即时通讯,消息有多种类型,单聊,群聊等等。
群组聊天消息管理比较麻烦,因为涉及到多个用户,尤其是千人群组,1 个人发送消息,999 个人接收,数据库针对每个用户存储一条记录吗?这个量级的数据存储是十分恐怖的,所以消息的存储策略显得十分重要。
1. 消息时序
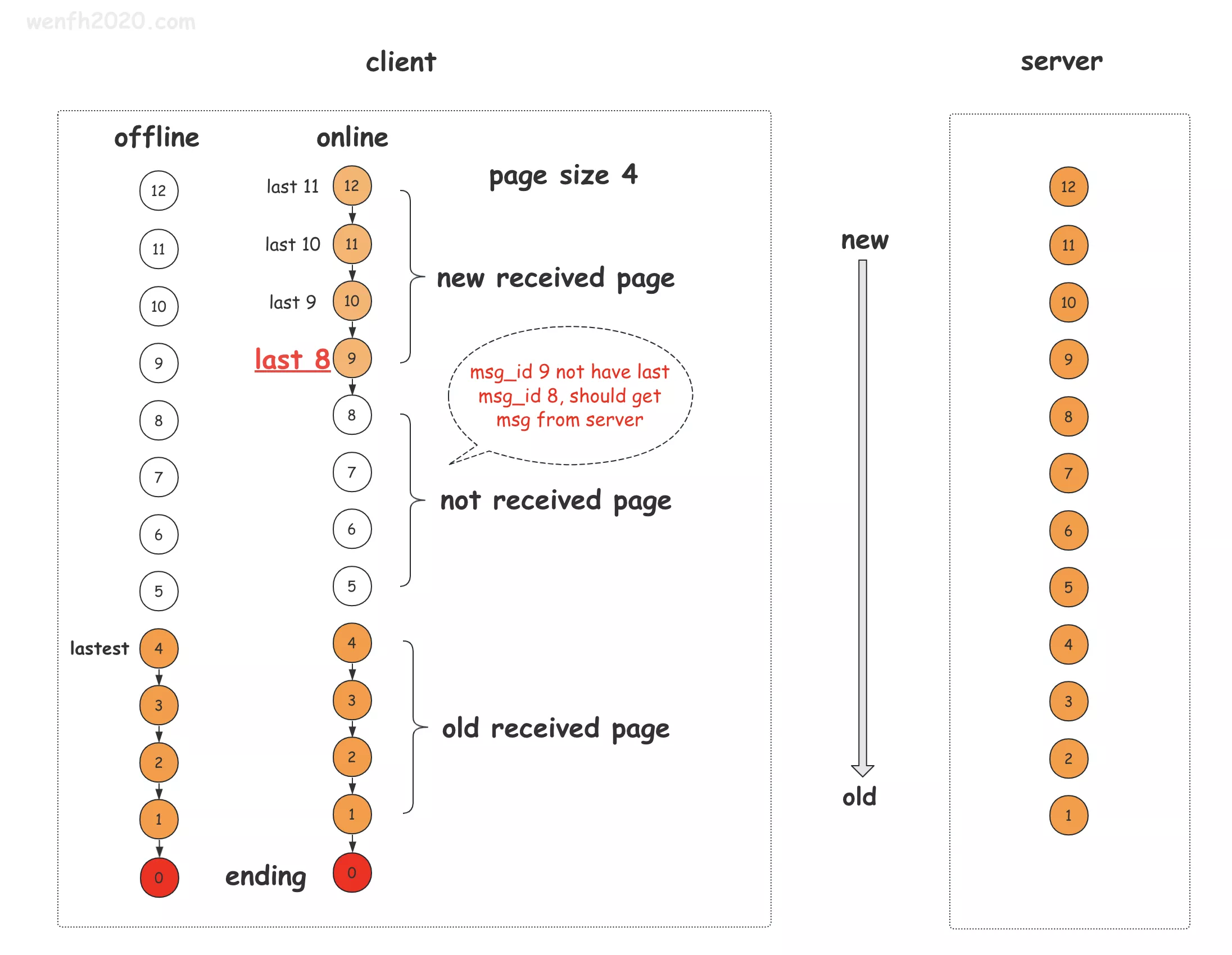
理想状态下,客户端和服务端数据是一致的。实际情况,涉及到用户上线或下线。(详见下图)
- 用户在线:服务实时发送消息。
- 用户离线:服务保存消息;用户重新上线后,向服务获取离线消息。
设计图来源:《即时通讯(IM)- 千人群组消息管理》
-
群组离线消息数据分页链式管理。
如上图,每条消息都是有时序的,像链表一样,串联起来,每个 node 都可以通过 next 指向上一条消息:
- 如果上一条消息 msg_id 是 0,说明当前结点是第一条消息(如上图 msg_id == 1 的消息)。
- 如果上一条消息 msg_id 不是 0,且消息存在于本地,那么消息是连续的,不需要向服务同步(如上图 msg_id == 2 的消息)。
- 如果上一条消息 msg_id 不是 0,但本地消息不存在,那么需要向服务器获取。(如上图 msg_id == 9 的消息)。
终端通过消息链表方式的检查,很容易确认是否需要向服务同步数据。
-
群组未读消息总条数。
从 client 的缓存中提取最新(lastest)的 msg_id,对应消息体有 recv_time。
服务端消息的时序通过 redis 的 sortset 存储的,redis 的 sortset 结构,很容易通过一个 score 获取一个区间的数据总数。
1
key: group_id, score: recv_time, value: msg_id
2. redis 设计
- sortset 存储存储消息时序。
1
key: group_id, score: recv_time, value: msg_id
-
string 存储消息体。
因为消息体数量较多,而且活跃时间比较短(因为大部分用户只关心最近接收的消息),所以把它独立出来。便于 timeout 后 redis 能删除节省内存。
1
key: msg_id, value: msg_body
-
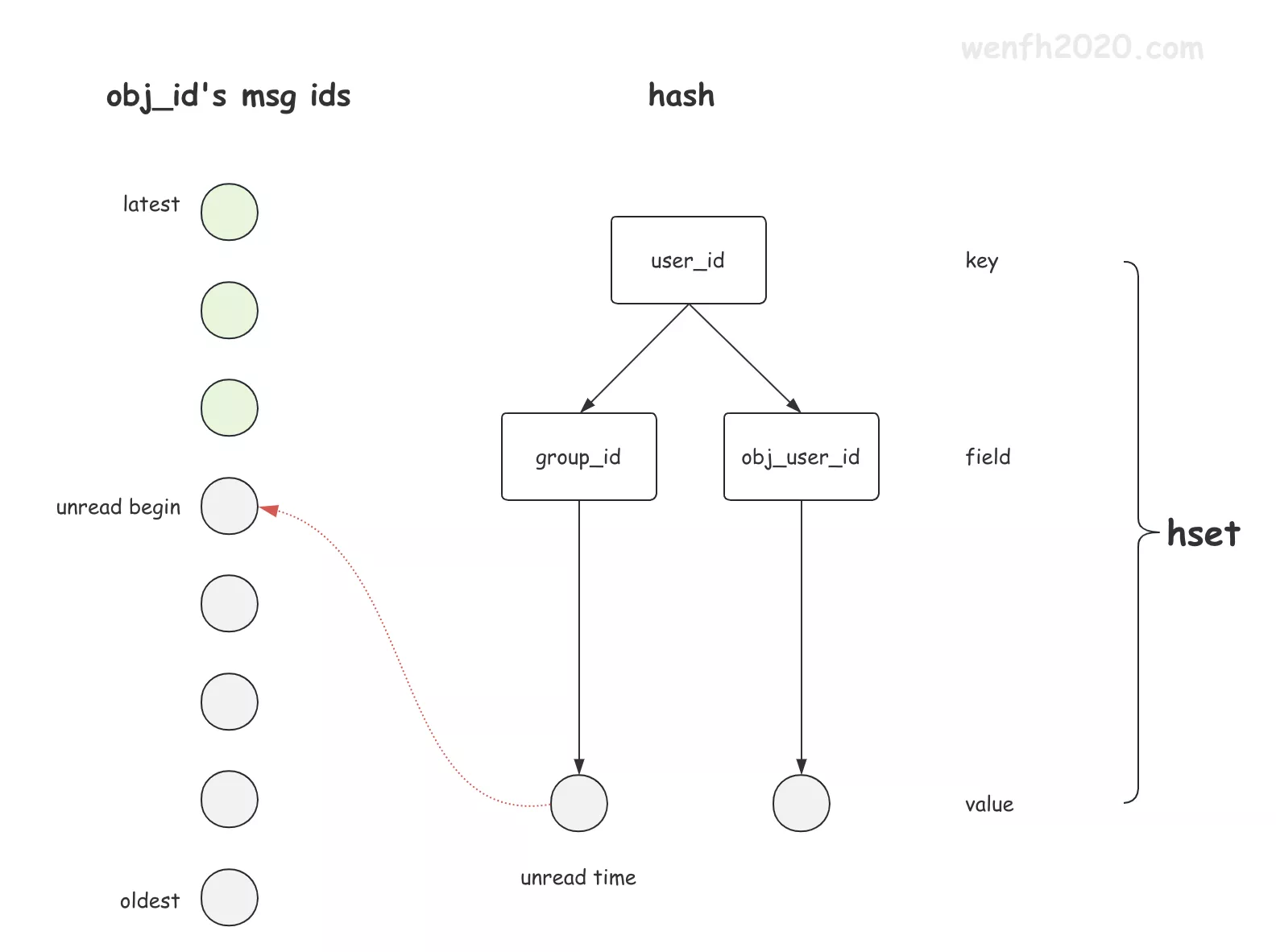
hash 存储未读消息对象。
每个用户都可能有 N 个群组,N 个好友。用户重新上线后,不可能遍历所有好友或群组对象。所以服务在处理离线消息时,需要记录未读消息对象。为避免某些用户长久不上线,导致存储数据积压,使用 hash 进行存储。value 保存某个对象第一条未读消息的时间戳,知道了起始时间,就能从 redis 或者 mysql 里读取某个时间到当前时间段内的所有数据。
1
key: uid, filed: obj_id(group_id/send_uid), value: msg_id/time_stamp
3. database 设计
- 群组和群组成员关系
1
group_id, uid
- 消息结构
1
msg_id, group_id, send_uid, recv_uid, recv_time, msg_body
4. 服务存储架构
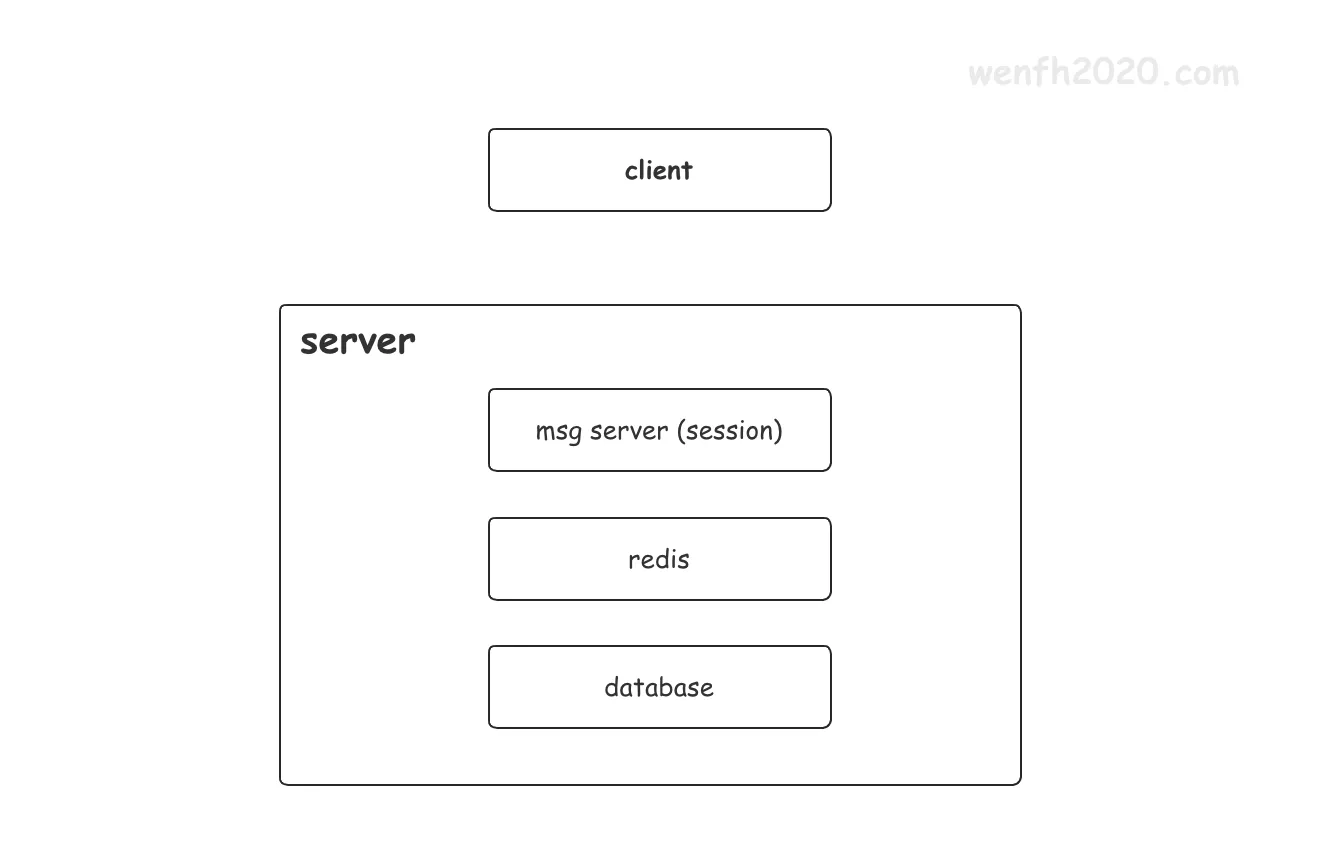
即时通讯服务是读多写少类型。服务端有三层存储(如下图),通过热点数据的缓存,让服务高效读取。
-
msg server服务进程内存session缓存热点数据。
缓存当前活跃的数据:头像信息,用户名称,消息实体等数据,缓存一般 5 - 30 分钟,根据具体的业务需要 -
redis 第二层缓存热点数据。
缓存大量的热点数据,减少对 db 的访问频率,缓存时间相对较长,几个月不等。 -
database 数据落地。
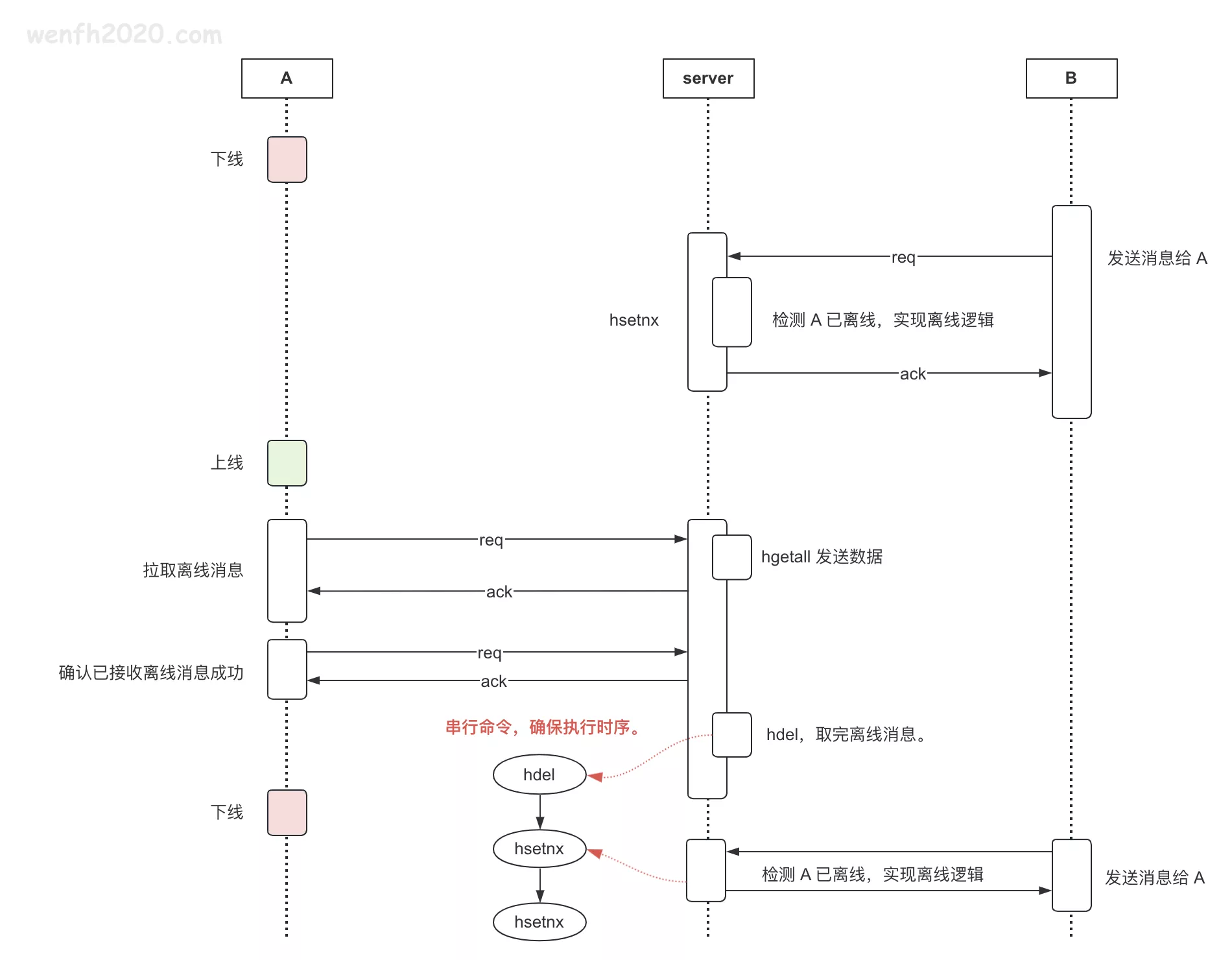
5. 数据读写时序
5.1. 写数据
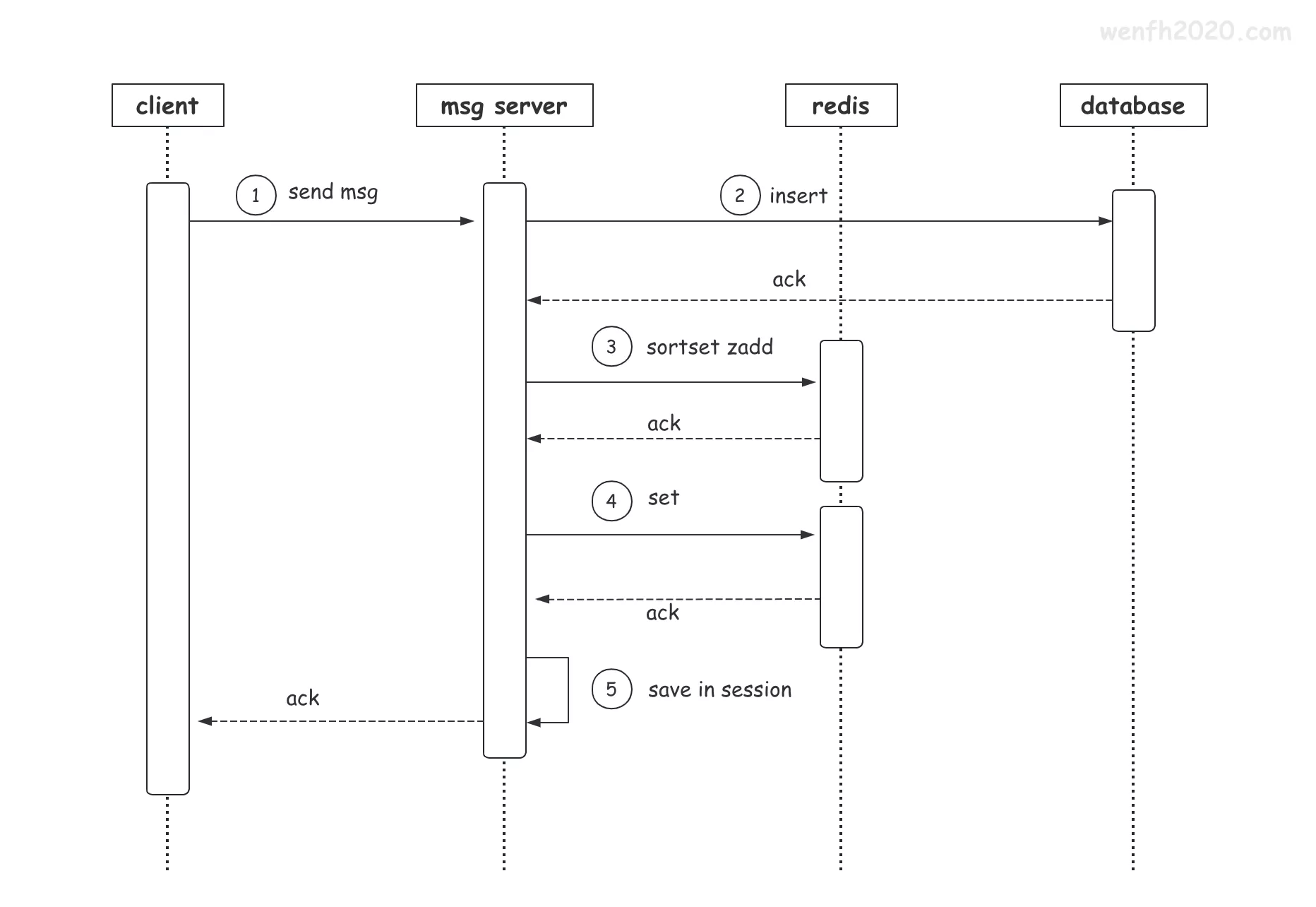
5.2. 读数据
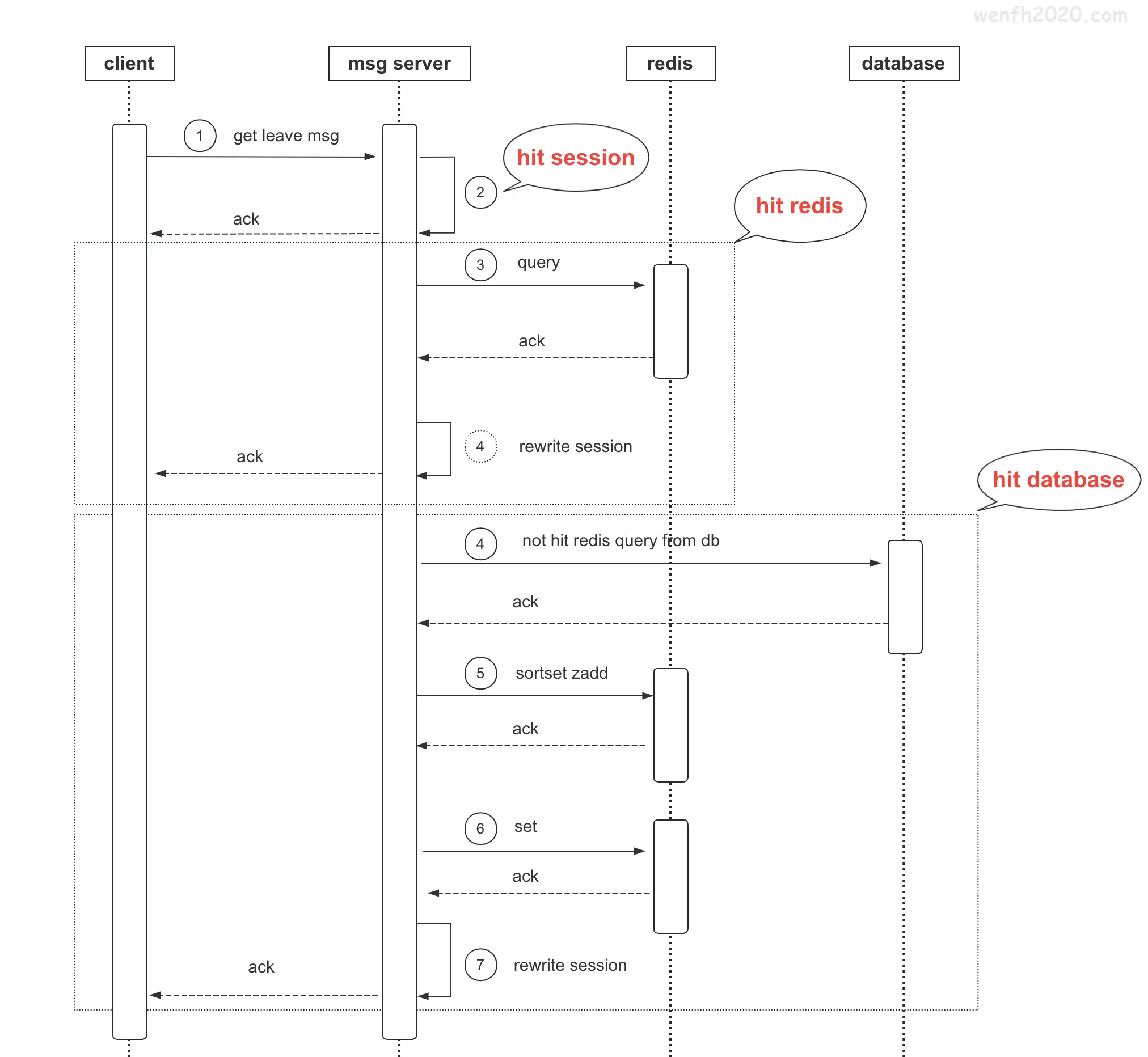
6. redis 故障
因为 redis 主从数据并非强一致,所以 redis master 故障转移过程中可能会丢数据。
解决方案:用户没有接收到群组消息,需要推送,推送数据写消息队列,延时推送,推送过程中重新检查 redis 数据进行重写。
7. 总结
基于以上分析,群组消息,每个用户发送的消息,不需要针对每个群组成员存一条记录到数据库,数据库只需要存一条记录即可。通过多级缓存的架构,服务的性能一般体量的消息实时通讯是没有问题的。当然这里面还有很多细节问题需要在实际的业务场景中调优。

