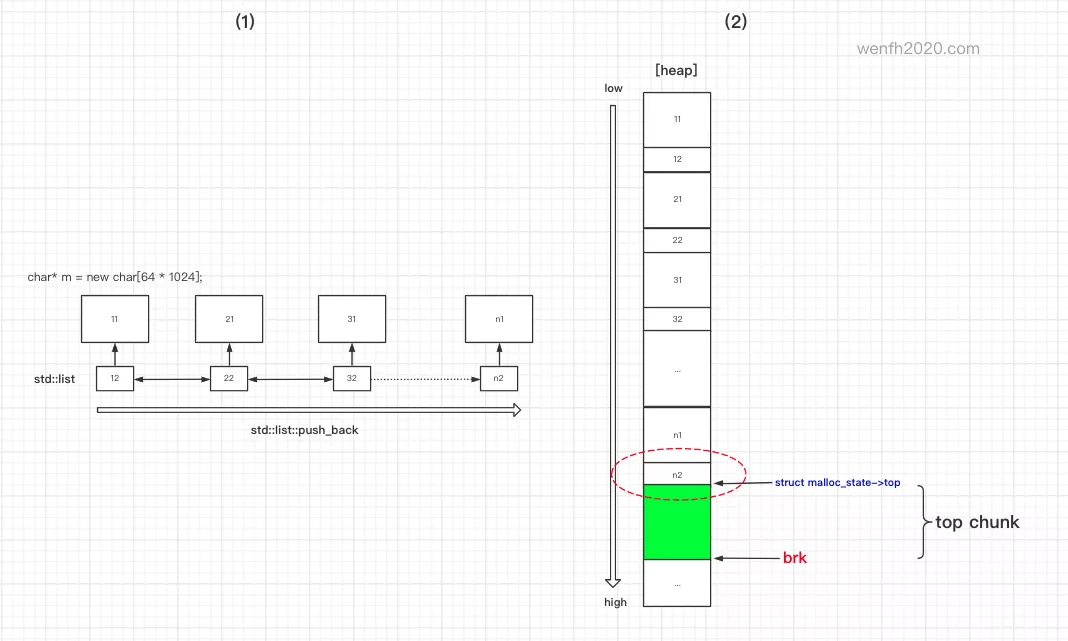
剖析 stl + glibc “内存泄漏” 原因
最近项目增加了一个模块,在 Centos 系统压测,进程一直不释放内存。因为新增代码量不多,经过排查,发现 stl + glibc 这个经典组合竟然有问题,见鬼了!
通过调试和查阅 glibc 源码,好不容易才搞明白它 “泄漏” 的原因:
内存碎片!碎片将大块的空闲连续内存块割裂,导致空闲内存块没有达到返还系统的阈值,内存回收失败!
深层原因:glibc 内部内存池管理空闲内存的策略问题,
ptmalloc2内存池的fast bins快速缓存和top chunk内存返还系统的特点导致。
-
[co_kimserver] co_kimserver 简介
co_kimserver 是笔者基于协程库 libco 开发的一个支持分布式微服务的高性能 TCP 网络通信框架。
详细请查看:github 。
-
[libco] 协程栈空间
协程“栈”空间,有独立栈和共享栈,重点理解一下协程共享栈。
-
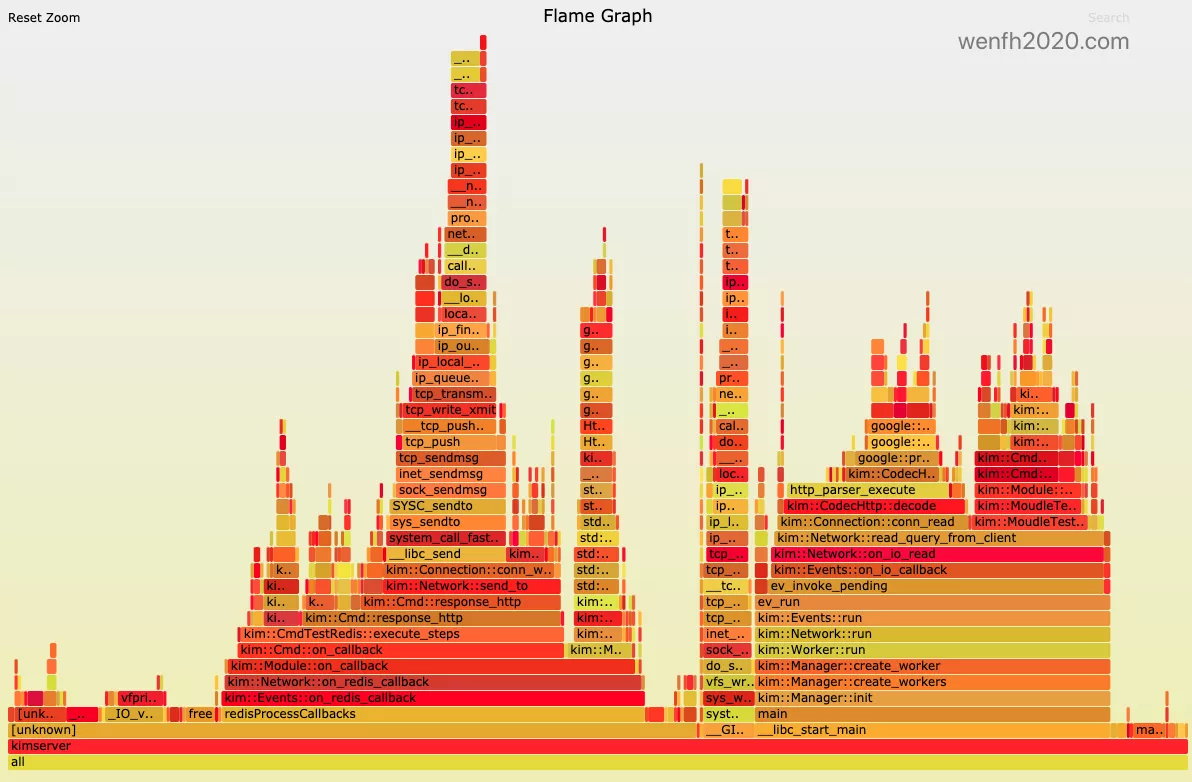
Linux 软件性能分析--火焰图 🔥
火焰图是一种基于 SVG 格式的矢量图,由 Linux
perf性能分析工具采集的采样数据生成。它通过将软件在系统中的运行行为采样数据转化为图形化展示,为性能分析提供直观的可视化结果。
-
[内核源码] epoll lt / et 模式区别
走读 Linux 内核源码(5.0.1),理解 epoll 的 lt / et 模式区别:
- 两个模式,事件通知方式不同,lt 持续通知直到处理事件完毕,et 一般只通知一次,不管事件是否处理完毕。
- et 模式,可以使得就绪队列上的新的就绪事件能被快速处理。
- et 模式,可以避免共享 “epoll fd” 场景下,发生类似 惊群问题。
epoll 详细信息参考《[epoll 源码走读] epoll 实现原理》。
-
[nginx 源码走读] 内存池
Nginx 内存池 (ngx_palloc.c) 专为优化小内存操作而设计。它通过将多次细碎的内存申请汇聚为少量批次请求,减少了与操作系统底层分配器的直接交互,以此提升整体性能。
该内存池作为一种轻量级实现,其小内存分配器采用了
下次适配算法。该算法从上次成功分配的地址开始线性扫描,并选择第一个足够大的空闲内存块。这种策略旨在减少搜索开销,并利用缓存局部性原理。
-
[即时通讯] 千人群组-消息管理
即时通讯,消息有多种类型,单聊,群聊等等。
群组聊天消息管理比较麻烦,因为涉及到多个用户,尤其是千人群组,1 个人发送消息,999 个人接收,数据库针对每个用户存储一条记录吗?这个量级的数据存储是十分恐怖的,所以消息的存储策略显得十分重要。
-
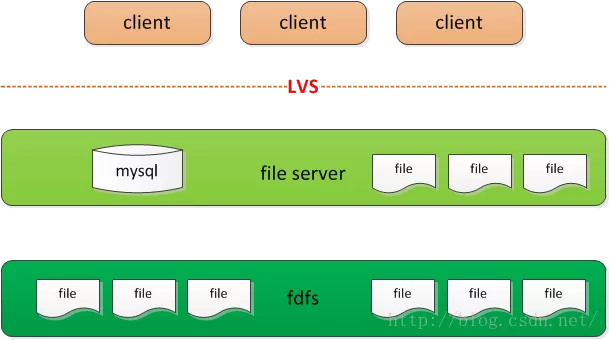
文件服务器架构逻辑
客户端 <–> 文件服务器代理 <–> FDFS
![[network] 记一次网站网络流量优化](/images/2025/2025-10-31-00-46-32.webp)
![[内核源码] 浅析 CFS 完全公平调度器工作原理](/images/2025/2025-04-17-00-46-32.webp)
![[C++] 提高 C++ 项目编译速度的神兵利器](/images/2024/2024-11-29-11-26-01.webp)
![[C++] Google Authenticator 算法实现](/images/2024/2024-10-16-08-49-06.webp)
![[算法] 一致性哈希算法](/images/2024/2024-01-08-09-56-44.webp)
![[C++] 浅析 std::share_ptr 内部结构](/images/2023/2024-01-05-10-42-53.webp)
![[Redis] 浅析 Redis 并发模型](/images/2023/2023-12-28-08-47-16.webp)
![[QT] 浅析信号与槽](/images/2023/2023-07-25-11-13-45.webp)
![[C++] C++ 有什么好用的线程池?](/images/2023/2023-02-13-23-39-27.webp)
![[C++] 深入探索 C++ 多态 ① - 虚函数调用链路](/images/2023/2023-08-16-12-15-41.webp)
![[stl 源码分析] std::sort](/images/2022/2022-02-23-17-12-00.webp)
![[内核源码] Linux 网络数据接收流程(TCP)- NAPI](/images/2021/2021-12-30-12-33-29.webp)
![[内核源码] 网络协议栈 - tcp 三次握手状态](/images/2021/2021-08-18-13-26-18.webp)
![[co_kimserver] co_kimserver 简介](/images/2021/2021-03-25-16-54-26.webp)
![[libco] 协程栈空间](/images/2021/2021-03-17-13-46-03.webp)
![[内核源码] epoll lt / et 模式区别](/images/2023/2023-07-01-16-02-17.webp)
![[nginx 源码走读] 内存池](/images/2020/2020-04-25-17-15-19.webp)
![[即时通讯] 千人群组-消息管理](/images/2023/2023-10-29-15-13-42.webp)