协程“栈”空间,有独立栈和共享栈,重点理解一下协程共享栈。
1. 概述
libco 虽然支持海量协程,但是单线程,同一时刻只支持一个协程在工作。在一个时间段内,它通过调度,使多个协程不停切换,从而实现协程“并发”功能。
协程“栈”空间,有独立栈,也有共享栈。这个“栈”添加了引号,其实它是在堆上分配的,因为它的协程函数工作原理与普通函数工作原理差不多,所以才叫“栈”。
普通函数运行原理:《x86_64 函数运行时栈帧内存布局》
2. 独立栈
协程独立栈默认使用 128k 内存空间,简单方便,一般程序使用也足够了,但是它也有缺点:
- 如果某个协程函数使用栈空间超过 128 k,那么内存会溢出,导致进程崩溃。(当然共享栈也会,但是没那么容易溢出。)
- 协程独立栈虽然默认只需要 128 k 内存,但是绝大多数使用场景,内存比这个少,每个协程分配固定的资源,还是有点浪费了。
- libco 号称支持千万级协程,如果每个协程都是独立栈,那得废多少内存?!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct stCoRoutine_t* co_create_env(stCoRoutineEnv_t* env,
const stCoRoutineAttr_t* attr,
pfn_co_routine_t pfn, void* arg) {
stCoRoutineAttr_t at;
if (attr) {
memcpy(&at, attr, sizeof(at));
}
if (at.stack_size <= 0) {
/* 独立栈默认 128 k。 */
at.stack_size = 128 * 1024;
} else if (at.stack_size > 1024 * 1024 * 8) {
at.stack_size = 1024 * 1024 * 8;
}
...
}
3. 共享栈
基于上述独立栈的缺点,共享栈应运而生。
- 共享栈协程,协程在创建时,被分配在指定的共享栈内存块上工作。
- 当然只有正在执行的协程,才会使用共享栈,当它被(yield)切换出来后,它需要保存协程上下文:寄存器数据 + 内存数据,所以共享栈上的使用部分(不是整个共享栈空间)会被拷贝出来。
- 同理新切入的协程,需要将以前保存的内存上下文,重新拷贝到共享栈上工作。
- 内存拷贝不是必然的,因为有多个共享内存块,每个块都会被指派给多个协程,只有当相同共享栈上的协程切换才会出现内存拷贝。
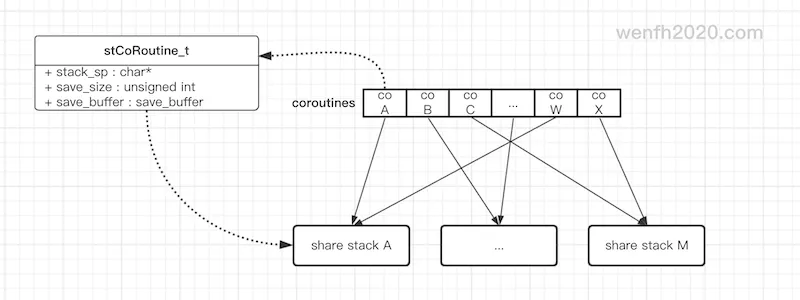
- 共享栈,协程栈空间指向指定共享栈空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
struct stCoRoutine_t* co_create_env(stCoRoutineEnv_t* env,
const stCoRoutineAttr_t* attr,
pfn_co_routine_t pfn, void* arg) {
...
stStackMem_t* stack_mem = NULL;
if (at.share_stack) {
stack_mem = co_get_stackmem(at.share_stack);
at.stack_size = at.share_stack->stack_size;
} else {
stack_mem = co_alloc_stackmem(at.stack_size);
}
lp->stack_mem = stack_mem;
...
}
static stStackMem_t* co_get_stackmem(stShareStack_t* share_stack) {
if (!share_stack) {
return NULL;
}
int idx = share_stack->alloc_idx % share_stack->count;
share_stack->alloc_idx++;
return share_stack->stack_array[idx];
}
- co_swap 协程切换函数很特别,
coctx_swap上面代码还是是协程 A,下面部分就是协程 B 了。
1
2
3
4
5
6
void co_swap(stCoRoutine_t *curr, stCoRoutine_t *pending_co) {
// A coroutine.
// swap context
coctx_swap(&(curr->ctx), &(pending_co->ctx));
// B coroutine.
}
- 协程在切换过程中,内存拷贝。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
void co_swap(stCoRoutine_t* curr, stCoRoutine_t* pending_co) {
stCoRoutineEnv_t* env = co_get_curr_thread_env();
// get curr stack sp
char c;
/* 记录当前协程空间栈底位置,
* 因为函数局部变量都是通过压栈进入内存的,地址从高到低)。*/
curr->stack_sp = &c;
if (!pending_co->cIsShareStack) {
...
} else {
/* 因为 coctx_swap 上下代码已经不是同一个协程了,需要 env
* 保存信息,方便不同协程使用。 */
env->pending_co = pending_co;
// get last occupy co on the same stack mem
stCoRoutine_t* occupy_co = pending_co->stack_mem->occupy_co;
// set pending co to occupy thest stack mem;
pending_co->stack_mem->occupy_co = pending_co;
env->occupy_co = occupy_co;
/* 不一定需要内存拷贝啊,新切换的协程,可能落在其它共享栈上。*/
if (occupy_co && occupy_co != pending_co) {
/* 当前协程被切出来了,需要从共享栈上保存它的内存上下文。 */
save_stack_buffer(occupy_co);
}
}
/* 协程切换,切换上下文。 */
coctx_swap(&(curr->ctx), &(pending_co->ctx));
// stack buffer may be overwrite, so get again;
stCoRoutineEnv_t* curr_env = co_get_curr_thread_env();
stCoRoutine_t* update_occupy_co = curr_env->occupy_co;
stCoRoutine_t* update_pending_co = curr_env->pending_co;
/* 不一定需要内存拷贝啊,新切换的协程,可能落在其它的共享栈上。*/
if (update_pending_co && update_occupy_co != update_pending_co) {
/* 当前共享栈上,当前协程是新切换进来的,
* 那么需要把它的前面保存的内存上下文,拷贝到共享栈上运行。*/
if (update_pending_co->save_buffer &&
update_pending_co->save_size > 0) {
memcpy(update_pending_co->stack_sp, update_pending_co->save_buffer,
update_pending_co->save_size);
}
}
}
4. 小结
- 独立栈相对简单,但废内存,容易栈溢出。
- 共享栈使用公共资源,公共资源内存空间比较大,相对安全,节省内存空间,但是协程频繁切换需要进行内存拷贝,废 CPU。
- 独立栈和共享栈的实现逻辑并不复杂,协程原理理解关键在切换。

