文章主要对 tcp 通信进行 epoll 源码走读。
Linux 源码:Linux 5.7 版本。epoll 核心源码:eventpoll.h / eventpoll.c。
搭建 epoll 内核调试环境视频:vscode + gdb 远程调试 linux (EPOLL) 内核源码
1. 应用场景
epoll 应用,适合海量用户,一个时间段内部分活跃的用户群体。
例如 app,正常用户并不是 24 小时都拿起手机玩个不停,可能玩一下,又去干别的事,回头又玩一下,断断续续地操作。即便正在使用 app 也不是连续产生读写通信事件,可能手指点击几下页面,页面产生需要的内容,用户就去浏览内容,不再操作了。换句话说,在海量用户里,同一个时间段内,很可能只有一小部分用户正在活跃,而在这一小部分活跃用户里,又只有一小撮人同时点击页面上的操作。那 epoll 管理海量用户,只需要将这一小撮人产生的事件,及时通知 appserver 处理逻辑即可。
2. 预备知识
- 走读 epoll 源码前,先熟悉内核相关工作流程:[epoll 源码走读] epoll 源码实现-预备知识。
- 走读源码过程中,可以通过 Linux 文档 搜索 epoll 相关知识。
3. 使用
- 接口。
| 接口 | 描述 |
|---|---|
| epoll_create | 创建 epoll。 |
| epoll_ctl | fd 事件注册函数,用户通过这个函数关注 fd 读写事件。 |
| epoll_wait | 阻塞等待 fd 事件发生。 |
- 使用流程。
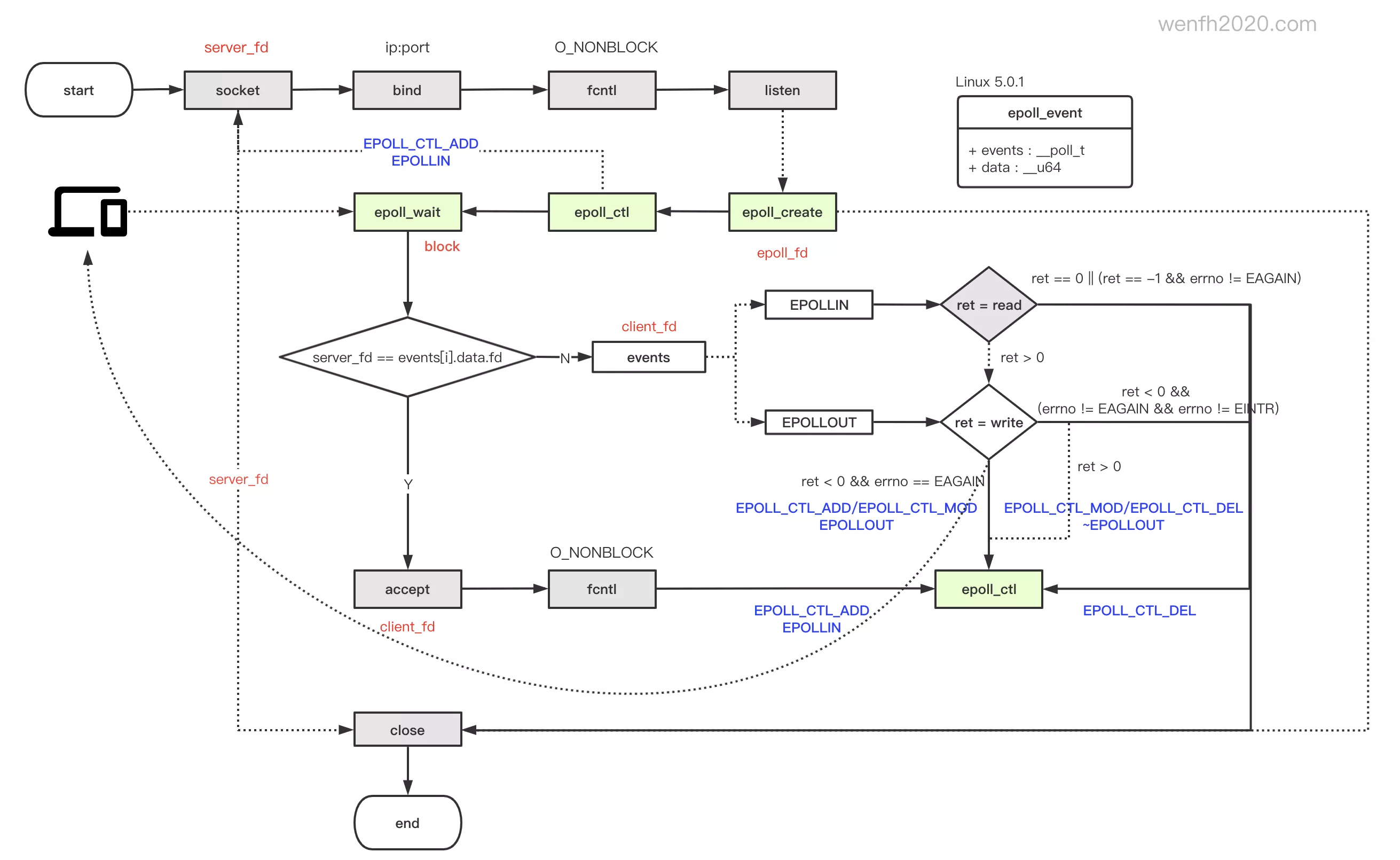
图片来源:《epoll 多路复用 I/O工作流程》
4. 事件
常用事件注释可以请参考 epoll_ctl 文档。
1
2
3
4
5
6
7
8
// eventpoll.h
#define EPOLLIN (__force __poll_t)0x00000001
#define EPOLLOUT (__force __poll_t)0x00000004
#define EPOLLERR (__force __poll_t)0x00000008
#define EPOLLHUP (__force __poll_t)0x00000010
#define EPOLLRDHUP (__force __poll_t)0x00002000
#define EPOLLEXCLUSIVE ((__force __poll_t)(1U << 28))
#define EPOLLET ((__force __poll_t)(1U << 31))
| 事件 | 描述 |
|---|---|
| EPOLLIN | 有可读数据到来。 |
| EPOLLOUT | 有数据要写。 |
| EPOLLERR | 该文件描述符发生错误。 |
| EPOLLHUP | 该文件描述符被挂断。常见 socket 被关闭(read == 0)。 |
| EPOLLRDHUP | 对端已关闭链接,或者用 shutdown 关闭了写链接。 |
| EPOLLEXCLUSIVE | 唯一唤醒事件,主要为了解决 epoll_wait 惊群问题。多线程下多个 epoll_wait 同时等待,只唤醒一个 epoll_wait 执行。 该事件只支持 epoll_ctl 添加操作 EPOLL_CTL_ADD。 |
| EPOLLET | 边缘触发模式。 |
通过 tcp_poll 函数,可以看到 socket 事件对应的相关事件逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
// tcp.c
/*
* Wait for a TCP event.
*
* Note that we don't need to lock the socket, as the upper poll layers
* take care of normal races (between the test and the event) and we don't
* go look at any of the socket buffers directly.
*/
__poll_t tcp_poll(struct file *file, struct socket *sock, poll_table *wait) {
__poll_t mask;
struct sock *sk = sock->sk;
const struct tcp_sock *tp = tcp_sk(sk);
int state;
// fd 添加等待事件,关联事件回调。
sock_poll_wait(file, sock, wait);
// socket 对应事件逻辑。
state = inet_sk_state_load(sk);
if (state == TCP_LISTEN)
return inet_csk_listen_poll(sk);
/* Socket is not locked. We are protected from async events
* by poll logic and correct handling of state changes
* made by other threads is impossible in any case.
*/
mask = 0;
/*
* EPOLLHUP is certainly not done right. But poll() doesn't
* have a notion of HUP in just one direction, and for a
* socket the read side is more interesting.
*
* Some poll() documentation says that EPOLLHUP is incompatible
* with the EPOLLOUT/POLLWR flags, so somebody should check this
* all. But careful, it tends to be safer to return too many
* bits than too few, and you can easily break real applications
* if you don't tell them that something has hung up!
*
* Check-me.
*
* Check number 1. EPOLLHUP is _UNMASKABLE_ event (see UNIX98 and
* our fs/select.c). It means that after we received EOF,
* poll always returns immediately, making impossible poll() on write()
* in state CLOSE_WAIT. One solution is evident --- to set EPOLLHUP
* if and only if shutdown has been made in both directions.
* Actually, it is interesting to look how Solaris and DUX
* solve this dilemma. I would prefer, if EPOLLHUP were maskable,
* then we could set it on SND_SHUTDOWN. BTW examples given
* in Stevens' books assume exactly this behaviour, it explains
* why EPOLLHUP is incompatible with EPOLLOUT. --ANK
*
* NOTE. Check for TCP_CLOSE is added. The goal is to prevent
* blocking on fresh not-connected or disconnected socket. --ANK
*/
if (sk->sk_shutdown == SHUTDOWN_MASK || state == TCP_CLOSE)
mask |= EPOLLHUP;
if (sk->sk_shutdown & RCV_SHUTDOWN)
mask |= EPOLLIN | EPOLLRDNORM | EPOLLRDHUP;
/* Connected or passive Fast Open socket? */
if (state != TCP_SYN_SENT &&
(state != TCP_SYN_RECV || rcu_access_pointer(tp->fastopen_rsk))) {
int target = sock_rcvlowat(sk, 0, INT_MAX);
if (READ_ONCE(tp->urg_seq) == READ_ONCE(tp->copied_seq) &&
!sock_flag(sk, SOCK_URGINLINE) &&
tp->urg_data)
target++;
if (tcp_stream_is_readable(tp, target, sk))
mask |= EPOLLIN | EPOLLRDNORM;
if (!(sk->sk_shutdown & SEND_SHUTDOWN)) {
if (sk_stream_is_writeable(sk)) {
mask |= EPOLLOUT | EPOLLWRNORM;
} else { /* send SIGIO later */
sk_set_bit(SOCKWQ_ASYNC_NOSPACE, sk);
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
/* Race breaker. If space is freed after
* wspace test but before the flags are set,
* IO signal will be lost. Memory barrier
* pairs with the input side.
*/
smp_mb__after_atomic();
if (sk_stream_is_writeable(sk))
mask |= EPOLLOUT | EPOLLWRNORM;
}
} else
mask |= EPOLLOUT | EPOLLWRNORM;
if (tp->urg_data & TCP_URG_VALID)
mask |= EPOLLPRI;
} else if (state == TCP_SYN_SENT && inet_sk(sk)->defer_connect) {
/* Active TCP fastopen socket with defer_connect
* Return EPOLLOUT so application can call write()
* in order for kernel to generate SYN+data
*/
mask |= EPOLLOUT | EPOLLWRNORM;
}
/* This barrier is coupled with smp_wmb() in tcp_reset() */
smp_rmb();
if (sk->sk_err || !skb_queue_empty_lockless(&sk->sk_error_queue))
mask |= EPOLLERR;
return mask;
}
EXPORT_SYMBOL(tcp_poll);
5. 源码工作流程
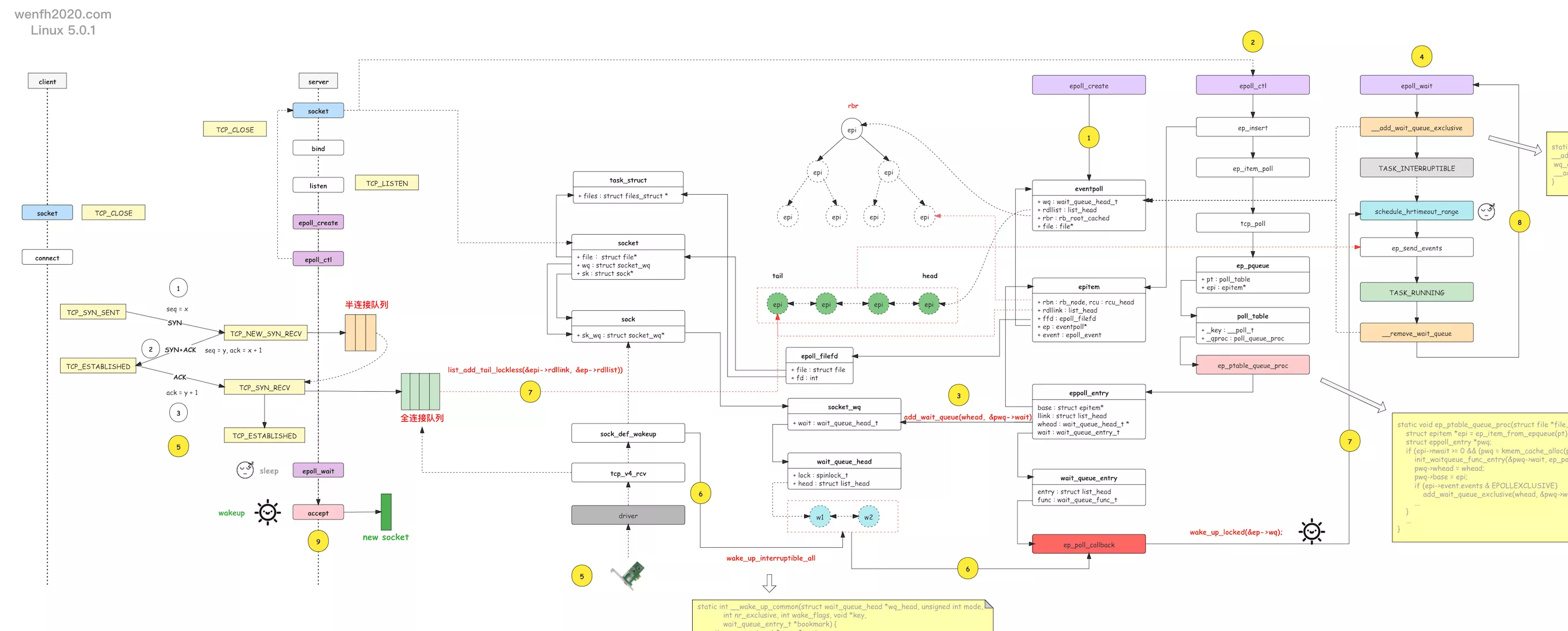
6. 数据结构
6.1. eventpoll
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
/*
* This structure is stored inside the "private_data" member of the file
* structure and represents the main data structure for the eventpoll
* interface.
*/
struct eventpoll {
/*
* This mutex is used to ensure that files are not removed
* while epoll is using them. This is held during the event
* collection loop, the file cleanup path, the epoll file exit
* code and the ctl operations.
*/
struct mutex mtx;
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;
/* Wait queue used by file->poll() */
wait_queue_head_t poll_wait;
/* List of ready file descriptors */
struct list_head rdllist;
/* Lock which protects rdllist and ovflist */
rwlock_t lock;
/* RB tree root used to store monitored fd structs */
struct rb_root_cached rbr;
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transferring ready events to userspace w/out
* holding ->lock.
*/
struct epitem *ovflist;
/* wakeup_source used when ep_scan_ready_list is running */
struct wakeup_source *ws;
/* The user that created the eventpoll descriptor */
struct user_struct *user;
struct file *file;
/* used to optimize loop detection check */
int visited;
struct list_head visited_list_link;
#ifdef CONFIG_NET_RX_BUSY_POLL
/* used to track busy poll napi_id */
unsigned int napi_id;
#endif
};
| 成员 | 描述 |
|---|---|
| mtx | 互斥变量,避免在遍历 epi 节点时(例如 ep_send_events),epi 被删除。 |
| wq | 等待队列,当 epoll_wait 没发现就绪事件需要处理,添加等待事件,需要睡眠阻塞等待唤醒进程。 |
| poll_wait | 等待队列,当epoll_ctl 监听的是另外一个 epoll fd 时使用。 |
| rdllist | 就绪列表,产生了用户注册的 fd读写事件的 epi 链表。 |
| ovflist | 单链表,当 rdllist 被锁定遍历,向用户空间发送数据时,rdllist 不允许被修改,新触发的就绪 epitem 被 ovflist 串联起来,等待 rdllist 被处理完了,重新将 ovflist 数据写入 rdllist。 详看 ep_scan_ready_list 逻辑。 |
| user | 创建 eventpoll 的用户结构信息。 |
| lock | 锁,保护 rdllist 和 ovflist 。 |
| rbr | 红黑树根结点,管理 fd 结点。 |
| file | eventpoll 对应的文件结构,Linux 一切皆文件,用 vfs 管理数据。 |
| napi_id | 应用于中断缓解技术。 |
6.2. epitem
fd 事件管理节点。可以添加到红黑树,也可以串联成就绪列表或其它列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
/*
* Each file descriptor added to the eventpoll interface will
* have an entry of this type linked to the "rbr" RB tree.
* Avoid increasing the size of this struct, there can be many thousands
* of these on a server and we do not want this to take another cache line.
*/
struct epitem {
union {
/* RB tree node links this structure to the eventpoll RB tree */
struct rb_node rbn;
/* Used to free the struct epitem */
struct rcu_head rcu;
};
/* List header used to link this structure to the eventpoll ready list */
struct list_head rdllink;
/*
* Works together "struct eventpoll"->ovflist in keeping the
* single linked chain of items.
*/
struct epitem *next;
/* The file descriptor information this item refers to */
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
int nwait;
/* List containing poll wait queues */
struct list_head pwqlist;
/* The "container" of this item */
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct list_head fllink;
/* wakeup_source used when EPOLLWAKEUP is set */
struct wakeup_source __rcu *ws;
/* The structure that describe the interested events and the source fd */
struct epoll_event event;
};
| 成员 | 描述 |
|---|---|
| rbn | 连接红黑树结构节点。 |
| rdllink | 就绪队列节点,用于将 epitem 串联成就绪队列列表。 |
| next | 指向下一个单链表节点的指针。配合 eventpoll 的 ovflist 使用。 |
| ffd | 记录节点对应的 fd 和 file 文件信息。 |
| nwait | 等待队列个数。 |
| pwqlist | 等待事件回调队列。当数据进入网卡,底层中断执行 ep_poll_callback。 |
| ep | eventpoll 指针,epitem 关联 eventpoll。 |
| fllink | epoll 文件链表结点,与 epoll 文件链表进行关联 file.f_ep_links。参考 fs.h, struct file 结构。 |
| ws | EPOLLWAKEUP 模式下使用。 |
| event | 用户关注的事件。 |
6.3. epoll_filefd
fd 对应 file 文件结构,Linux 一切皆文件,采用了 vfs (虚拟文件系统)管理文件或设备。
1
2
3
4
struct epoll_filefd {
struct file *file;
int fd;
} __packed;
6.4. epoll_event
用户关注的 epoll 事件结构。
1
2
3
4
struct epoll_event {
__poll_t events;
__u64 data;
} EPOLL_PACKED;
| 成员 | 描述 |
|---|---|
| events | 事件集合 |
| data | fd |
6.5. poll_table_struct
就绪事件处理结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
/* poll.h
* Do not touch the structure directly, use the access functions
* poll_does_not_wait() and poll_requested_events() instead.
*/
typedef struct poll_table_struct {
poll_queue_proc _qproc;
__poll_t _key;
} poll_table;
/*
* structures and helpers for f_op->poll implementations
*/
typedef void (*poll_queue_proc)(struct file *, wait_queue_head_t *, struct poll_table_struct *);
| 成员 | 描述 |
|---|---|
| _qproc | 处理函数,可以指向 ep_ptable_queue_proc 函数,或者空。 |
| _key | 事件组合。 |
6.6. ep_pqueue
包装就绪事件处理结构,关联 epitem。
1
2
3
4
5
/* Wrapper struct used by poll queueing */
struct ep_pqueue {
poll_table pt;
struct epitem *epi;
};
| 成员 | 描述 |
|---|---|
| pt | 就绪事件处理结构。 |
| epi | epitem 对应节点。 |
7. 关键函数
| 函数 | 描述 |
|---|---|
| eventpoll_init | 初始化 epoll 模块。eventpoll 作为 Linux 内核的一部分,模块化管理。 |
| do_epoll_create | 为 eventpoll 结构分配资源。 |
| do_epoll_ctl | epoll 管理 fd 事件接口。 |
| do_epoll_wait | 有条件阻塞等待 fd 事件发生,返回对fd 和对应事件数据。 |
| ep_item_poll | 获取 fd 就绪事件,并关联 fd 和事件触发回调函数 ep_poll_callback。 |
| ep_poll_callback | fd 事件回调函数。当底层收到数据,中断调用 fd 关联的 ep_poll_callback 回调函数,如果事件是用户关注的事件,会将 fd 对应的 epi 结点添加进就绪队列,然后唤醒阻塞等待的 epoll_wait 处理。 |
| ep_send_events | 遍历就绪列表,拷贝内核空间就绪数据到用户空间。结合 ep_scan_ready_list 和 ep_send_events_proc 使用。 |
| ep_scan_ready_list | 遍历就绪列表。当 fd 收到数据,回调 ep_poll_callback,如果事件是用户关注的,那么将 fd 对应的 epi 结点添加到就绪队列,ep_scan_ready_list 会遍历这个就绪列表,将数据从内核空间拷贝到用户空间,或者其它操作。 |
| ep_send_events_proc | 内核将就绪列表数据,发送到用户空间。结合 ep_scan_ready_list 使用。LT/ET 模式在这个函数里实现。 |
| ep_ptable_queue_proc | 添加 fd 的等待事件到等待队列,关联 fd 与回调函数 ep_poll_callback。 |
8. 核心源码
8.1. 初始化
添加 epoll 模块到内核,slab 算法为 epoll 分配资源。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
static int __init eventpoll_init(void) {
struct sysinfo si;
...
/* Allocates slab cache used to allocate "struct epitem" items */
epi_cache = kmem_cache_create("eventpoll_epi", sizeof(struct epitem),
0, SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_ACCOUNT, NULL);
/* Allocates slab cache used to allocate "struct eppoll_entry" */
pwq_cache = kmem_cache_create("eventpoll_pwq",
sizeof(struct eppoll_entry), 0, SLAB_PANIC|SLAB_ACCOUNT, NULL);
return 0;
}
fs_initcall(eventpoll_init);
8.2. epoll_create
创建 eventpoll 对象,关联文件资源。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
static int do_epoll_create(int flags) {
int error, fd;
struct eventpoll *ep = NULL;
struct file *file;
...
// slab 算法为 eventpoll 结构分配内存,并初始化 eventpoll 成员数据。
error = ep_alloc(&ep);
if (error < 0)
return error;
// 分配一个空闲的文件描述符。
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
if (fd < 0) {
error = fd;
goto out_free_ep;
}
// slab 分配一个新的文件结构对象(struct file *)
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
if (IS_ERR(file)) {
error = PTR_ERR(file);
goto out_free_fd;
}
ep->file = file;
// fd 与 file* 结构进行绑定。
fd_install(fd, file);
return fd;
...
}
8.3. epoll_ctl
fd 对应的事件管理(增删改)。
- 添加 fd 事件管理流程:fd 关联回调 ep_poll_callback。
1
fd -> socket -> poll -> ep_ptable_queue_proc -> wait_queue -> ep_poll_callback
- 触发了 fd 关注的事件回调处理。
1
driver -> ep_poll_callback -> waitup -> epoll_wait(wake up)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event) {
struct epoll_event epds;
// 为了 event 数据的安全性,将数据进行拷贝,再进行逻辑处理。
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
return -EFAULT;
return do_epoll_ctl(epfd, op, fd, &epds, false);
}
int do_epoll_ctl(int epfd, int op, int fd, struct epoll_event *epds, bool nonblock) {
int error;
int full_check = 0;
struct fd f, tf;
struct eventpoll *ep;
struct epitem *epi;
struct eventpoll *tep = NULL;
...
// 检查参数合法性。
...
// 在 do_epoll_create 实现里 anon_inode_getfile 将 private_data 与 eventpoll 关联。
ep = f.file->private_data;
...
// 红黑树检查 fd 是否已经被添加。
epi = ep_find(ep, tf.file, fd);
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
/* epoll 如果没有添加过该 fd,就添加到红黑树进行管理。
* 事件默认关注异常处理(EPOLLERR | EPOLLHUP)。*/
epds->events |= EPOLLERR | EPOLLHUP;
error = ep_insert(ep, epds, tf.file, fd, full_check);
} else
error = -EEXIST;
if (full_check)
clear_tfile_check_list();
break;
case EPOLL_CTL_DEL:
if (epi)
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
case EPOLL_CTL_MOD:
if (epi) {
if (!(epi->event.events & EPOLLEXCLUSIVE)) {
epds->events |= EPOLLERR | EPOLLHUP;
error = ep_modify(ep, epi, epds);
}
} else
error = -ENOENT;
break;
}
...
return error;
}
static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check) {
// epoll 管理 fd 和对应事件节点 epitem 数据结构。
struct epitem *epi;
struct ep_pqueue epq;
...
epq.epi = epi;
// 初始化就绪事件处理函数调用。poll() 接口调用 ep_ptable_queue_proc。
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
// 添加等待队列,如果 fd 有用户关注的事件发生,返回对应 fd 关注的事件 revents。
revents = ep_item_poll(epi, &epq.pt, 1);
...
// 将当前节点,添加到 epoll 文件钩子,将 epoll 文件与 fd 对应文件串联起来。
list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links);
// 将节点添加进二叉树
ep_rbtree_insert(ep, epi);
// 如果有关注的事件发生,将节点关联到就绪事件列表。
if (revents && !ep_is_linked(epi)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
/* 如果进程正在睡眠等待,唤醒它去处理就绪事件。睡眠事件 ep->wq 在 epoll_wait 中添加*/
if (waitqueue_active(&ep->wq))
// 唤醒进程
wake_up(&ep->wq);
// 如果监控的是另外一个 epoll_create 的 fd,有就绪事件,也唤醒进程。
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
...
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return 0;
}
8.4. ep_item_poll
fd 节点就绪事件处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt, int depth) {
struct eventpoll *ep;
bool locked;
pt->_key = epi->event.events;
if (!is_file_epoll(epi->ffd.file)) {
// 非 epoll fd,tcp_poll 检查 socket 就绪事件,fd 关联回调函数 ep_poll_callback。
return vfs_poll(epi->ffd.file, pt) & epi->event.events;
} else {
// epoll 嵌套。epoll_ctl 添加关注了另外一个 epoll 的 fd(epfd)。
ep = epi->ffd.file->private_data;
poll_wait(epi->ffd.file, &ep->poll_wait, pt);
locked = pt && (pt->_qproc == ep_ptable_queue_proc);
return ep_scan_ready_list(epi->ffd.file->private_data,
ep_read_events_proc, &depth, depth, locked) &
epi->event.events;
}
}
// vfs - Virtual Filesystem Switch(Linux 虚拟文件系统)
// poll.h 就绪事件处理函数。
static inline __poll_t vfs_poll(struct file *file, struct poll_table_struct *pt) {
if (unlikely(!file->f_op->poll))
return DEFAULT_POLLMASK;
// 这里的 poll 函数指针指向 tcp_poll 函数。
return file->f_op->poll(file, pt);
}
// tcp.c
// tcp 就绪事件获取函数。
__poll_t tcp_poll(struct file *file, struct socket *sock, poll_table *wait) {
__poll_t mask;
struct sock *sk = sock->sk;
const struct tcp_sock *tp = tcp_sk(sk);
int state;
/* 添加等待队列和关联事件回调函数 ep_poll_callback
*(只有 epoll_ctl EPOLL_CTL_ADD 的情况下,才会添加等待事件,否则 wait == NULL)*/
sock_poll_wait(file, sock, wait);
// 检查 fd 是否有事件发生。
state = inet_sk_state_load(sk);
if (state == TCP_LISTEN)
return inet_csk_listen_poll(sk);
...
}
// socket.h
static inline void sock_poll_wait(struct file *filp, struct socket *sock, poll_table *p) {
// ep_insert 调用 ep_item_poll 才会插入等待事件。
if (!poll_does_not_wait(p)) {
poll_wait(filp, &sock->wq.wait, p);
...
}
}
// poll.h
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p) {
if (p && p->_qproc && wait_address)
// _qproc ---> ep_ptable_queue_proc
p->_qproc(filp, wait_address, p);
}
8.5. ep_ptable_queue_proc
socket 的等待队列关联回调函数 ep_poll_callback
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead, poll_table *pt) {
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
// 关联等待队列和ep_poll_callback。
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
// whead ---> socket->wq.wait
pwq->whead = whead;
pwq->base = epi;
/* 等待事件,添加到等待队列。EPOLLEXCLUSIVE 为了解决 epoll_wait 惊群问题。
* 如果多线程同时调用 epoll_wait,那么 fd 应该设置 EPOLLEXCLUSIVE 事件。 */
if (epi->event.events & EPOLLEXCLUSIVE) {
add_wait_queue_exclusive(whead, &pwq->wait);
} else {
add_wait_queue(whead, &pwq->wait);
}
/* 等待事件,关联 epitem。epitem 为什么要有一个等待队列呢,
* 因为有可能一个进程里存在多个 epoll 实例同时 epoll_ctl 关注一个 fd。*/
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
8.6. epoll_wait
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout) {
return do_epoll_wait(epfd, events, maxevents, timeout);
}
static int do_epoll_wait(int epfd, struct epoll_event __user *events,
int maxevents, int timeout) {
...
// timeout 阻塞等待处理并返回就绪事件。
error = ep_poll(ep, events, maxevents, timeout);
...
}
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout) {
int res = 0, eavail, timed_out = 0;
u64 slack = 0;
bool waiter = false;
wait_queue_entry_t wait;
ktime_t expires, *to = NULL;
// 计算 timeout 睡眠时间。如果有就绪事件,处理并发送到用户空间。
...
fetch_events:
if (!ep_events_available(ep))
// napi 中断缓解技术,避免网卡频繁中断 cpu,提高数据获取的效率。这里为了积攒网络数据进行返回。
ep_busy_loop(ep, timed_out);
// 检查就绪队列是否有数据。
eavail = ep_events_available(ep);
if (eavail)
// 如果有就绪事件了,就直接不用睡眠等待了,进入发送环节。
goto send_events;
...
// 没有就绪事件发生,需要睡眠等待。
if (!waiter) {
waiter = true;
// 等待事件,关联当前进程。
init_waitqueue_entry(&wait, current);
spin_lock_irq(&ep->wq.lock);
// 添加等待事件。(为了解决惊群效应,所以等待事件添加了 WQ_FLAG_EXCLUSIVE 标识。查看 __wake_up_common 实现。)
__add_wait_queue_exclusive(&ep->wq, &wait);
spin_unlock_irq(&ep->wq.lock);
}
for (;;) {
/*
* We don't want to sleep if the ep_poll_callback() sends us
* a wakeup in between. That's why we set the task state
* to TASK_INTERRUPTIBLE before doing the checks.
*/
// 设置当前进程状态为等待状态,可以被信号解除等待。
set_current_state(TASK_INTERRUPTIBLE);
/*
* Always short-circuit for fatal signals to allow
* threads to make a timely exit without the chance of
* finding more events available and fetching
* repeatedly.
*/
// 信号中断,不要执行睡眠了。
if (fatal_signal_pending(current)) {
res = -EINTR;
break;
}
// 检查就绪队列。
eavail = ep_events_available(ep);
if (eavail)
break;
// 信号中断,不要执行睡眠了。
if (signal_pending(current)) {
res = -EINTR;
break;
}
// 进程进入睡眠状态。
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS)) {
timed_out = 1;
break;
}
}
// 进程等待超时,或者被唤醒,设置进程进入运行状态,等待内核调度运行。
__set_current_state(TASK_RUNNING);
send_events:
/*
* Try to transfer events to user space. In case we get 0 events and
* there's still timeout left over, we go trying again in search of
* more luck.
*/
// 有就绪事件就发送到用户空间,否则继续获取数据直到超时。
if (!res && eavail && !(res = ep_send_events(ep, events, maxevents)) &&
!timed_out)
goto fetch_events;
// 从等待队列中,删除等待事件。
if (waiter) {
spin_lock_irq(&ep->wq.lock);
__remove_wait_queue(&ep->wq, &wait);
spin_unlock_irq(&ep->wq.lock);
}
return res;
}
/* Used by the ep_send_events() function as callback private data */
struct ep_send_events_data {
int maxevents;
struct epoll_event __user *events;
int res;
};
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents) {
struct ep_send_events_data esed;
esed.maxevents = maxevents;
esed.events = events;
// 遍历事件就绪列表,发送就绪事件到用户空间。
ep_scan_ready_list(ep, ep_send_events_proc, &esed, 0, false);
return esed.res;
}
8.7. ep_scan_ready_list
遍历就绪列表,处理 sproc 函数。这里 sproc 函数指针的使用,是为了减少代码冗余,将 ep_scan_ready_list 做成一个通用的函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
//
static __poll_t ep_scan_ready_list(struct eventpoll *ep,
__poll_t (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv, int depth, bool ep_locked) {
__poll_t res;
struct epitem *epi, *nepi;
LIST_HEAD(txlist);
...
// 将就绪队列分片链接到 txlist 链表中。
list_splice_init(&ep->rdllist, &txlist);
res = (*sproc)(ep, &txlist, priv);
...
// 在处理 sproc 回调处理过程中,可能产生新的就绪事件被写入 ovflist,将 ovflist 回写 rdllist。
for (nepi = READ_ONCE(ep->ovflist); (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
if (!ep_is_linked(epi)) {
list_add(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
...
// txlist 在 epitem 回调中,可能没有完全处理完,那么重新放回到 rdllist,下次处理。
list_splice(&txlist, &ep->rdllist);
...
}
8.8. ep_send_events_proc
处理就绪列表,将数据从内核空间拷贝到用户空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head, void *priv) {
struct ep_send_events_data *esed = priv;
__poll_t revents;
struct epitem *epi, *tmp;
struct epoll_event __user *uevent = esed->events;
struct wakeup_source *ws;
poll_table pt;
init_poll_funcptr(&pt, NULL);
...
// 遍历处理 txlist(原 ep->rdllist 数据)就绪队列结点,获取事件拷贝到用户空间。
list_for_each_entry_safe (epi, tmp, head, rdllink) {
if (esed->res >= esed->maxevents)
break;
...
// 先从就绪队列中删除 epi,如果是 LT 模式,就绪事件还没处理完,再把它添加回去。
list_del_init(&epi->rdllink);
// 获取 epi 对应 fd 的就绪事件。
revents = ep_item_poll(epi, &pt, 1);
if (!revents)
// 如果没有就绪事件就返回(这时候,epi 已经从就绪列表中删除了。)
continue;
// 内核空间向用户空间传递数据。__put_user 成功拷贝返回 0。
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
// 如果拷贝失败,继续保存在就绪列表里。
list_add(&epi->rdllink, head);
ep_pm_stay_awake(epi);
if (!esed->res)
esed->res = -EFAULT;
return 0;
}
// 成功处理就绪事件的 fd 个数。
esed->res++;
uevent++;
if (epi->event.events & EPOLLONESHOT)
// #define EP_PRIVATE_BITS (EPOLLWAKEUP | EPOLLONESHOT | EPOLLET | EPOLLEXCLUSIVE)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) {
/*
* If this file has been added with Level
* Trigger mode, we need to insert back inside
* the ready list, so that the next call to
* epoll_wait() will check again the events
* availability. At this point, no one can insert
* into ep->rdllist besides us. The epoll_ctl()
* callers are locked out by
* ep_scan_ready_list() holding "mtx" and the
* poll callback will queue them in ep->ovflist.
*/
/* lt 模式下,当前事件被处理完后,不会从就绪列表中删除,留待下一次 epoll_wait
* 调用,再查看是否还有事件没处理,如果没有事件了就从就绪列表中删除。
* 在遍历事件的过程中,不能写 ep->rdllist,因为已经上锁,只能把新的就绪信息
* 添加到 ep->ovflist */
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
return 0;
}
8.9. ep_poll_callback
fd 事件回调。当 fd 有网络事件发生,就会通过等待队列,进行回调。参考 __wake_up_common,如果事件是用户关注的事件,回调会唤醒进程进行处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key) {
int pwake = 0;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
__poll_t pollflags = key_to_poll(key);
unsigned long flags;
int ewake = 0;
// 禁止本地中断并获得指定读锁。
read_lock_irqsave(&ep->lock, flags);
ep_set_busy_poll_napi_id(epi);
// #define EP_PRIVATE_BITS (EPOLLWAKEUP | EPOLLONESHOT | EPOLLET | EPOLLEXCLUSIVE)
// 如果 fd 没有关注除了 EP_PRIVATE_BITS 之外的事件,那么走解锁流程。
if (!(epi->event.events & ~EP_PRIVATE_BITS))
goto out_unlock;
// 如果回调的事件,不是用户关注的 fd 事件,那么走解锁流程。
if (pollflags && !(pollflags & epi->event.events))
goto out_unlock;
/*
* If we are transferring events to userspace, we can hold no locks
* (because we're accessing user memory, and because of linux f_op->poll()
* semantics). All the events that happen during that period of time are
* chained in ep->ovflist and requeued later on.
*/
// 当内核空间向用户空间拷贝数据时,不添加 epi 到 rdllist,将它添加到 ovflist。
if (READ_ONCE(ep->ovflist) != EP_UNACTIVE_PTR) {
if (epi->next == EP_UNACTIVE_PTR && chain_epi_lockless(epi))
ep_pm_stay_awake_rcu(epi);
goto out_unlock;
}
// epi 已经加入就绪链表就不需要添加了。
if (!ep_is_linked(epi) &&
list_add_tail_lockless(&epi->rdllink, &ep->rdllist)) {
ep_pm_stay_awake_rcu(epi);
}
// 当回调事件是用户关注的事件,那么需要唤醒进程处理。
// ep->wq 在 epoll_wait 时添加,当没有就绪事件,epoll_wait 进行睡眠等待唤醒。
if (waitqueue_active(&ep->wq)) {
if ((epi->event.events & EPOLLEXCLUSIVE) &&
!(pollflags & POLLFREE)) {
// #define EPOLLINOUT_BITS (EPOLLIN | EPOLLOUT)
switch (pollflags & EPOLLINOUT_BITS) {
case EPOLLIN:
if (epi->event.events & EPOLLIN)
ewake = 1;
break;
case EPOLLOUT:
if (epi->event.events & EPOLLOUT)
ewake = 1;
break;
case 0:
ewake = 1;
break;
}
}
wake_up(&ep->wq);
}
// ep->poll_wait 是 epoll 监控另外一个 epoll fd 的等待队列。如果触发事件,也需要唤醒进程处理。
if (waitqueue_active(&ep->poll_wait))
pwake++;
out_unlock:
read_unlock_irqrestore(&ep->lock, flags);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
if (!(epi->event.events & EPOLLEXCLUSIVE))
ewake = 1;
if (pollflags & POLLFREE) {
/*
* If we race with ep_remove_wait_queue() it can miss
* ->whead = NULL and do another remove_wait_queue() after
* us, so we can't use __remove_wait_queue().
*/
list_del_init(&wait->entry);
/*
* ->whead != NULL protects us from the race with ep_free()
* or ep_remove(), ep_remove_wait_queue() takes whead->lock
* held by the caller. Once we nullify it, nothing protects
* ep/epi or even wait.
*/
smp_store_release(&ep_pwq_from_wait(wait)->whead, NULL);
}
return ewake;
}
9. 参考
- vscode + gdb 远程调试 linux (EPOLL) 内核源码
- Linux下的I/O复用与epoll详解
- epoll实现探究
- Buddy memory allocation (伙伴内存分配器)
- Linux内存管理,内存寻址
- EPOLL内核原理极简图文解读
- 彻底理解epoll
- 《UNIX 环境高级编程》3.2 文件描述符
- Linux内核空间内存申请函数kmalloc、kzalloc、vmalloc的区别
- Linux内核笔记–深入理解文件描述符
- epoll_ctl 文档
- epoll的原理过程讲解
- socket—proto_ops—inetsw_array等基本结构
- epoll高效IO复用
- Epoll技术扩展
- Linux网络包收发总体过程
- epoll源码分析
- TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE
- NAPI(New API)的一些浅见
- NAPI 技术在 Linux 网络驱动上的应用和完善
- EPOLL 源码分析
- 用户空间和内核空间传递数据
- 《Linux内核设计与实现》读书笔记(十)- 内核同步方法
- 虚拟文件系统VFS
- epoll用法【整理】
- 再谈Linux epoll惊群问题的原因和解决方案
- 从linux源码看epoll

