惊群比较抽象,类似于抢红包 😁。它多出现在高性能的多进程/多线程服务中,例如:nginx。
探索惊群 系列文章将深入 Linux (5.0.1) 内核,透过 多进程模型 去剖析惊群现象、惊群原理、惊群的解决方案。
- 探索惊群 ①(★)
- 探索惊群 ② - accept
- 探索惊群 ③ - nginx 惊群现象
- 探索惊群 ④ - nginx - accept_mutex
- 探索惊群 ⑤ - nginx - NGX_EXCLUSIVE_EVENT
- 探索惊群 ⑥ - nginx - reuseport
- 探索惊群 ⑦ - 文件描述符透传
1. 概述
1.1. 惊群现象
多进程睡眠等待 共享 资源,当资源到来时,多个进程被 无差别 唤醒,争抢处理资源。
1.2. 惊群影响
惊群问题影响的本质:内耗,具体表现为:
| 问题 | 描述 |
|---|---|
| 系统资源开销巨大 | 大量进程/线程被频繁唤醒,但仅有少数能成功获取资源,其余大多数在尝试失败后被迫立即休眠。这种持续的“唤醒-竞争-失败-休眠”循环,导致进程上下文切换次数激增,造成CPU时间的无谓浪费,系统空转严重。 |
| 资源分配严重不均 | 多个进程/线程无序争抢共享资源,缺乏高效的协调机制。这容易导致“马太效应”,即少数进程可能长期垄断资源,而其他多数进程则陷入资源匮乏的困境,损害了系统的公平性与整体性能。 |
| 系统吞吐量显著下降 | 宝贵的 CPU 计算周期被大量耗费在进程调度和内部竞争上,而非用于处理实际业务。这直接导致系统在单位时间内完成的有效工作量(即吞吐量)急剧降低,无法充分发挥硬件性能。 |
| 请求响应延迟增加 | 一个本可以被快速处理的请求,可能因为陷入与大量无效唤醒进程的竞争队列中,而导致其处理时间被显著拉长。这对追求低延迟的服务(如数据库、实时通信)是致命的。 |
| 系统可扩展性变差 | 惊群效应会随着并发数的增加而急剧恶化。系统规模越大,被同时唤醒的进程越多,竞争就越激烈,性能损耗呈非线性增长。这使得系统无法通过简单地增加工作进程数来提升性能,严重制约了水平扩展能力。 |
| 稳定性风险与“饿死”现象 | 在极端情况下,持久的资源分配不均可能导致某些进程长期无法获得资源(即被“饿死”)。同时,高频度的竞争可能大幅增加调度延迟,在实时或高可用性系统中,甚至可能触发看门狗超时,导致进程被误杀,引发服务中断。 |
1.3. 惊群原因
问题本质:进程睡眠 唤醒 时机问题。
多进程/线程等待共享资源,当资源到来时,多进程/线程被 无差别 唤醒争抢资源,缺乏有效的资源分配调度机制。
详细请参考:探索惊群 ③ - nginx 惊群现象
2. 解决方案
需要围绕两个方面去展开。
- 避免共享资源争抢(独占)。
- 资源尽量合理分配(负载均衡)。
换个角度去思考,如果红包私发,而不是扔进群组里… 这个思路应该是解决惊群问题的关键。😎
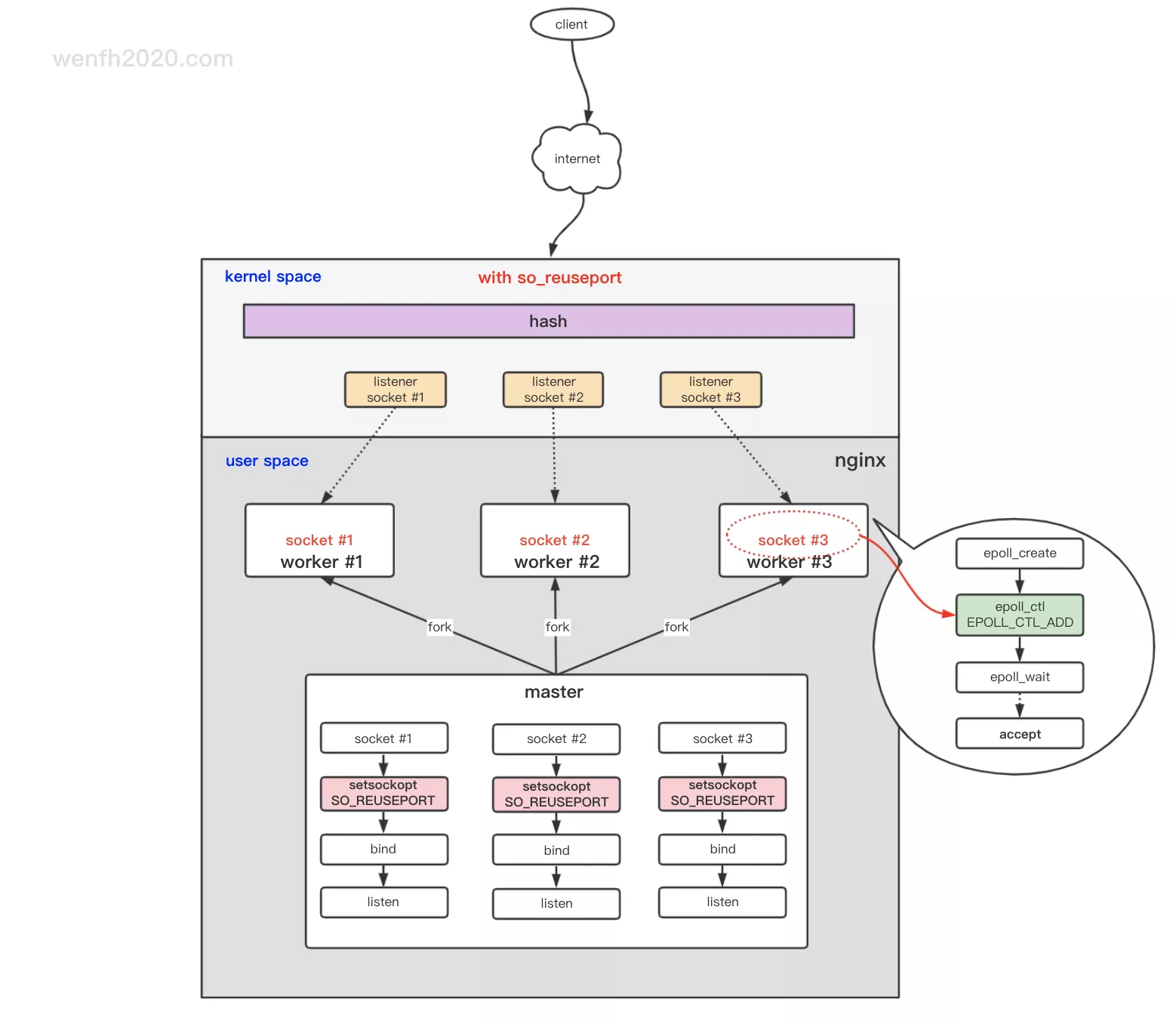
2.1. reuseport
内核解决惊群问题,目前 nginx 最好的惊群解决方案,基于 linux 内核 so_reuseport 端口重用网络特性。
- 每个子进程拥有独立的 listen socket 资源队列,避免资源争抢;多个队列也提升了并发吞吐。
- 新链接通过网络四元组通过哈希分配到各个子进程的 listen socket 资源队列,资源分配相对合理(负载均衡)。
详情请参考:探索惊群 ⑥ - nginx - reuseport / [内核源码] 网络协议栈 - listen (tcp)
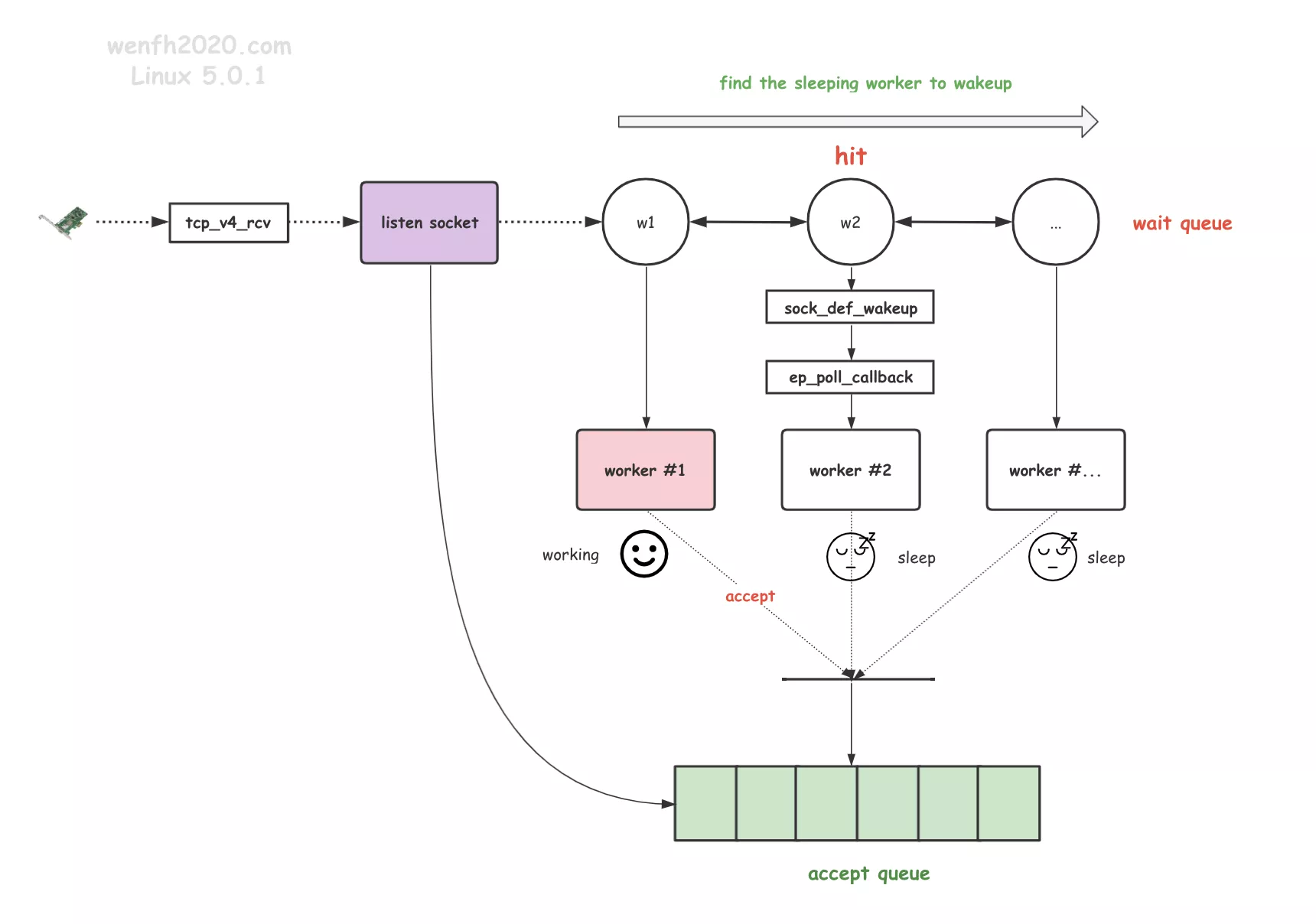
2.2. NGX_EXCLUSIVE_EVENT
内核解决惊群问题,基于 linux 4.5+ 内核增加的 epoll 属性 EPOLLEXCLUSIVE 独占资源属性。
原理非常简单,只唤醒一个睡眠等待的进程处理资源。避免无差别地唤醒多个进程,尽量使得各个进程忙碌起来。
缺点:
- 多个进程争抢一个 listen socket 的共享资源。
- 单个资源队列,将会是并发吞吐瓶颈。
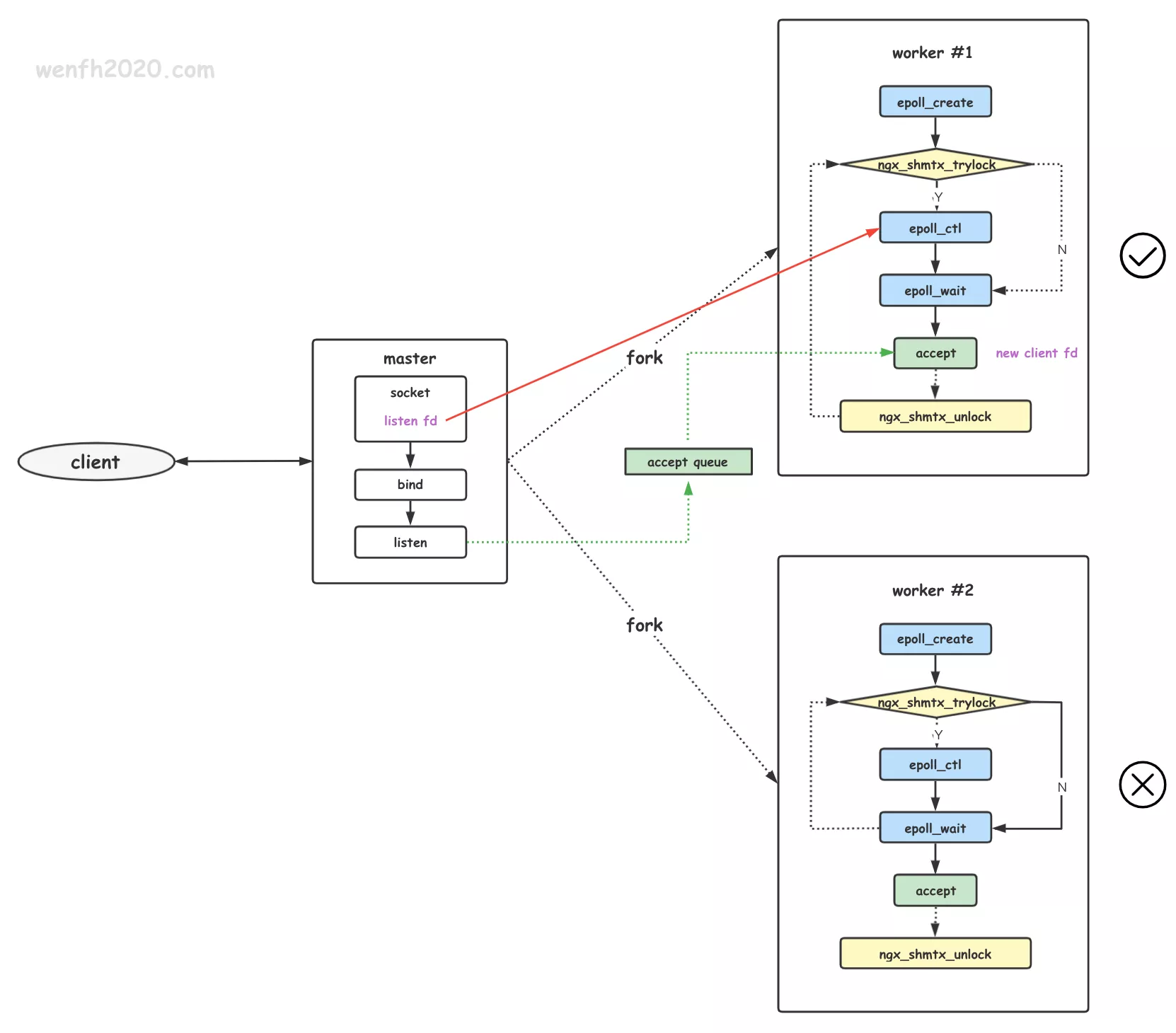
2.3. accept_mutex
应用层解决惊群问题,多个子进程通过应用层抢锁,成功者可以独占 listen socket 获取资源的权利。
优点:有效地避免了惊群。
缺点:
- 因为抢锁时机问题,原来抢到锁的进程下次抢到锁的概率很高,导致有些进程很忙,有些没那么忙,负载不均,资源利用率比较低。
- 一个时间段内,只有一个子进程独占 listen socket 的共享资源,无法同时利用多核优势。
- 单个资源队列,将会是并发吞吐瓶颈。