基于 libco 的 mysql 连接池,支持基本的 mysql 读写访问,支持多个连接,多个节点,支持空闲连接回收。
1. 设计
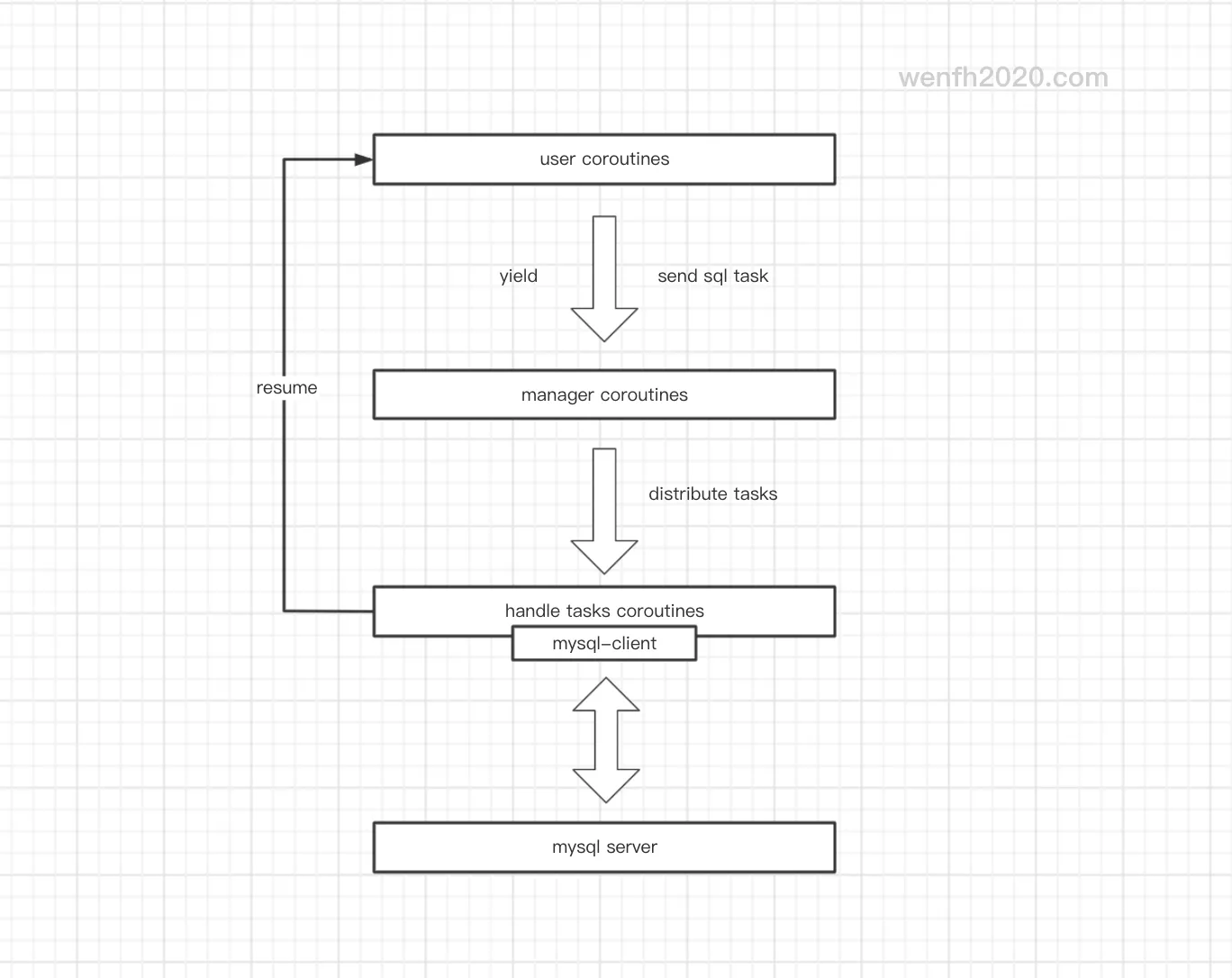
mysql 连接池,每个链接被分配到一个协程里运行。主要有几部分组成,详见下图:
- 当用户协程访问 mysql 时,这个请求以任务形式,添加
manager的任务队列,然后用户协程切出去等待唤醒。 manager协程主要负责链接调度,还有任务分派,它将一定数量的任务分配给比较空闲的连接处理。- 任务处理协程,被分派到任务,开始处理任务。
- 任务被处理后,返回结果,切回到用户协程。
2. 调度
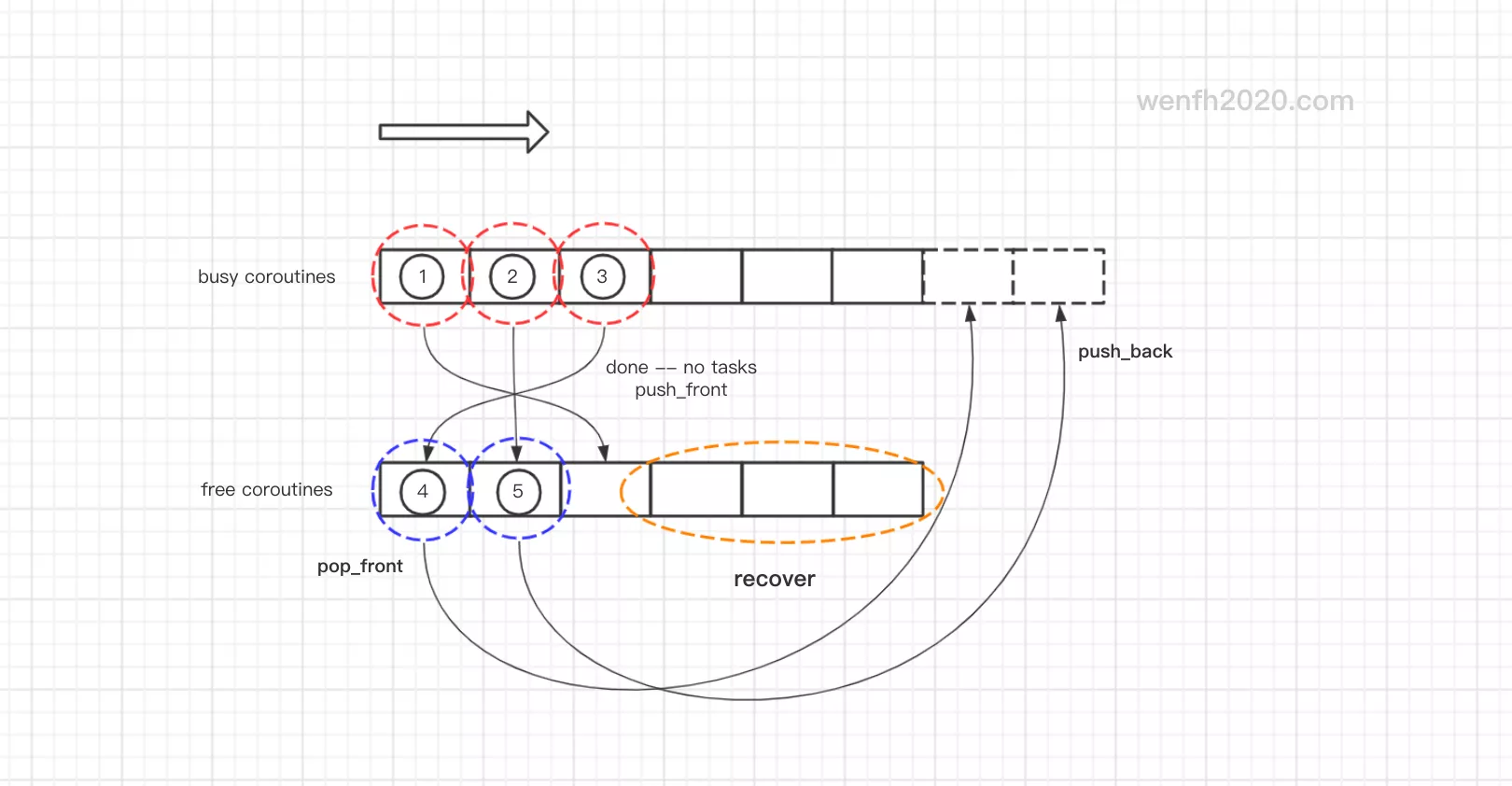
调度功能:任务分配,连接调度,空闲连接回收。
连接池维护了两个链接链表:free 链表,busy 链表。类似于 lru 算法,用户层过来的任务,应该分派给最空闲的连接处理。
- 如果 free 链表有空闲连接,那么 manager 协程,取 free 链表头部连接,并将一定数量任务分配给空闲连接,然后将这个连接放进 busy 队列的尾部。
- 如果 busy 连接将任务都处理完了,说明它已经空闲了,那么将这个连接从 busy 链表中取出,放入 free 链表的头部。
- 如果 free 链表没有空闲连接,那么 manager 从 busy 链表取头部连接,将一定数量任务分配给它,并将它放进 busy 链表的尾部。
以上操作,当系统空闲情况下,free 链表尾部部分一定会是 最闲 的链接,那么将会在定时器里进行回收。
为什么要那么费劲对 mysql 连接进行回收呢?因为 mysql 并发不像 redis 那么高,所以忙时都是几十条连接一起跑去解决吞吐问题,闲时不回收就有点浪费资源了。
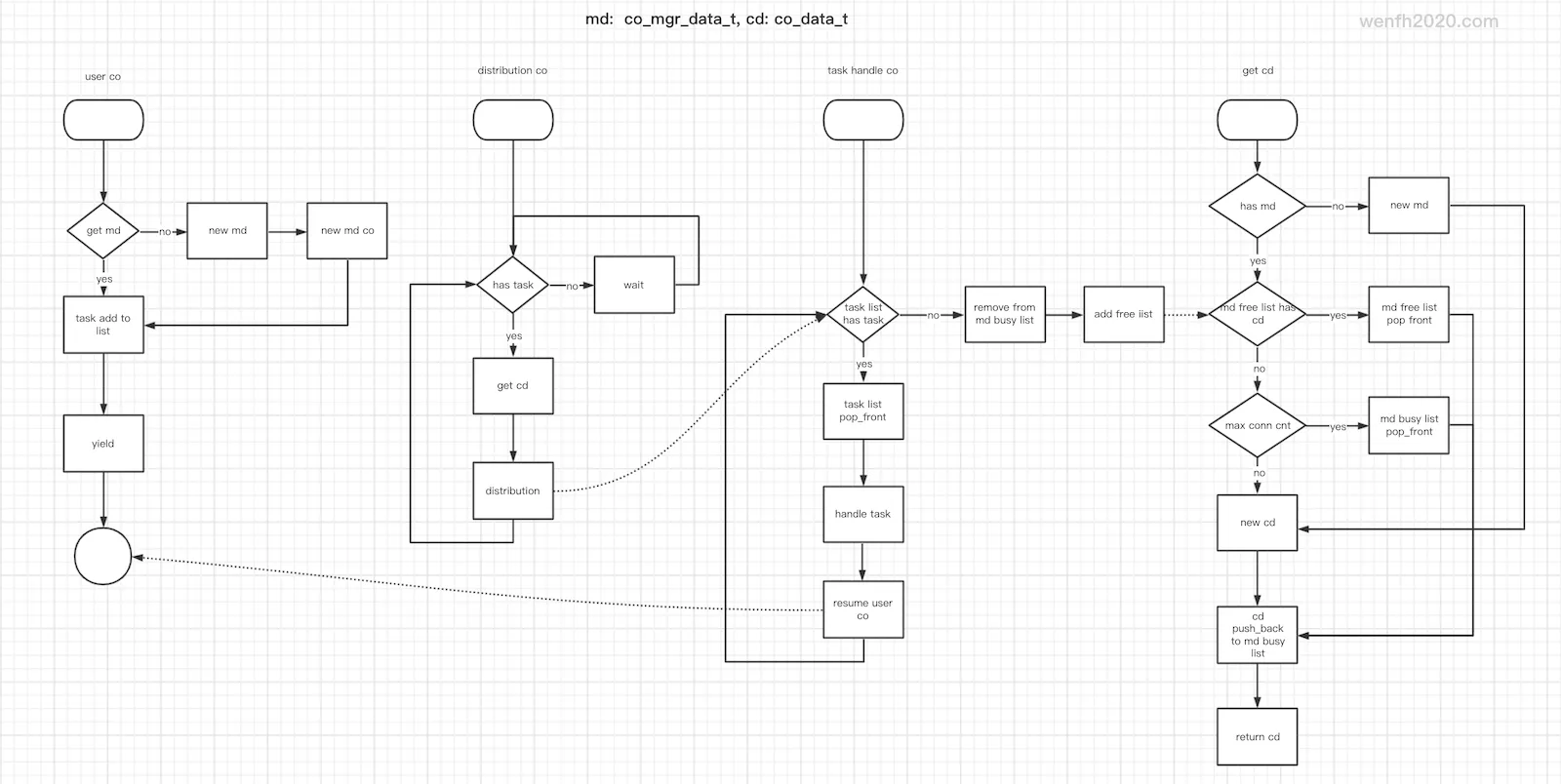
3. 逻辑
连接池实现的相关逻辑,一开始实现时感觉挺复杂的,画好流程图后,思路清晰了许多。代码就不贴了,放到 github 上了(mysql_mgr.h,mysql_mgr.cpp),有兴趣的朋友可以看看。
4. 压测
压测 10000 个用户协程,每个协程 100 个读命令;单线程连接池:10 个 mysql 连接,并发能力:10858 / s。(压测源码)
- 压测结果。
1
2
# ./test_mysql_mgr r 10000 100
total cnt: 1000000, total time: 92.092119, avg: 10858.692482
- 配置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# ./co_kimserver/bin/config.json
{
...
"database": {
"slowlog_log_slower_than": 300,
"nodes": {
"test": {
"host": "127.0.0.1",
"port": 3306,
"user": "root",
"password": "root123!@#",
"charset": "utf8mb4",
"max_conn_cnt": 10
}
}
},
...
}